






Si è parlato molto del fatto che i dati sono la nuova moneta. Come ha scritto Rob Versaw, membro del Consiglio tecnologico di Forbes, nel suo post sul blog, "Come implementare la nuova valuta: I dati," "Le aziende con il maggior potenziale di crescita e di conquista di quote di mercato utilizzano i dati in modo più efficiente rispetto ai loro concorrenti".." Il potenziale per ottenere valore aziendale dai dati è assolutamente presente, ma per realizzarlo è fondamentale che i dati si trovino nel posto giusto, al momento giusto e nel formato giusto. È stato dimostrato che il semplice fatto di prendere tutti i dati disponibili e archiviarli in un data lake ha avuto un successo alterno.1 Lo spostamento di applicazioni e dati sul sito cloud è già in atto e continua ad evolversi. L'archiviazione e l'elaborazione dei big data seguiranno sicuramente una tendenza simile. Come possono le aziende prepararsi per un'idratazione dei dati di successo?
Ovviamente, oggi le aziende hanno abbracciato il sito cloud e utilizzano un'ampia serie di applicazioni SaaS in molte linee di business (LoB). Applicazioni come Salesforce, Workday e Zendesk contengono informazioni fondamentali per scoprire i dati aziendali. I dati in streaming dei sensori IoT forniscono informazioni preziose sullo stato di salute delle apparecchiature. Mentre i dati in streaming dei social media forniscono informazioni in tempo reale su come i clienti percepiscono le vostre offerte. Tuttavia, per ottenere il massimo valore aziendale dai dati, è necessario ingerire e combinare i dati provenienti da molte fonti, sia attraverso i fornitori SaaS e le fonti di streaming sopra menzionate, sia attraverso fonti più tradizionali come i dati aziendali (DBMS) in sede. Aumentando le fonti di dati primarie con altre fonti di dati interne ed esterne, le aziende possono sbloccare il potenziale per scoprire nuovi insight.
Toccare il tasto cloud
Insieme al movimento SaaS, l'archiviazione dei dati in cloud è ormai la nuova norma, sia che si utilizzino DBMS in cloud come Snowflake, Amazon Redshift, Microsoft Azure SQL data warehouse, sia che si utilizzi l'archiviazione di oggetti in servizi come Amazon S3, Microsoft WASB, ecc. Cloud Lo storage elimina la necessità per l'IT di creare backup e repliche dei dati, poiché queste attività fanno parte dell'offerta di servizi cloud , riducendo così i costi e la complessità della gestione delle risorse IT. Cloud storage fornisce inoltre un modo economico per archiviare e gestire i dati aziendali, consentendo all'IT aziendale di diventare più agile.
Elaborazione di set di dati complessi
Sebbene Hadoop e HDFS abbiano fornito alle aziende la tecnologia per archiviare ed elaborare grandi e complessi set di dati, questo ambiente richiede un set di competenze specializzate. Inoltre, questi cluster Hadoop sono storicamente sistemi on-premises che richiedono un grande investimento di capitale iniziale per iniziare. I data lake e l'elaborazione dei big data stanno seguendo il movimento di cloud spostandosi su cloud. La prima fase è definita "lift and shift", in cui le aziende spostano semplicemente il cluster Hadoop on-premises su un provider cloud in esecuzione in una rete virtuale, sfruttando i vantaggi di IaaS come il costo e la facilità di scalabilità. Tuttavia, in questa fase, i cluster, ancora gestiti dall'azienda, non risolvono il problema del gap di competenze.
La fase successiva dell'elaborazione dei big data prevede lo spostamento dell'elaborazione in un ambiente Hadoop as a service (HaaS) gestito, come Amazon EMR, Microsoft HDInsight, Cloudera Altus, Hortonworks Data cloud, ecc. Questi servizi gestiti hanno il vantaggio di liberare le imprese dalla complessità della gestione e della manutenzione degli ambienti Hadoop. Questi servizi Hadoop gestiti possono anche utilizzare i sistemi di storage cloud sottostanti, come Amazon S3 e Microsoft ADLS, facilitando l'ingestione e la consegna dei dati senza doverli spostare/copiare in HDFS.
Facilitare l'idratazione e l'elaborazione dei data lake
La piattaforma di integrazione ibrida di SnapLogic fornisce i mezzi per realizzare l'idratazione dei dati da un insieme completo di endpoint, sia sul sito cloud che in sede. La nostra esclusiva architettura Snaplex è progettata per scambiare dati in un panorama aziendale ibrido complesso e in continua evoluzione.
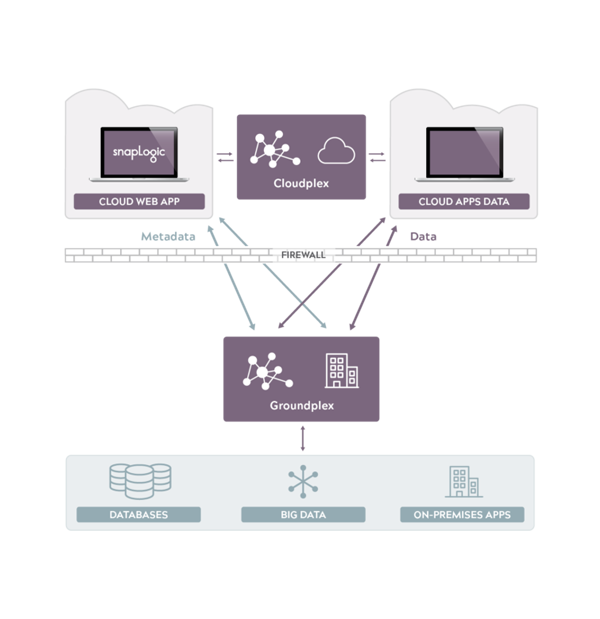
Per contribuire a colmare il divario di competenze associato al lavoro con i big data attraverso l'idratazione dei dati, la connessione agli endpoint è facile come trascinare e rilasciare. La connessione agli endpoint avviene attraverso l'uso di connettori chiamati Snaps. Abbiamo più di 400 Snaps che si collegano a ERP, CRM, HCM, Hadoop, Spark, analytics, gestione delle identità, social media, storage online, database relazionali, colonnari e a valore-chiave e tecnologie come XML, JSON, OAuth, SOAP e REST, per citarne alcune. Disponendo di una serie completa di endpoint, SnapLogic può aumentare il valore dell'elaborazione dei big data includendo una maggiore varietà di dati.
SnapLogic estende l'integrazione dai tradizionali integratori IT agli integratori LoB ad hoc attraverso la sua interfaccia di programmazione visiva. Il designer visuale di SnapLogic semplifica agli utenti LoB, agli specialisti dell'integrazione e all'IT la creazione di integrazioni in poche ore, non in giorni o settimane, senza bisogno di codifica.
Con la trasformazione dei dati in una nuova valuta, le aziende che diventano veramente guidate dai dati otterranno un vantaggio competitivo. Abbiamo assistito allo spostamento dei dati e delle applicazioni su cloud e ora stiamo assistendo allo spostamento dell'elaborazione dei big data su cloud. Le vostre soluzioni di elaborazione dei big data continueranno a evolversi proprio come hanno fatto prima di loro il SaaS e i dati. Siete pronti? SnapLogic è in grado di supportare tutto questo ed è qui per la vostra migrazione all'elaborazione dei big data in cloud.
1. [Fonte: Gartner: Derive Value From Data Lakes Using Analytics Design Patterns Sept 2017]







