





Secondo McKinsey, entro il 2025 i dipendenti delle aziende utilizzeranno i dati per ottimizzare quasi tutto il loro lavoro. Le applicazioni e le piattaforme del vostro stack tecnologico forniscono già un'enorme quantità di dati che possono catturare informazioni aziendali critiche. Ma prima di poter sfruttare i dati, è necessario un modo per gestirne l'ingresso e il flusso all'interno dell'organizzazione.
Entriamo nella spina dorsale dell'impresa moderna: la pipeline dei dati.
Che cos'è una pipeline di dati?
Una pipeline di dati è una serie di flussi di lavoro automatizzati per spostare i dati da un sistema a un altro.
In linea di massima, la pipeline dei dati è composta da tre fasi:
- Ingestione dei dati dal punto A (la fonte).
- Trasformazione o elaborazione.
- Caricamento al punto B (lago, magazzino o sistema di analisi di destinazione).
Ogni volta che l'elaborazione avviene tra il punto A e il punto B, si è creata una pipeline di dati tra i due punti. Se l'elaborazione avviene dopo il punto B, si è comunque creata una pipeline di dati, ma con una configurazione diversa.
Le pipeline di dati consolidano i dati provenienti da fonti isolate in un'unica fonte di verità utilizzabile da tutta l'organizzazione, quindi sono essenziali per l'analisi e il processo decisionale. Senza una pipeline, i team analizzano i dati provenienti da ogni fonte in modo isolato, impedendo loro di vedere come i dati siano collegati tra loro a livello di visione d'insieme.
Pipeline di dati vs. ETL vs. ELT
"Data pipeline" è un termine generico, mentre ETL (extract, transform, load) e ELT (extract, load, transform) sono tipi di data pipeline.
Le pipeline di dati ETL estraggono i dati dall'origine, li trasformano attraverso una serie di operazioni e li caricano nel magazzino o nel sistema di destinazione. Una trasformazione è un'azione automatizzata che modifica i dati prima che raggiungano il magazzino. Le trasformazioni più comuni includono:
- Pulizia e deduplicazione dei dati.
- Aggregazione di diversi set di dati.
- Conversione dei dati in un altro formato.
- Esecuzione di calcoli per creare nuovi dati.
Se si utilizza una pipeline ETL, l'obiettivo è convalidare, sfoltire e standardizzare i dati prima che vengano caricati nel magazzino.
Se si trasformano i dati dopo che hanno raggiunto il magazzino, si utilizza una pipeline di dati ELT. Chi utilizza l'archiviazione dei dati cloud spesso preferisce l'ELT perché consente di accelerare e semplificare la consegna dall'origine al magazzino.
Esempi di architettura della pipeline di dati
Una semplice pipeline ETL si presenta così:
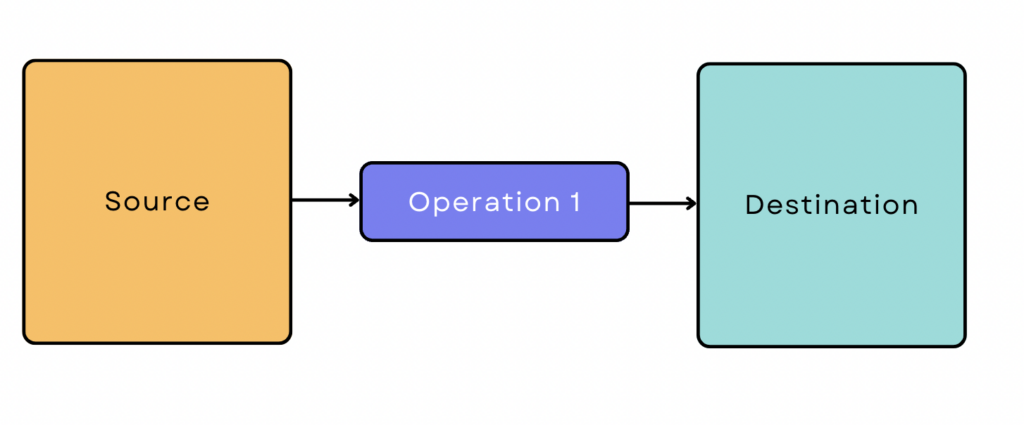
Tuttavia, la maggior parte delle pipeline di dati non è così semplice. Di solito coinvolgono molte fonti e operazioni e i dati spesso interagiscono con altri strumenti e piattaforme lungo il percorso. A volte diverse operazioni vengono eseguite in parallelo per accelerare il processo.
All'inizio della pipeline di dati, ci sono due modi per ingerire i dati dalla sorgente: l'elaborazione batch e l'elaborazione in tempo reale/streaming. A volte è necessaria una combinazione di entrambi. Queste diverse esigenze di ingestione sono alla base di tre configurazioni comuni della pipeline di dati.
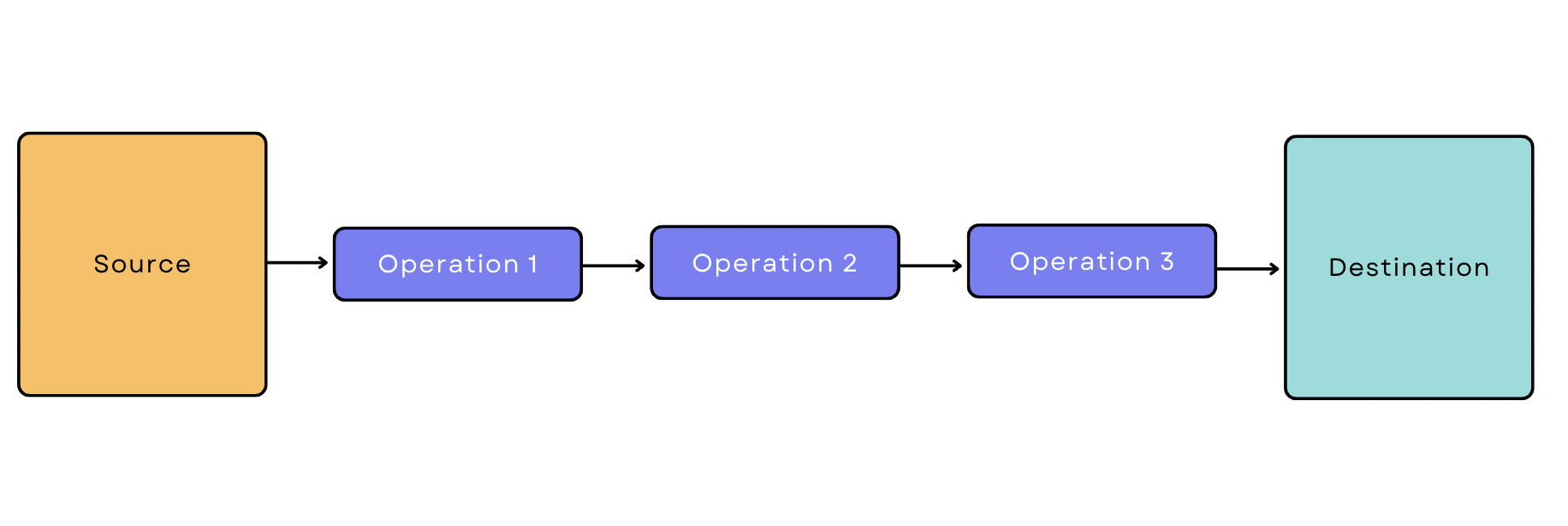
Pipeline di dati basate su batch
Nell'elaborazione batch, lo strumento di ingestione estrae i dati dall'origine in batch a intervalli di tempo periodici. Una pipeline di dati basata su batch è una pipeline che inizia con l'ingestione in batch. Supponiamo di voler estrarre i dati transazionali da Google Analytics, applicare tre trasformazioni e caricarli nel magazzino. La pipeline avrebbe il seguente aspetto:
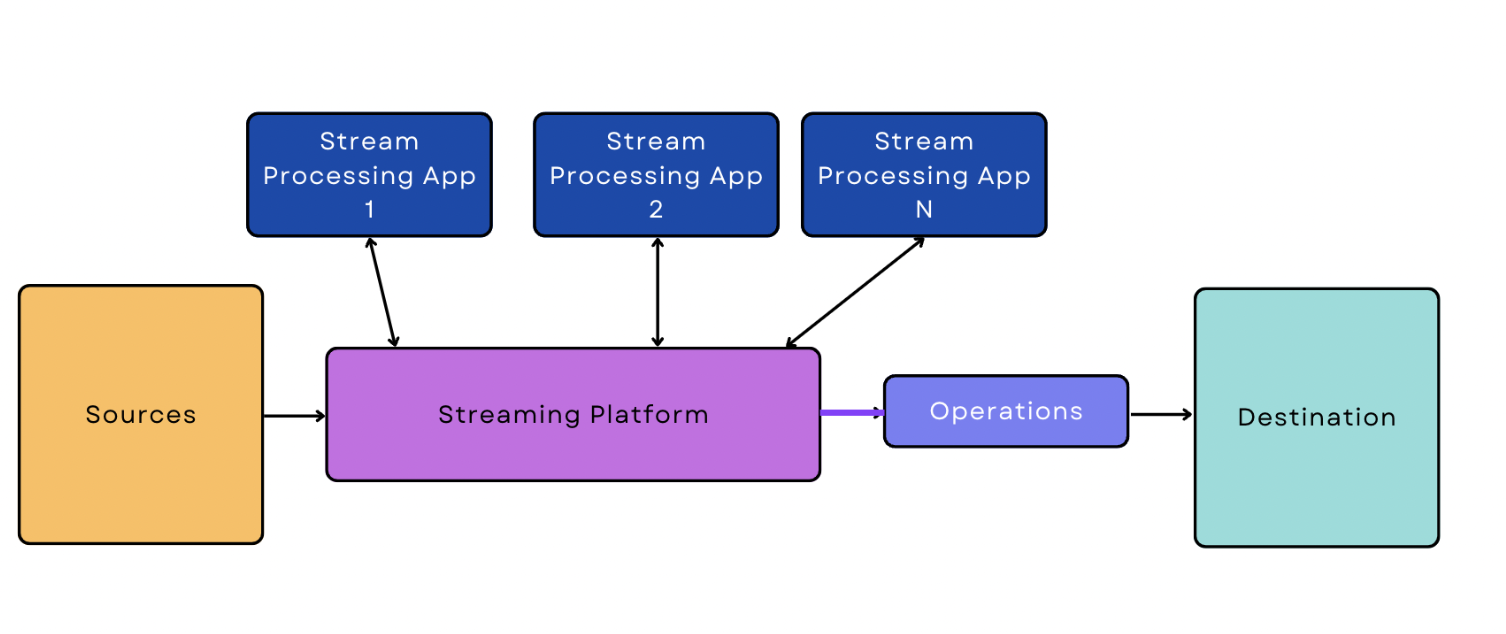
Pipeline di dati in tempo reale/streaming
Nell'elaborazione in tempo reale/streaming, i dati vengono ingeriti dalla sorgente in modo continuo e in tempo reale. Una pipeline di dati in streaming è una pipeline che inizia con l'ingestione dei dati in tempo reale/streaming.
Rispetto all'ingestione batch, l'ingestione in tempo reale/streaming è più difficile da gestire per il software, che deve essere attivo e monitorare costantemente lo streaming dei dati in tempo reale. Questa maggiore complessità si manifesta anche nella pipeline stessa; la versione più semplice di una pipeline di dati in streaming è un po' più complicata della versione più semplice di una pipeline basata sul batch.
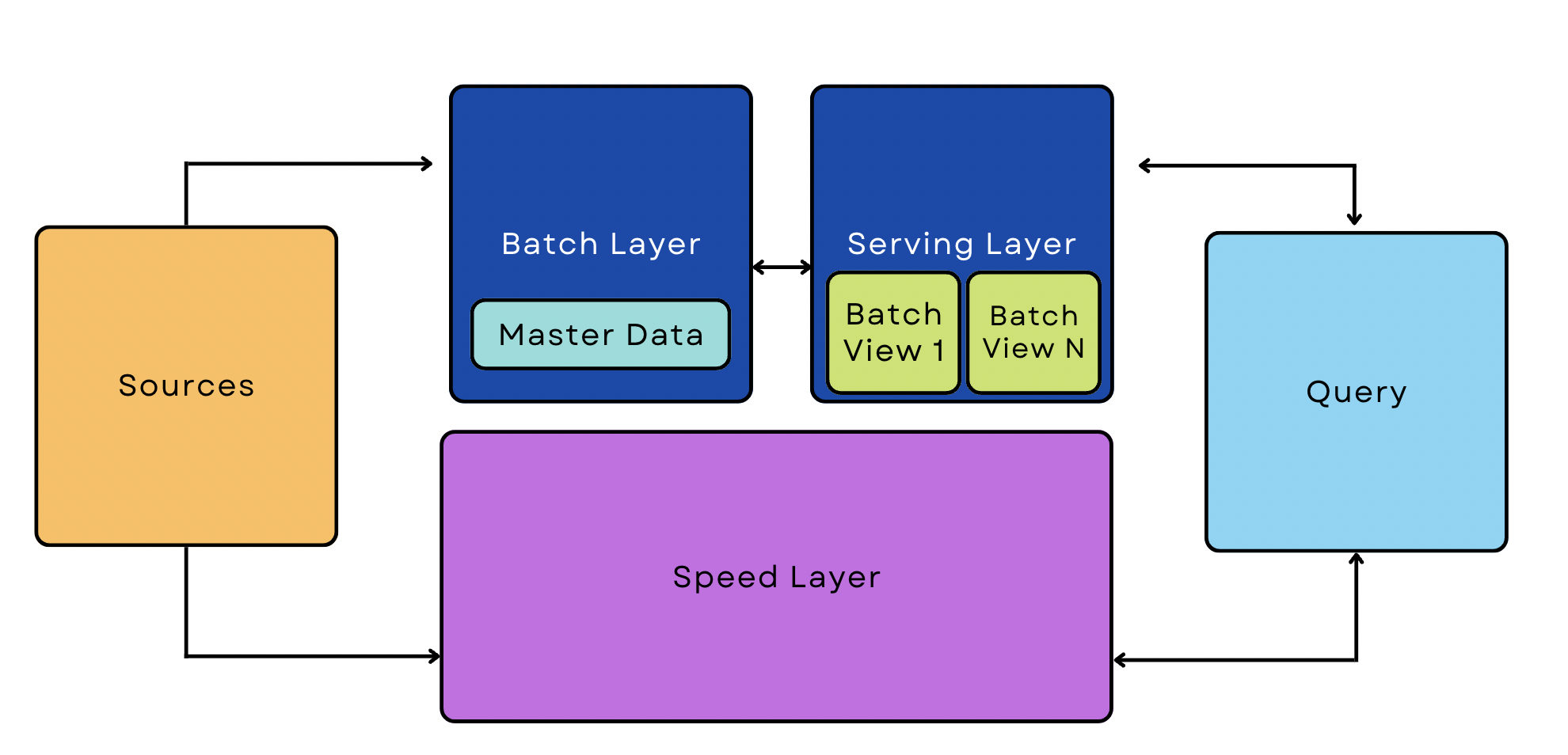
Pipeline dell'architettura Lambda
Una pipeline Lambda combina processi batch e streaming nella stessa architettura. Queste pipeline sono metodi popolari per gestire i big data, perché possono ospitare casi d'uso sia in streaming che in tempo reale.
5 passi per costruire una pipeline di dati interna da zero
Rispetto all'utilizzo di strumenti disponibili, la creazione di una pipeline da zero è spesso un processo che richiede tempo e risorse. In genere ha senso solo per le organizzazioni con esigenze eccezionalmente specializzate e con molte risorse ingegneristiche. Se la vostra azienda rientra in questi criteri, prendete in considerazione l'idea di seguire questi passaggi per costruire la vostra pipeline.
1. Delineare gli obiettivi e i vincoli
Iniziate con una comprensione precisa di ciò che dovete fare con la pipeline. Volete estrarre informazioni da un database e unirle a un altro? Dovete inserire i risultati in un negozio online? Quante fonti avrete?
Più precisamente, delineare quanto segue:
- Fonti - Quali fonti di dati utilizzate?
- Tipo di ingestione dei dati - I dati possono essere elaborati in batch o è necessario un flusso continuo?
- Destinazione - Dove sono diretti i dati?
- Trasformazione - Come devono cambiare i dati affinché siano coerenti tra le fonti e utili per gli strumenti di analisi? Quando si verificano questi cambiamenti?
- Fermate - I dati devono essere inviati ad altre applicazioni o destinazioni lungo il percorso?
2. Tracciare un flusso di lavoro di alto livello
Disegnate i componenti principali della vostra pipeline utilizzando un software di modellazione, un diagramma di flusso o anche carta e penna. Questa fase aiuta a visualizzare i diversi componenti dell'architettura e la loro interazione reciproca.
Lasciate che le seguenti domande guidino la costruzione della vostra pipeline, puntando al flusso di lavoro più semplice che possa portare a termine il lavoro:
- Ci sono dipendenze a valle da lavori a monte? Ad esempio, se avete dati di origine da database MySQL, avete bisogno dei risultati di un processo ETL prima di passare a un'altra fase?
- Quali lavori possono essere eseguiti in parallelo (se ce ne sono)?
- Più strumenti devono accedere agli stessi dati? Che tipo di sincronizzazione è necessaria?
- Qual è il flusso di lavoro per i lavori falliti? Chi riceve la notifica?
- Se i dati ingeriti non superano la convalida, dove vanno a finire? Volete scartarli automaticamente o preferite diagnosticare gli errori e reintrodurli nella vostra pipeline?
3. Progettare i componenti principali
Se state costruendo la vostra pipeline di dati da zero, dovrete scrivere il software per estrarre e trasformare i dati. Questa fase varia molto da pipeline a pipeline.
Supponiamo di voler consolidare i dati dei clienti provenienti da sistemi diversi, come il CRM e il sistema del punto vendita. In questo caso, dovrete scrivere programmi che puliscano e deduplichino i dati e poi li "normalizzino" in base agli stessi campi (sesso, formato dei dati, ecc.) in modo che vengano assimilati correttamente. I dati consolidati potrebbero poi essere utilizzati per creare notifiche personalizzate, upsell e campagne e-mail segmentate.
4. Scalare la pipeline
Eseguire test di benchmark/carico per identificare eventuali colli di bottiglia e problemi di scalabilità. Questo vi aiuterà a identificare le prestazioni target e di picco della vostra pipeline, il carico target e di picco e i limiti di prestazione accettabili.
Se dal test di carico emergono colli di bottiglia o altri problemi di scalabilità, valutate come risolverli.
- Il bilanciamento del carico distribuisce il traffico di rete su un gruppo di server, bilanciando il volume di traffico che ogni server deve gestire. Questa soluzione è utile quando si tratta di servire milioni di utenti e di gestire un gran numero di richieste simultanee.
- Lo sharding dei database è un tipo di bilanciamento del carico. In questo caso, si divide un grande volume di dati (non di traffico) su una rete di server. È utile per gli stessi casi d'uso del bilanciamento del carico: se avete milioni di utenti, state lavorando con un'enorme quantità di dati.
- Scalare orizzontalmente significa aggiungere più macchine al pool (scalare verso l'esterno) invece di aggiungere più GPU o RAM ai server esistenti (scalare verso l'alto). Lo scaling out consente in genere una maggiore flessibilità rispetto allo scaling up, ma può essere più costoso.
- La cache memorizza copie di un file in una posizione di archiviazione temporanea, in modo da potervi accedere più rapidamente. Sul front-end, la cache consente agli utenti di accedere ai contenuti del sito web e di cercare informazioni nel database il più rapidamente possibile.
5. Implementare un quadro di governance dei dati
A questo punto, la vostra pipeline di dati è completa, ma è necessario un piano per mantenere i dati degli utenti sicuri e conformi alle normative in tutta la pipeline. Identificate tutti i casi di dati sensibili che ingerite e memorizzate, comprese le informazioni personali, i dati delle carte di credito e tutto ciò che è protetto dal GDPR o da altre normative.
Quindi, delineate le misure che adotterete per proteggere i dati. Le misure di sicurezza più comuni includono:
- Crittografia dei dati.
- Impostazione dei controlli di accesso basati sui permessi.
- Mantenere registri e registrazioni dettagliate.
- Monitoraggio dei dati tramite strumenti di terze parti come Datadog.
- Abilitare l'autenticazione a più fattori e l'applicazione di password forti sul front-end per contribuire alla salvaguardia dalle violazioni.
Costruire o comprare? Alternative alla costruzione di una pipeline da zero
Creare una pipeline di dati da zero può essere costoso e difficile rispetto all'utilizzo di strumenti di ingestione già pronti con connettori precostituiti. Le modifiche a monte dell'API o le nuove esigenze di analisi possono modificare l'ambito di un progetto a metà strada, creando un lavoro costante e continuo.
Gli strumenti di ingestione disponibili fanno risparmiare tempo e denaro automatizzando le funzioni critiche senza costringervi a scrivere software per eseguire ogni attività. Le piattaforme di integrazione come SnapLogic dispongono di librerie di connettori precostituiti che possono essere utilizzati per creare pipeline di dati personalizzate, senza necessità di codifica.
Costruire pipeline di dati intelligenti con SnapLogic
Non sprecate le vostre risorse ingegneristiche per reinventare la ruota. I connettori low-code/no-code di SnapLogic, progettati da esperti, consentono di creare pipeline di dati potenti e flessibili in modo immediato. Con oltre 600 connettori tra cui scegliere e opzioni di sincronizzazione e preparazione dei dati automatizzate, SnapLogic si integra con l'intero stack tecnologico.
Siete pronti a scoprire quanto può essere più facile costruire pipeline di dati di livello aziendale? Provate una demo oggi stesso.





