





Che cos'è Apache Hive? Hive fornisce un meccanismo per interrogare, creare e gestire grandi insiemi di dati memorizzati su Hadoop, utilizzando istruzioni simili a SQL. Consente inoltre di aggiungere una struttura ai dati esistenti che risiedono su HDFS. In questo post descriverò un approccio pratico su come inserire i dati in Hive, con SnapLogic Elastic Integration Platform, senza la necessità di scrivere codice.
Le pipeline di flusso di dati, chiamate anche pipeline SnapLogic, vengono create in un designer visivo molto intuitivo, utilizzando un approccio drag & drop. Una pipeline di flusso di dati è costituita da uno o più snap che vengono collegati per orchestrare il flusso di integrazione dei dati aziendali tra sorgenti e destinazioni. Gli snap sono gli elementi costitutivi di una pipeline che eseguono una singola funzione, come leggere, scrivere o agire sui dati. Gli snap di SnapLogic supportano la lettura e la scrittura di vari formati, tra cui CSV, AVRO, Parquet, RCFile, ORCFile, testo delimitato e JSON. Gli schemi di compressione supportati includono LZO, Snappy, gzip.
Ecco uno scenario: Supponiamo di avere dati di contatto ottenuti da più fonti che devono essere inseriti in Hive. Dobbiamo combinare i dati provenienti da più fonti: ad esempio, file grezzi su HDFS, dati su S3 (AWS), dati da database e dati da applicazioni cloud come Salesforce o Workday. Come si può iniziare a inserire in Hive i dati provenienti da queste fonti diverse?
Il primo passo è la creazione di un database e/o di tabelle Hive. Utilizzando SnapLogic Hive Integration Snap, è possibile eseguire qualsiasi DML/DDL di Hive, compresa la creazione di database e tabelle.
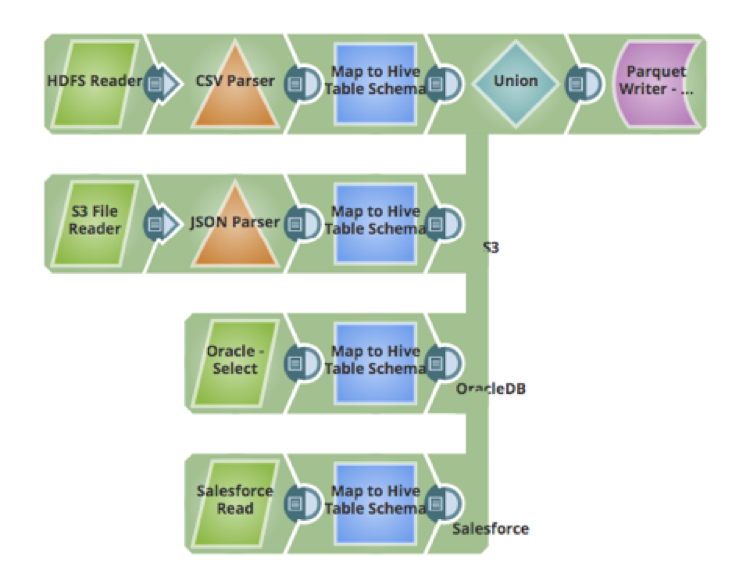
Il passo successivo riguarda l'inserimento dei dati. Una delle sfide che si presentano quando si ingeriscono dati da più fonti è come mappare, trasformare e pulire i dati. Utilizzando lo snap Mapper, è possibile mappare i campi dallo schema di origine allo schema di destinazione, pulire i dati, eseguire trasformazioni sui dati, aggiungere nuovi attributi allo schema e altre azioni. Di seguito è riportata una pipeline che riceve i dati da 4 fonti, li trasforma per mapparli nella tabella Hive e li inserisce nella tabella Hive (che utilizza il formato dati Parquet):
- File di dati grezzi CSV su HDFS
- File JSON ospitati su Amazon S3
- Dati da una tabella di un database Oracle
- Dati ospitati in un'applicazione cloud come Salesforce
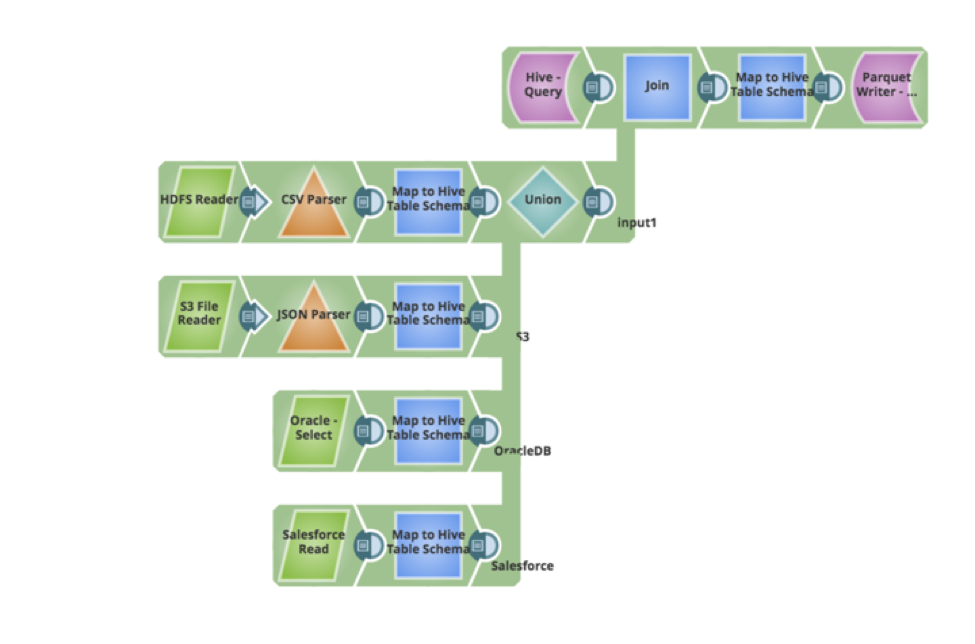
Supponiamo di avere un nuovo requisito da parte degli utenti aziendali, ovvero che i dati esistenti nella tabella Hive debbano essere aggiornati e che debbano essere inseriti nuovi record di dati. La pipeline può essere facilmente aggiornata per interrogare i dati esistenti, eseguire un join esterno completo e scrivere i dati come parquet. Di seguito è riportata la pipeline che ha implementato i nuovi requisiti, il tutto eseguito in modo visuale, senza scrivere alcun codice o script.
Nel prossimo post, analizzerò altri modelli di ingestione e come implementarli con la piattaforma SnapLogic.






