






La capacità di gestire grandi quantità di dati è fondamentale per il successo di qualsiasi organizzazione, anche se la maggior parte di esse rimane indietro rispetto alla curva e fatica a raggiungere risultati guidati dai dati. Anche con dati ricchi di informazioni a portata di mano, secondo un articolo del maggio 2017 pubblicato su Harvard Business Review, "più del 70% dei dipendenti ha accesso a dati che non dovrebbe avere e l'80% del tempo degli analisti viene speso semplicemente per scoprire e preparare i dati".
Dove entra in gioco l'apprendimento automatico? Con l'esplodere della necessità di ottenere migliori informazioni dai dati, abbiamo parlato con clienti che cercavano aiuto nell'apprendimento automatico e abbiamo scoperto che i loro ingegneri dei dati dedicavano il 70-80% del loro tempo all'acquisizione, all'esplorazione e alla preparazione dei dati nell'ambito del ciclo di vita dell'apprendimento automatico. Abbiamo anche sentito parlare della scarsità di esperti di scienza dei dati e di strumenti di preparazione dei dati poco utili, non integrati e poco maneggevoli. Siamo arrivati alla conclusione che l'apprendimento automatico (ML) è in realtà un problema di integrazione, che rende SnapLogic una piattaforma naturale per l'ML. Così, a novembre, abbiamo lanciato SnapLogic Data Science per gestire e controllare l'intero ciclo di vita dell'apprendimento automatico.
In questo blog post, mentre illustriamo alcune delle funzionalità dell'offerta SnapLogic Data Science, vedrete come la preparazione dei dati e l'apprendimento automatico possono essere facili da usare, divertenti e semplici. È possibile seguire SnapLogic anche iscrivendosi a una prova gratuita di 30 giorni.
Una nuova soluzione self-service per l'apprendimento automatico
SnapLogic Data Science - presentato nella nostra ultima release come estensione della piattaforma di integrazione intelligente di SnapLogic - è una nuova soluzione self-service che accelera lo sviluppo e l'implementazione dell'apprendimento automatico con una codifica minima lungo l'intero ciclo di vita dell'apprendimento automatico, come illustrato di seguito.
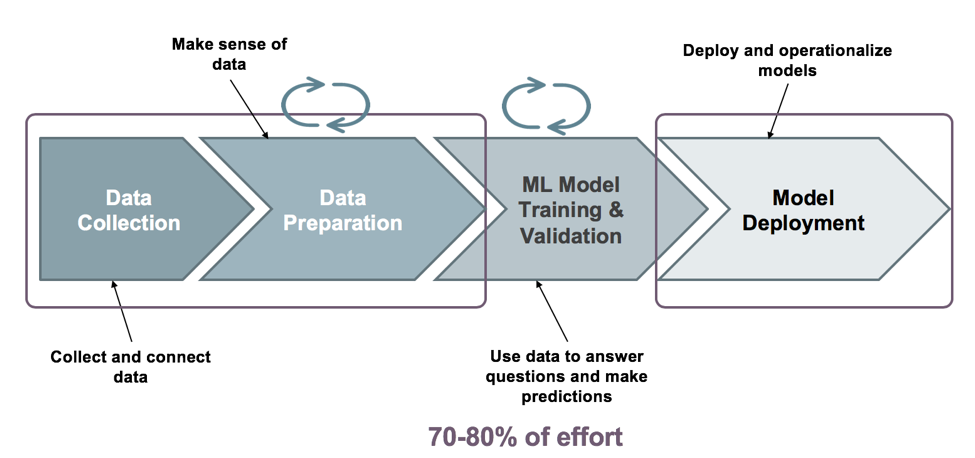
Raccolta e preparazione dei dati
Vediamo la raccolta e la preparazione dei dati e l'insieme di funzionalità che SnapLogic Data Science offre a questo bucket ML. È qui che un data engineer accede e assembla i dati per l'utilizzo da parte dei modelli di apprendimento automatico ed esegue l'ingegneria delle caratteristiche. È inoltre possibile eseguire operazioni preparatorie sui set di dati, come la trasformazione dei tipi di dati, la pulizia dei dati, il campionamento, il rimescolamento e la scalatura. Queste funzionalità eliminano la ridondanza nella preparazione dei dati che a volte viene introdotta da una disconnessione tra la scienza dei dati e i team IT/DevOps.
L'offerta SnapLogic Data Science prevede tre Snap Pack: il ML Data Preparation Snap Pack, il ML Core Snap Pack e il ML Analytics Snap Pack per supportare la raccolta e la preparazione dei dati.
- Il Pacchetto Snap per la preparazione dei dati ML consente ai data engineer e ai data scientist di eseguire operazioni preparatorie sui set di dati, come la trasformazione del tipo di dati, la pulizia dei dati, il campionamento, il rimescolamento e il ridimensionamento. Fornisce snap chiave come Clean Missing Values Snap che sostituisce i valori mancanti nei set di dati eliminando o imputando i valori. È disponibile anche lo snap Date Time Extractor che estrae i componenti dagli oggetti datetime da inserire nei campi dei risultati per ulteriori analisi. Lo snap Campione aiuta a generare insiemi di dati campione da un insieme di dati di input utilizzando vari tipi di algoritmi di campionamento, come il campionamento stratificato, il campionamento stratificato ponderato, ecc. Lo snap Scala aiuta a scalare i valori nelle colonne per specificare intervalli o applicare trasformazioni statistiche. L'opzione Shuffle Snap randomizza l'ordine dei dati delle righe nel set di dati.
- Il ML Core Snap Pack consente agli ingegneri dei dati di eseguire operazioni sui set di dati di apprendimento automatico, come l'addestramento dei modelli, la convalida incrociata e le previsioni basate sui modelli.
- Il ML Analytics Snap Pack aiuta i data engineer a eseguire operazioni analitiche come la profilazione dei dati e l'ispezione dei tipi di dati.
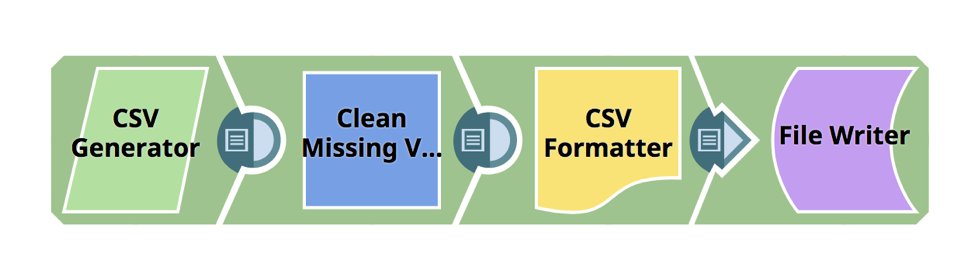
L'esempio seguente mostra come lo snap Clean Missing Values può essere utilizzato in una pipeline per la preparazione dei dati. Clean Missing Values è uno snap di tipo Transform utilizzato per gestire i valori mancanti in un set di dati in entrata eliminando o imputando i valori e supporta quattro approcci: Eliminare riga, Imputare con media, Imputare con popolare e Imputare con valore personalizzato.
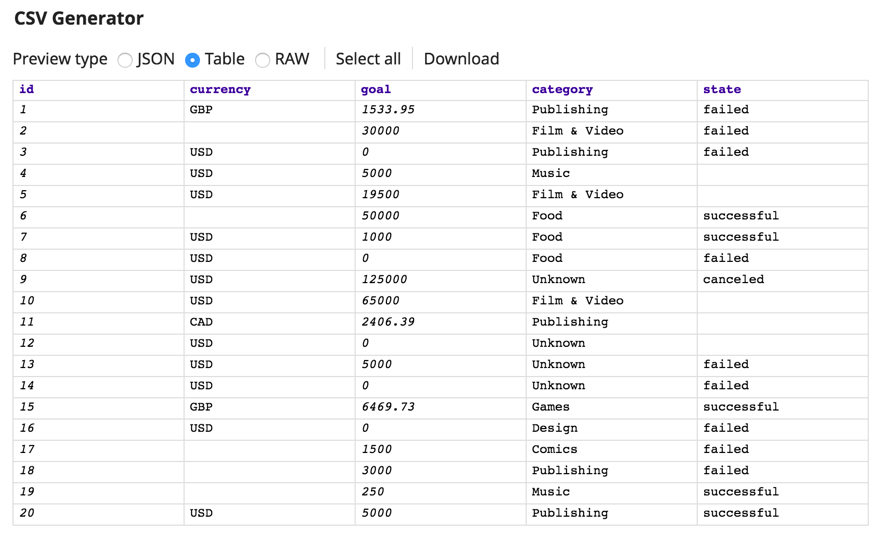
Per prima cosa, utilizzando il generatore CSV Snap, abbiamo un semplice file csv con valori mancanti per la valuta, come si può vedere nella terza riga.
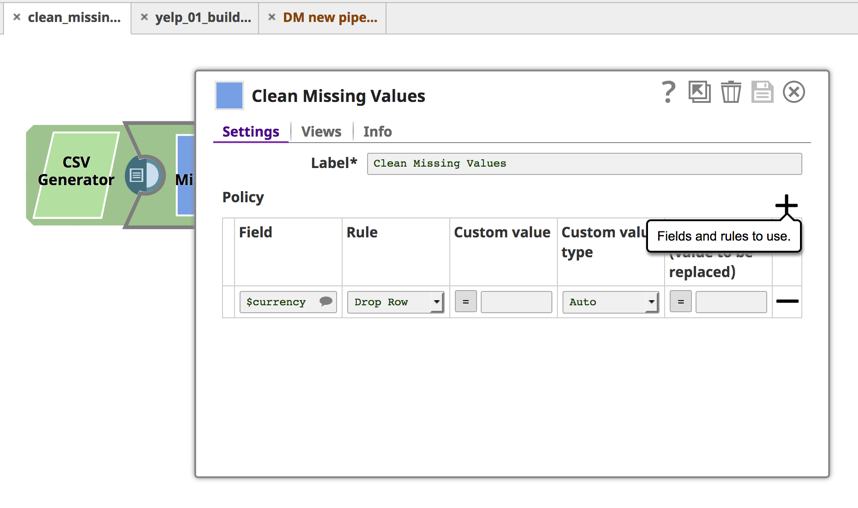
Il prossimo Snap della pipeline, Pulisci valori mancanti, consente di definire una regola che elimina la riga se il valore della valuta è nullo.
Una volta eseguita la pipeline, la schermata sottostante mostra l'aspetto del file ripulito. La riga è stata eliminata e il file è stato ripulito.
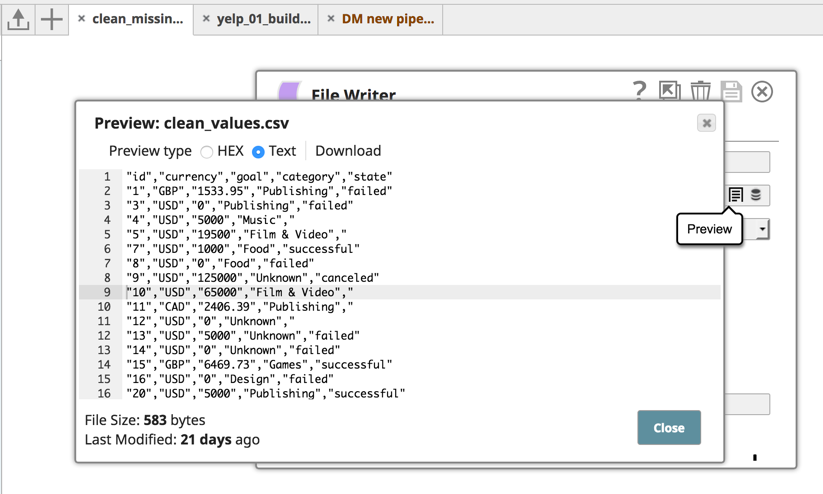
Una volta ripuliti i dati, è possibile utilizzare Profile Snap per profilare i dati e calcolare le statistiche dei dati in entrata.
Ecco una pipeline che mostra questa parte del processo.

Osservando il file utilizzato per memorizzare i vari tipi di asset, è possibile vedere come sono strutturati i dati di origine.
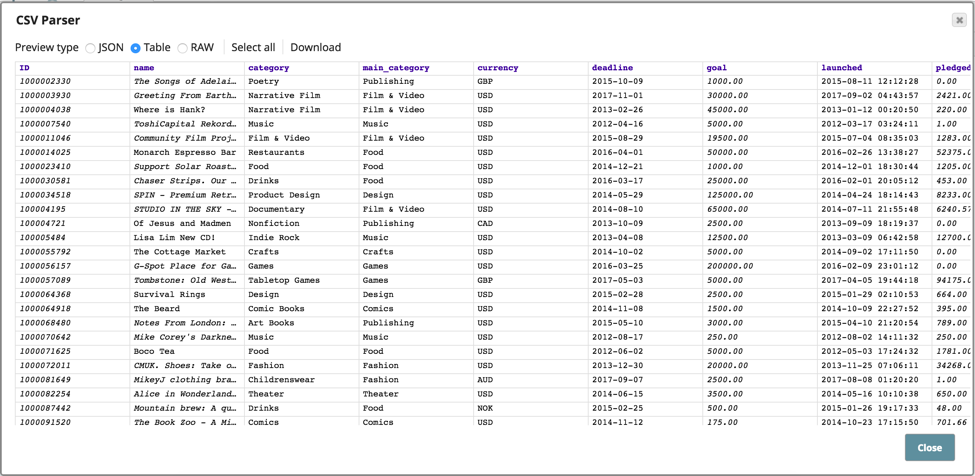
La pipeline mostrata qui sopra è stata impostata per analizzare e profilare i dati CSV, per poi scrivere l'output del profilo in un file di output JSON. Ecco come appare l'output del profilo con la distribuzione dei valori, ecc.
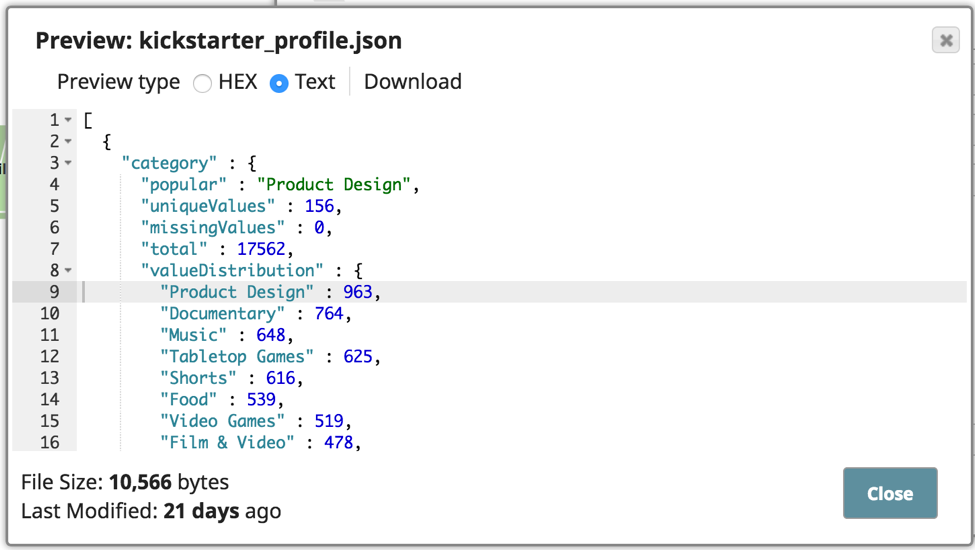
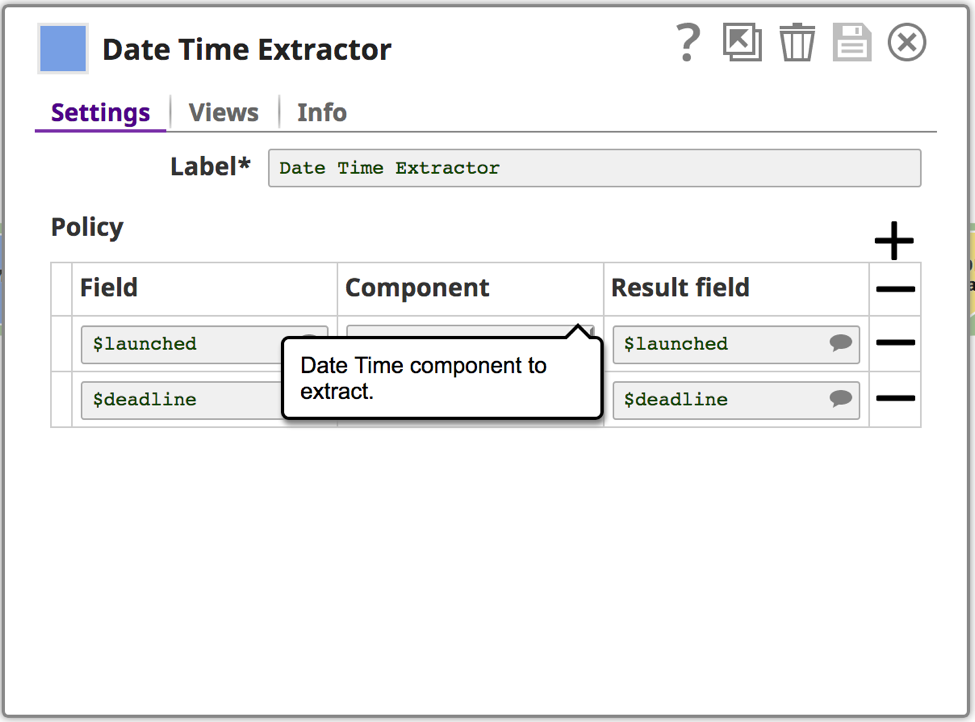
Questo aiuterà a determinare quali ulteriori pulizie dei dati devono essere effettuate. Un'altra cosa da sottolineare è che sto usando lo snap Estrattore di date, che è uno snap di tipo Transform che estrae componenti dai dati datetime e li aggiunge al campo del risultato. In questo caso, sto estraendo il valore dell'epoca nel campo del risultato. È possibile utilizzare lo snap per preparare i dati prima di eseguire l'aggregazione o l'analisi.
Date potere allo scienziato dei dati che è in voi
Spero che questo rapido passo-passo di SnapLogic Data Science dimostri che l'esecuzione di attività di preparazione dei dati può essere semplice e divertente. Ora i data scientist possono iniziare il loro lavoro di analisi del problema e di creazione di modelli basati su ML più velocemente di prima. E gli ingegneri dei dati possono preparare i dati, integrandoli da più fonti e trasformandoli in una forma utilizzabile, in modo self-service.
Non mi credete? Iscrivetevi alla prova gratuita di 30 giorni.







