Secondo Gartner, la scarsa qualità dei dati costa alle aziende una media di 12,9 milioni di dollari ogni anno. Si tratta di una cifra impressionante, ma non sorprendente, se si considera che i dati di bassa qualità portano ad analisi imprecise e a decisioni sbagliate.
Le pipeline di dati ETL aiutano a migliorare la qualità dei dati. Aiutano le organizzazioni a risolvere diversi casi d'uso, come la migrazione di cloud , la replica dei database e il data warehousing.
Che cos'è una pipeline di dati ETL?
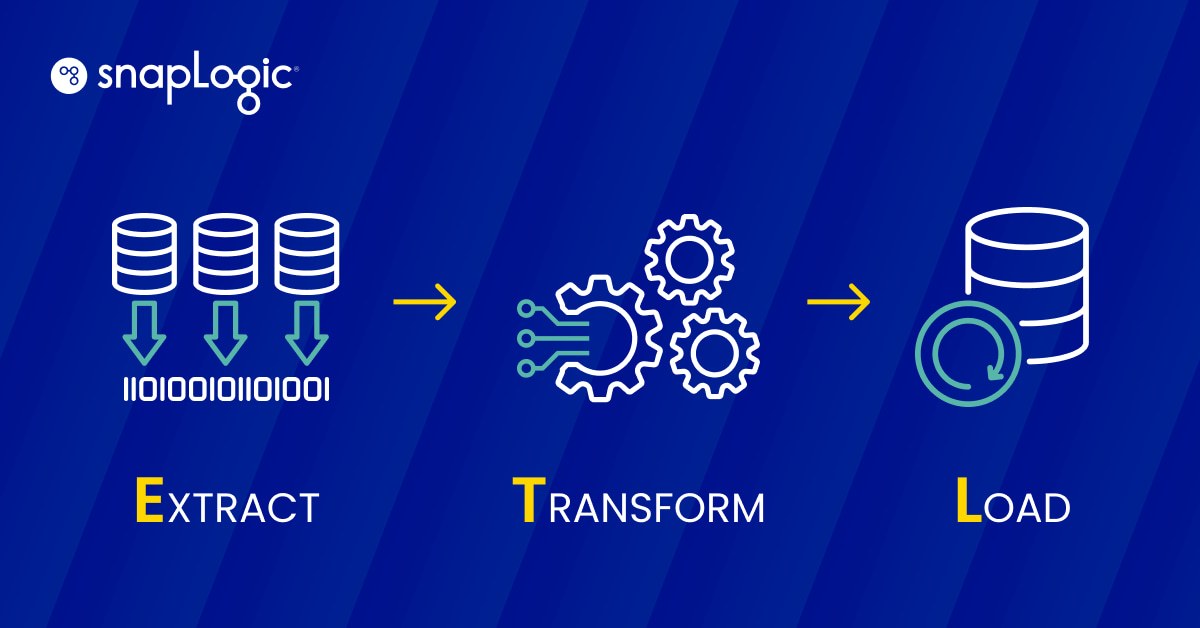
Una pipeline di dati ETL è un processo in tre fasi che consiste nell'estrarre (E) i dati, trasformarli (T) e caricarli (L) in un archivio di dati per essere utilizzati da uno strumento di business intelligence o da un algoritmo di apprendimento automatico.
- Estrazione: I dati strutturati e non strutturati, provenienti da una o più fonti, vengono copiati o spostati in un'area di raccolta.
- Trasformazione: I dati nell'area di staging vengono elaborati per l'uso previsto. L'elaborazione dei dati può comprendere la pulizia, il filtraggio, la deduplicazione, la conversione, la crittografia e molti altri processi, a seconda del caso d'uso.
- Caricamento: I dati trasformati vengono caricati in un magazzino.
I casi d'uso dell'ETL variano da semplici a molto complessi.
Ad esempio, un negozio con più sedi può impostare una pipeline di dati ETL per raccogliere le informazioni sulle vendite da tutte le sedi e inviarle ogni giorno a un repository centrale. Si tratta di un esempio relativamente semplice rispetto a quello di Netflix.
Netflix si affida al processo ETL per supportare la sua infrastruttura di dati in tempo reale. L'ETL aiuta Netflix a elaborare i dati che vengono poi utilizzati per fornire raccomandazioni altamente personalizzate ai suoi abbonati. Fino al 2015, l'azienda si affidava all'elaborazione batch per gestire i propri dati. I dati generati dai processi interni, così come i dati degli utenti, scorrevano attraverso pipeline ETL convenzionali e finivano negli archivi di dati.
Ma Netflix stava crescendo a ritmi elevati e l'elaborazione batch non era una soluzione sostenibile. L'azienda generava più di 10PB di dati al giorno e prevedeva di generarne ancora di più, quindi è passata all'integrazione dei dati in flusso, che è un altro tipo di ETL. Netflix ha costruito Keystone, una piattaforma dati per gestire flussi di dati in tempo reale per casi d'uso analitici, e Mantis, una piattaforma simile per gestire casi d'uso operativi.
Il passaggio dall'elaborazione batch all'elaborazione in flusso è stato iterativo: Netflix ha impiegato cinque anni per passare completamente a un modello di elaborazione in flusso. Oltre a fornire raccomandazioni personalizzate, le pipeline ETL aiutano l'azienda a migliorare l'efficienza operativa.
ETL vs. altre pipeline di dati: quali sono le differenze?
Una pipeline di dati ETL è un tipo di pipeline di dati, ma non tutte le pipeline di dati sono ETL. Una pipeline di dati è un processo in cui un programma software prende i dati da un'origine e li invia a una destinazione. Alcuni altri tipi di pipeline di dati oltre all'ETL sono:
ELT
Una pipeline ELT è come l'ETL, ma i dati vengono caricati in un archivio dati prima del processo di trasformazione. Le pipeline ELT sono utilizzate per gestire grandi volumi di dati non strutturati per i casi di apprendimento automatico.
Acquisizione dei dati di modifica (CDC)
Il CDC è un tipo di pipeline di dati in cui un programma software tiene traccia di tutte le modifiche apportate ai dati di un database e le trasmette a un altro sistema in tempo reale. Il CDC viene utilizzato per la sincronizzazione dei dati e per la creazione di registri di controllo.
Replica dei dati
La replica dei dati è il processo di copia continua dei dati da un'origine e di salvataggio su più altre fonti da utilizzare come backup. La replica dei dati viene utilizzata anche per trasferire i dati di produzione ai data warehouse operativi per l'analisi.
Virtualizzazione dei dati
La virtualizzazione dei dati è il processo di integrazione di tutte le fonti di dati all'interno di un'organizzazione, in modo che gli utenti possano accedere a tali dati attraverso un cruscotto. La virtualizzazione dei dati viene utilizzata per creare dashboard e report per la conformità alle normative, la gestione della supply chain e la business intelligence.
Quali sono i vantaggi di una pipeline di dati ETL?
Le pipeline di dati ETL offrono un controllo completo sulla gestione dei dati nella vostra organizzazione. Potete:
- Accedere a dati puliti e precisi per l'analisi e sbarazzarsi di record imprecisi, duplicati e incompleti al momento della trasformazione dei dati.
- Tracciare facilmente il percorso dei dati, facilitando l'implementazione di un quadro di governance dei dati e il monitoraggio del flusso di dati nelle diverse pipeline all'interno dell'organizzazione.
- Migliorare l'efficienza dell'elaborazione dei dati all'interno dell'organizzazione attraverso l'automazione.
- Visualizzare le architetture di dati che utilizzano le pipeline di dati ETL. Creando questi diagrammi, è possibile comprendere il flusso dei dati e pianificare le modifiche alla pipeline quando necessario.
Le pipeline di dati ETL sono facili da configurare, soprattutto grazie agli strumenti di integrazione dei dati. Questi strumenti sono per lo più disponibili attraverso piattaforme low-code e no-code, dove è possibile utilizzare un'interfaccia grafica (GUI) per costruire pipeline di dati ETL e automatizzare il flusso di dati nell'organizzazione.
Tipi di pipeline di dati ETL
Le pipeline di dati ETL sono di tre tipi. Questa classificazione si basa sul modo in cui gli strumenti di estrazione dei dati estraggono i dati dall'origine.
Elaborazione in batch
In questo tipo di pipeline di dati ETL, i dati vengono estratti in lotti. Lo sviluppatore imposta una sincronizzazione periodica tra le sorgenti di dati e l'ambiente di staging e i dati vengono estratti in base alla pianificazione. Ciò significa che il carico del server aumenta solo al momento della sincronizzazione. Alcuni dei casi d'uso dell'elaborazione in batch sono:
- Piccole e medie organizzazioni: Le piccole e medie organizzazioni lavorano con risorse limitate e non gestiscono grandi volumi di dati. L'elaborazione batch consente loro di gestire in modo efficiente il carico del server al momento della sincronizzazione e di lavorare nell'ambito delle proprie risorse per gestire i dati.
- Dati sparsi in più database dell'organizzazione: Se l'organizzazione dispone di molti database e i dati sono distribuiti in più posizioni su server on-premises, è meglio creare più pipeline di dati ETL in batch che si sincronizzano con l'archivio dati centrale in momenti diversi della giornata.
- I dati non arrivano sotto forma di flussi: Se non si generano dati sotto forma di flussi, è meglio utilizzare pipeline di dati ETL batch perché consumano meno risorse.
- Gli analisti hanno esigenze limitate: Se i vostri analisti di dati non hanno bisogno di dati freschi o di accedere all'intero set di dati quando eseguono analisi diverse, l'elaborazione batch è adatta a voi.
Integrazione dei dati di flusso (SDI)
In SDI, lo strumento di estrazione dei dati estrae continuamente i dati dalle fonti e li invia a un ambiente di staging. Questa pipeline di dati ETL è utile quando:
- È necessario elaborare grandi insiemi di dati: Le organizzazioni che lavorano con grandi volumi di dati che devono essere continuamente estratti, trasformati e caricati possono trarre vantaggio dall'elaborazione dei flussi.
- I dati vengono generati sotto forma di flussi: Qualsiasi organizzazione in cui i dati vengono generati continuamente sotto forma di flussi può trarre vantaggio dalla SDI. Ad esempio, YouTube ha milioni di utenti che guardano video e generano dati contemporaneamente. L'SDI può aiutare a trasferire questi dati agli archivi di dati in tempo reale.
- L'accesso ai dati in tempo reale è fondamentale: I sistemi di rilevamento delle frodi bloccano i malintenzionati e non permettono loro di effettuare transazioni in tempo reale. Questo perché monitorano i dati in tempo reale. L'SDI è utile in questi casi d'uso.
Come creare una pipeline di dati ETL tradizionale con puro Python
Quando si crea una pipeline di dati ETL tradizionale con Python, lo snippet di codice sarebbe simile a questo (Python puro con Pandas; non si tratta di un esempio pronto per la produzione).
| import os from sqlalchemy import create_engine import pandas as pd # Extract data data = pd.read_csv(‘data.csv’) # Transform data data = data.dropna() # remove missing values data = data.rename(columns={‘old_name’: ‘new_name’}) # rename columns data = data.astype({‘column_name’: ‘int64’}) # convert data type # Load data db_url = os.environ.get(‘DB_URL’) engine = create_engine(db_url) data.to_sql(‘table_name’, engine, if_exists=’append’) |
In questo esempio, noi:
- Estrarre i dati da un file CSV.
- Trasformatelo eliminando i valori mancanti, rinominando le colonne e convertendo i tipi di dati.
- Caricarlo in una tabella del database SQL.
Questo è solo un esempio di scrittura manuale del codice: i passaggi specifici e le librerie da utilizzare dipendono dall'origine e dalla destinazione dei dati, nonché dalle trasformazioni specifiche richieste. Snap
Come semplificare le pipeline di dati con SnapLogic
Lo snippet di cui sopra è un esempio molto elementare di ETL. Per trasformazioni più complesse, l'esempio di codifica manuale sarebbe molto più complesso. Inoltre, la codifica manuale richiede una manutenzione dispendiosa in termini di tempo, che sottrae preziosa produttività agli uffici di data engineering e data warehouse.
Invece di codificare manualmente, create pipeline di dati con l'approccio visivo e l'interfaccia grafica di SnapLogic. Con SnapLogic è possibile creare pipeline di dati basate su ETL, ELT, batch o streaming. Seguite questi passaggi per un approccio senza codice a SnapLogic:
- Cercate un modello esistente, tra centinaia, nell'area Patterns di SnapLogic che soddisfi la vostra origine dati (database, file, dati web), la destinazione dati e i requisiti funzionali.
- Copiare il modello nell'area di disegno di SnapLogic Designer.
- In SnapLogic Designer, modificare il modello SnapLogic per adattarlo alle specifiche esigenze di configurazione.
- In alternativa, si può partire da un canvas vuoto di SnapLogic Designer e selezionare l'origine dati necessaria tra le centinaia di SnapLogic Snap precostituiti e trascinare lo Snap sul canvas.
- Lasciate che SnapLogic Iris, un assistente all'integrazione guidato dall'intelligenza artificiale, vi guidi attraverso i passi successivi nella costruzione della vostra pipeline (se inserite un punto di partenza, un punto di arrivo e un punto intermedio nella vostra tela, SnapLogic può consigliarvi una pipeline di dati completa basata su modelli simili).
Per una comprensione più approfondita dei modi moderni, guidati dall'intelligenza artificiale, di creare ed eseguire pipeline di dati in modo no-code o low-code, leggete l'approccio di SnapLogic all'ETL.