Introduzione
Molti clienti di SnapLogic combinano la piattaforma SnapLogic Intelligent Integration con un'ampia gamma di strumenti per ottenere un controllo end-to-end del ciclo di vita delle pipeline e di altri asset. Tali processi possono includere la generazione automatica di ticket di helpdesk sugli errori, processi di revisione manuali e automatici attraverso sistemi di controllo delle versioni, pipeline di integrazione continua e distribuzione continua, test unitari e controlli di conformità e qualità aziendali.
Poiché le aziende hanno politiche, requisiti, processi e toolchain diversi, non esiste un'unica raccomandazione o soluzione per ottenere la gestione e l'automazione del ciclo di vita end-to-end valida per tutti.
Questa serie di blog post ha l'obiettivo di presentare una serie di sfide che le aziende devono affrontare nello sviluppo di integrazioni moderne e come è possibile affrontarle facilmente con SnapLogic. In particolare, questa serie descriverà anche le tipiche figure di utenti coinvolti nelle integrazioni e come la combinazione di SnapLogic e altri strumenti possa aiutare ad automatizzare e governare il ciclo di vita di queste integrazioni.
Nella prima parte, si apprenderà come la piattaforma SnapLogic
- catturare automaticamente gli errori,
- segnala gli errori generando automaticamente dei ticket con informazioni dettagliate sugli errori e
- aiutare gli integratori e i team di test a risolvere i problemi con particolare attenzione al riutilizzo e alla facilità d'uso.
Personaggi
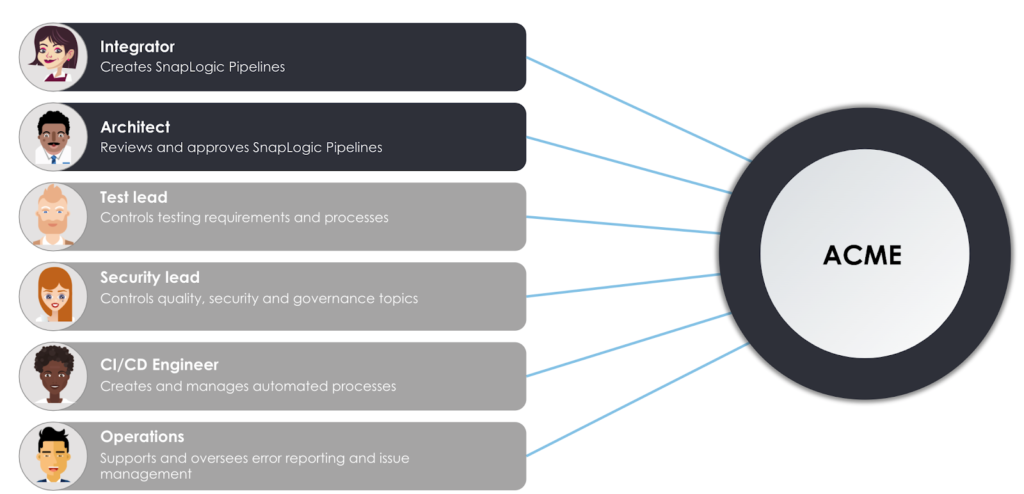
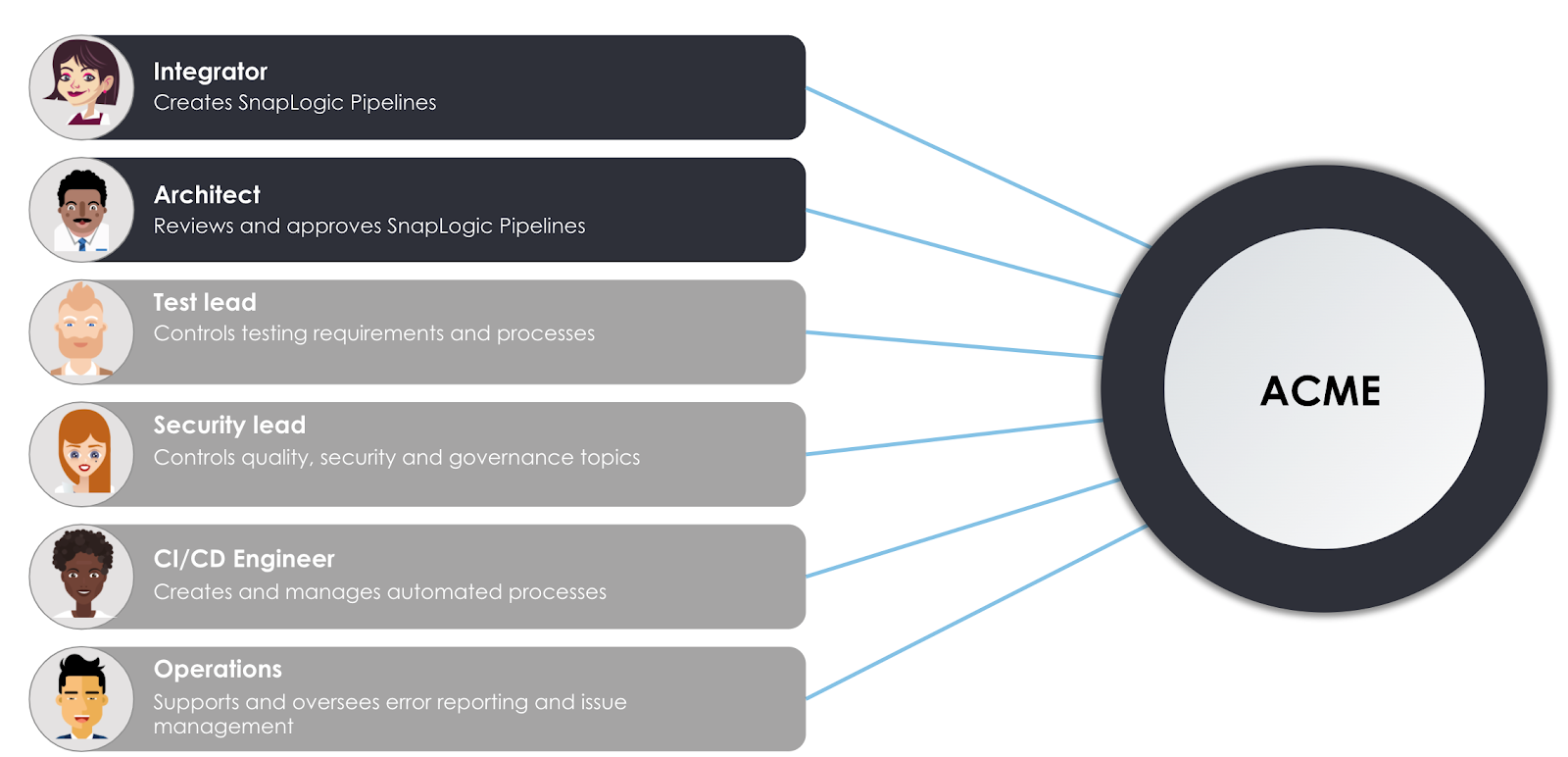
Si considerino le personas utente di cui sopra, coinvolte nell'azienda fittizia ACME.
- Il Integratore è responsabile di lavorare con la piattaforma SnapLogic Intelligent Integration per progettare e creare pipeline a supporto dei requisiti aziendali. Si occupa anche di rivedere le pipeline dei colleghi e di chiedere ai colleghi di rivedere il suo lavoro mentre si sposta tra i vari settori di sviluppo. sviluppo e produzione produzione ambienti
- Il suo collega, l? Architettoè un ruolo esperto, responsabile della revisione delle pipeline e di altre modifiche alle risorse nel passaggio tra le organizzazioni. Vedrete che l'integratore Integratore e Architetto svolgeranno un ruolo chiave nel fornire le integrazioni all'azienda. Tuttavia, altri ruoli sono presenti per garantire che le integrazioni siano fluide, automatizzate, gestite e testate.
- Il Responsabile dei test applica le linee guida e le politiche generali di test dell'azienda allo strumento e ai processi SnapLogic. In particolare, si assicurerà che Gli integratori forniscano una copertura di test come test unitari insieme alle pipeline create.
- Allo stesso modo, il Responsabile della sicurezza governa la sicurezza dei dati e i controlli di qualità dell'azienda. Nel nostro scenario, fornisce una serie di politiche che le pipeline devono rispettare.
- Per automatizzare i processi, il ingegnere CI/CD utilizza una serie di strumenti e servizi per creare pipeline automatizzate basate sulle fasi del ciclo di vita. In particolare, crea processi che automatizzano i controlli dei test unitari, i controlli di qualità e le promozioni della pipeline tra il sistema di sviluppo e il sistema di gestione. sviluppo e produzione produzione.
- Infine, sebbene SnapLogic fornisca l'introspezione e la convalida degli schemi in tempo reale per aiutare gli integratori. Integratori creare pipeline stabili e prevedibili, un errore in una pipeline di produzione deve essere rilevato e devono essere generati avvisi. Le Operazioni risponde agli errori in produzione e supervisiona il ciclo di vita dei ticket dell'helpdesk, dalla creazione alla risoluzione.
Nota: I ruoli e le responsabilità di cui sopra sono forniti a titolo indicativo e non corrispondono necessariamente a tutti i clienti SnapLogic. Ad esempio, alcuni dei ruoli sopra elencati saranno svolti dalla stessa persona in un'organizzazione.
Automazione del ciclo di vita delle pipeline SnapLogic
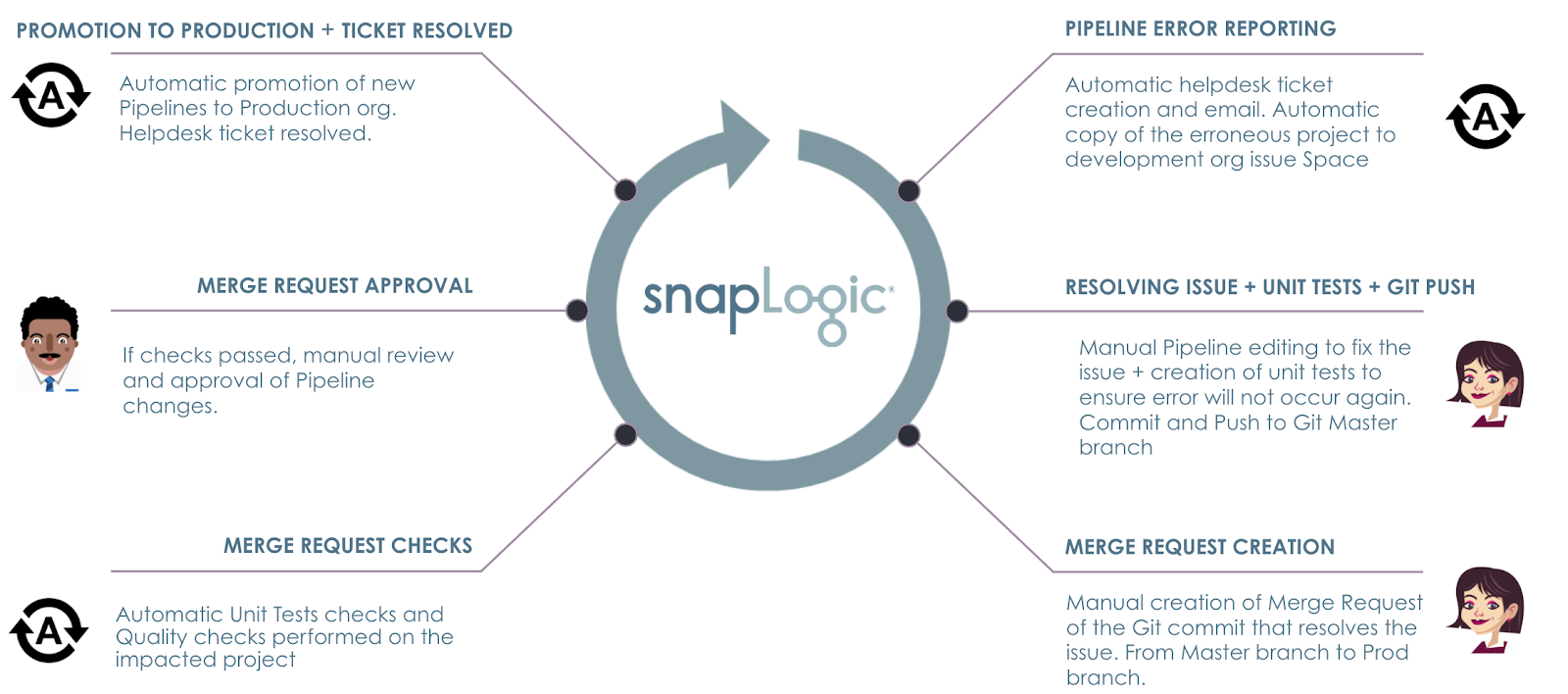
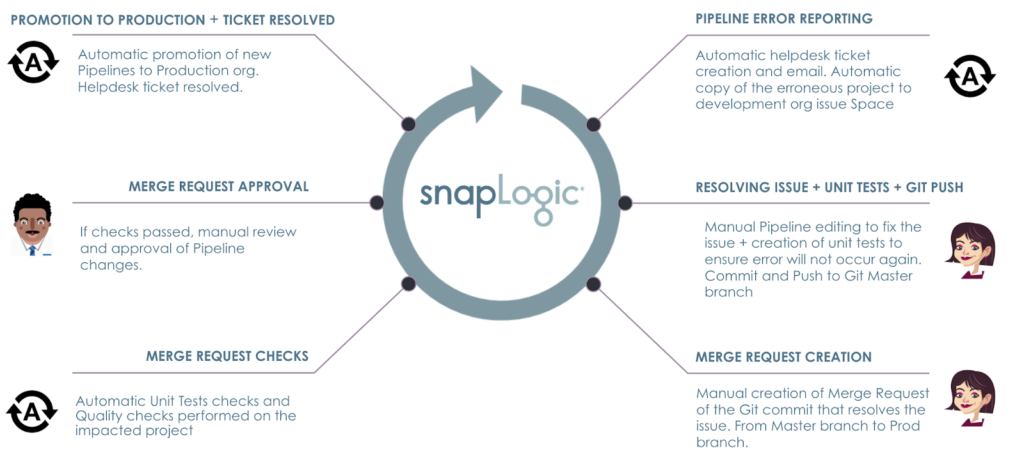
Si consideri questo scenario: Si verifica un errore in una delle produzione pipeline. L'obiettivo è quello di disporre di processi automatizzati per assicurarsi che
- L'errore viene rilevato e segnalato utilizzando lo strumento di helpdesk e il sistema di allerta di ACME, sotto la supervisione di Operazioni.
- Una copia del progetto della pipeline può ricevere immediatamente l'attenzione del integratore per iniziare a correggere il problema nello sviluppo org.
- I test unitari e i controlli di qualità vengono eseguiti prima che Architetto approvare le modifiche.
- Dopo l'approvazione, le condutture vengono automaticamente promosse alla produzione e si risolve di fatto l'errore.
- Il ticket dell'helpdesk viene chiuso automaticamente al momento della promozione con l'invio di un aggiornamento al reparto operativo. Operazioni.
Le fasi dello scenario ACME sono illustrate di seguito.
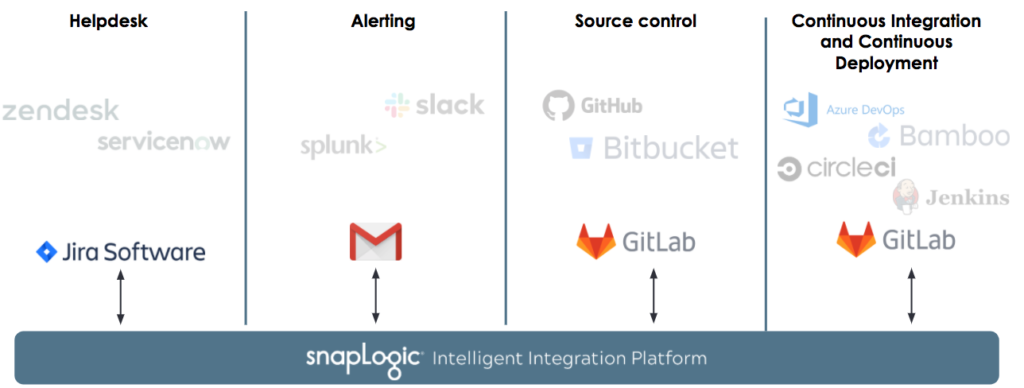
Come accennato all'inizio di questo post, i sistemi di helpdesk dei clienti, gli strumenti di segnalazione degli errori e degli avvisi, i sistemi di controllo delle versioni e gli strumenti di integrazione continua possono variare. SnapLogic funziona senza problemi indipendentemente dallo strumento scelto e non abbiamo una catena di strumenti raccomandata o predefinita per questo processo. Per questo blog post, l'azienda fittizia ACME ha selezionato i seguenti strumenti.
Segnalazione degli errori della pipeline
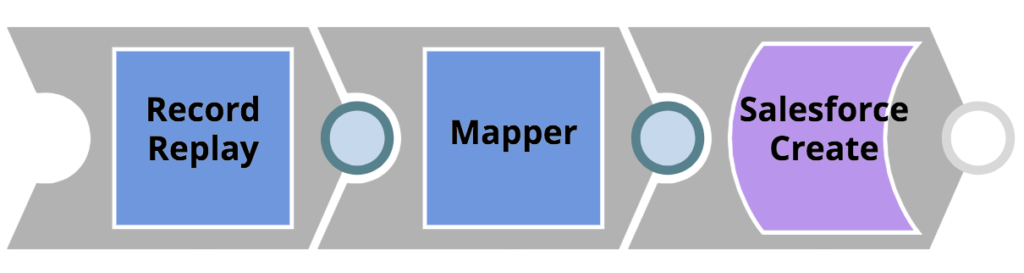
ACME ha l'esigenza di migrare il proprio CRM legacy a Salesforce. A tal fine, CustomerToSalesforce, una pipeline di SnapLogic, riceverà i record dei clienti esistenti dal CRM legacy attraverso un task attività innescata che espone un'API REST.
- Le risorse per questa integrazione risiedono in un progetto chiamato CRM_MIGRAZIONE nella cartella Produzione dell'organizzazione.
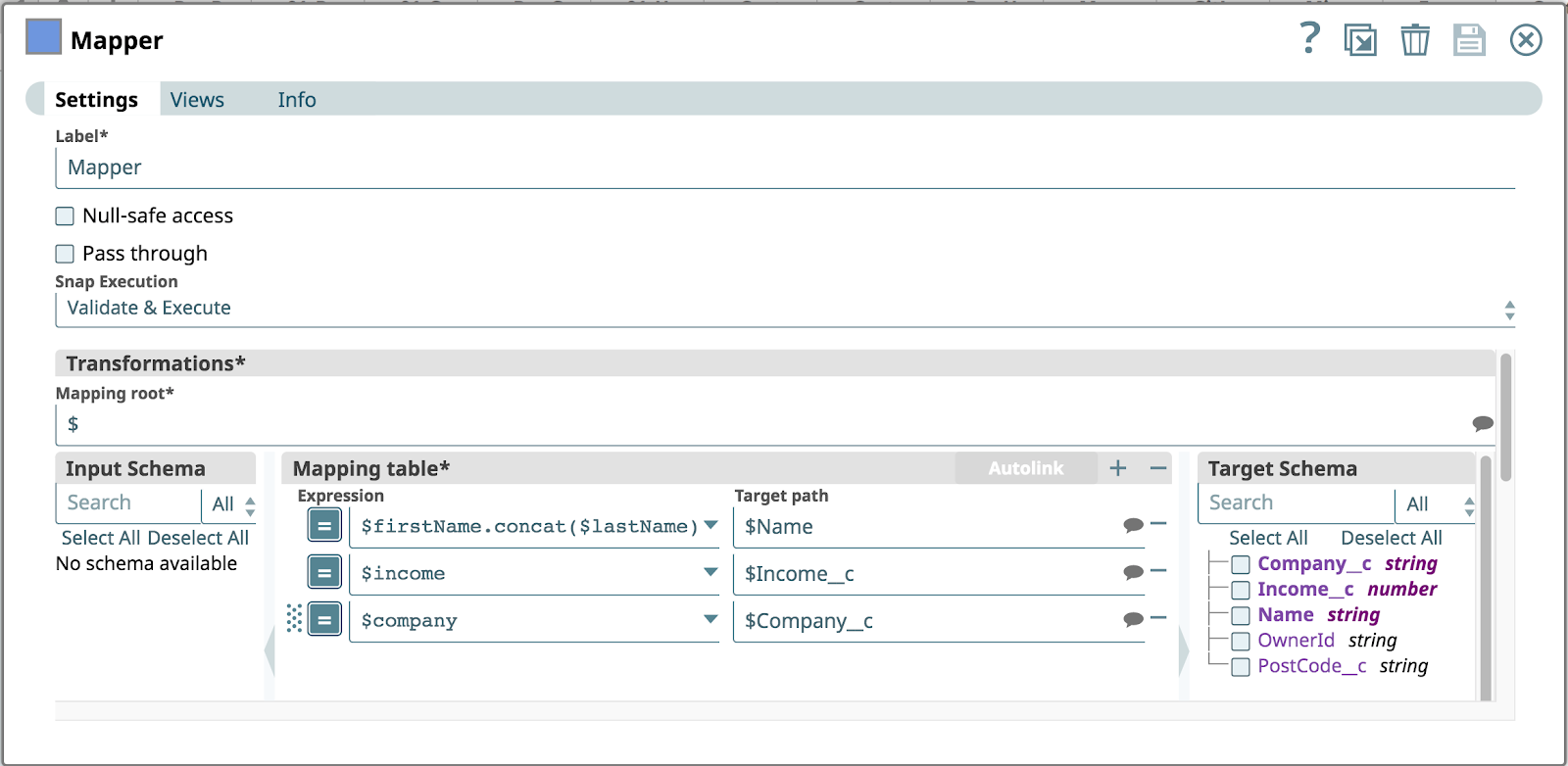
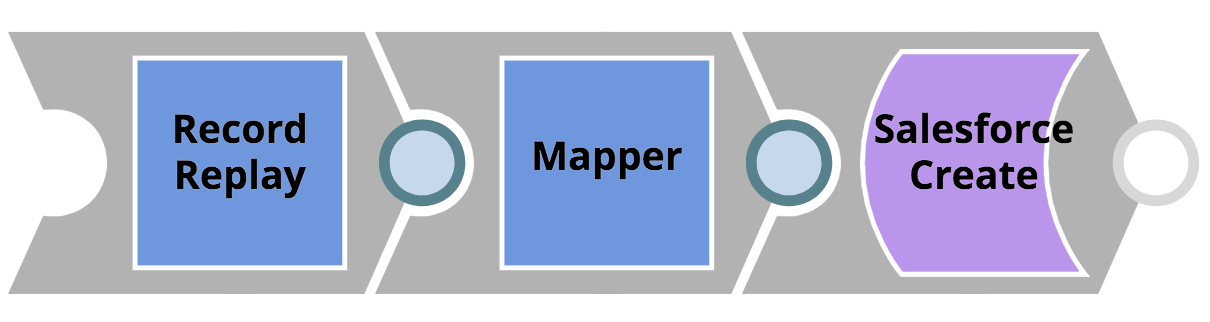
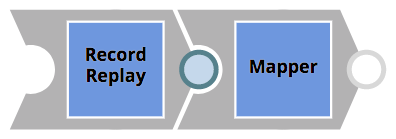
- I record dei clienti passati nella chiamata REST saranno mappati in un oggetto Salesforce. Prima del Mapper Snap applichi la mappatura, uno snap Record Replay Snap per salvare l'oggetto in arrivo nel file system, in modo da poter analizzare i dati dei clienti in un secondo momento, in caso di potenziali problemi. Questa pipeline molto semplice è illustrata di seguito.
L'immagine seguente mostra la configurazione di Mapper Snap. Si presuppone che la chiamata REST in arrivo abbia i seguenti oggetti nel corpo JSON: firstName, cognome, azienda e reddito. L'oggetto Salesforce non ha un nome nome o cognomeinvece viene creata una mappatura per concatenare i campi nome con cognome in un singolo Nome proprietà.
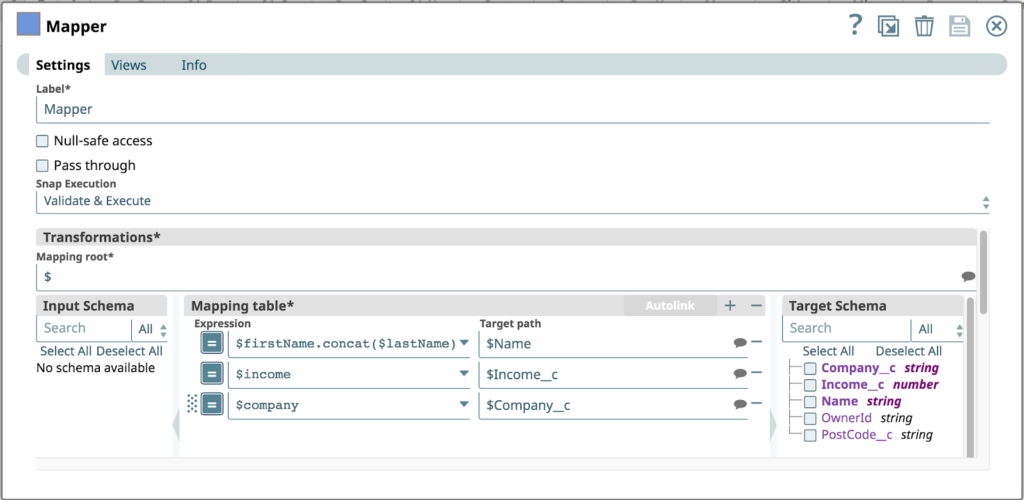
Siete già in grado di individuare i potenziali difetti di progettazione e di dati di questa Pipeline?
Sì, avete capito bene! La pipeline presuppone che il CRM legacy fornisca tutti gli input necessari. Poiché ACME non ha impostato per tempo i propri processi e controlli, questa pipeline è entrata in produzione senza test unitari o controlli di qualità.
Ora, sfortunatamente, il CRM legacy che invoca l'API REST passa un oggetto cliente a cui manca l'elemento firstName e il parametro firstName. Di conseguenza, la prima Espressione nella tabella di mappatura causerà un errore, in quanto l'operazione di concat non andrà a buon fine.
La piattaforma SnapLogic fornisce pipeline di errori per ogni Snap per gestire tali casi di errore. Ora si verificano i seguenti eventi.
- L'errore viene catturato da una pipeline di errori.
- La pipeline degli errori crea un ticket JIRA e avvisa Operazioni inviando un'e-mail
- La pipeline degli errori copia il progetto impattato dalla cartella di produzione in uno spazio Issue nell'ambiente di sviluppo ambiente di sviluppo
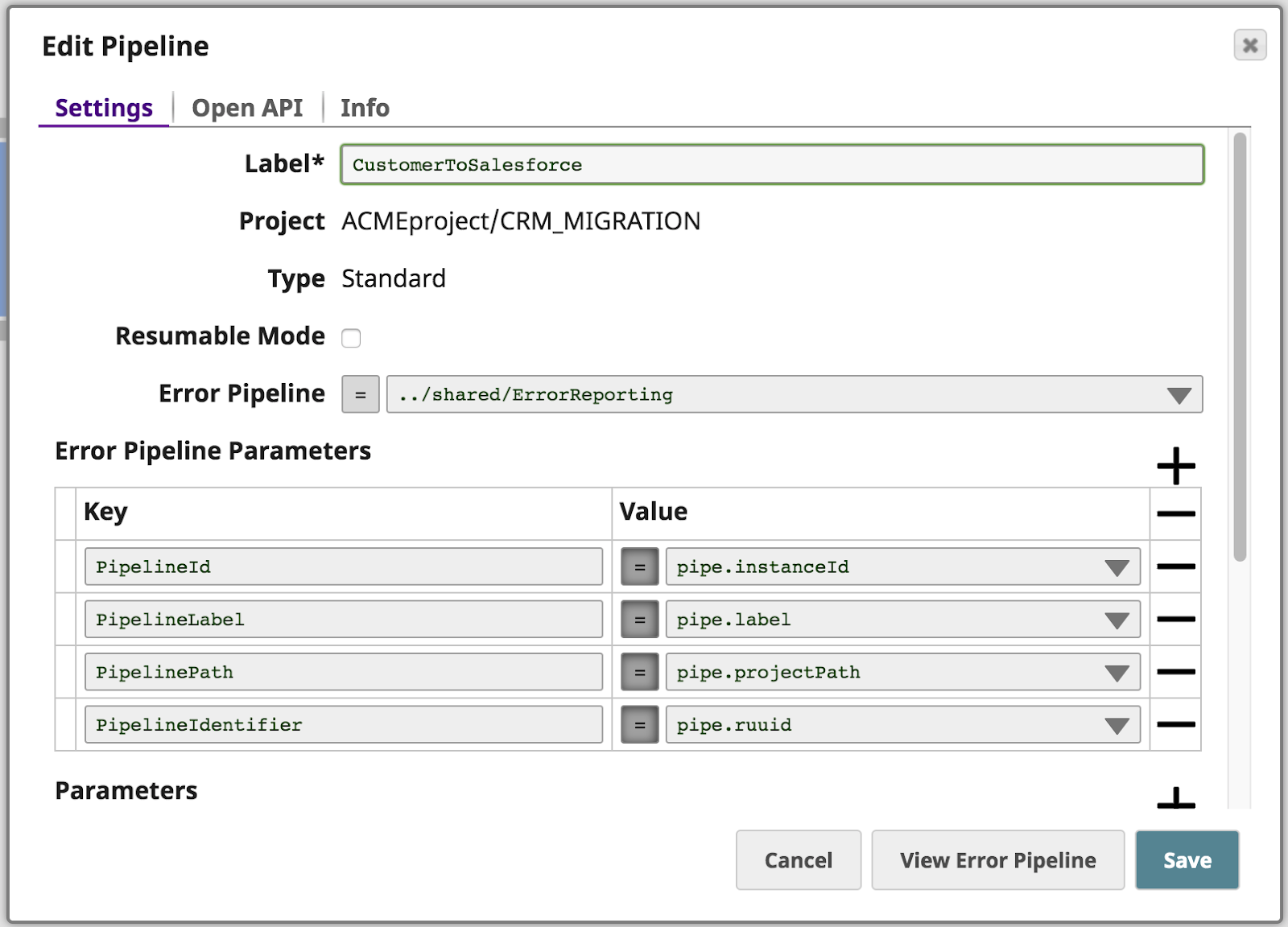
Oltre a instradare l'errore che si è verificato a causa dell'assenza di firstName la pipeline passa un paio di proprietà proprietà della pipeline come parametri alla pipeline degli errori, chiamata ErrorReporting.
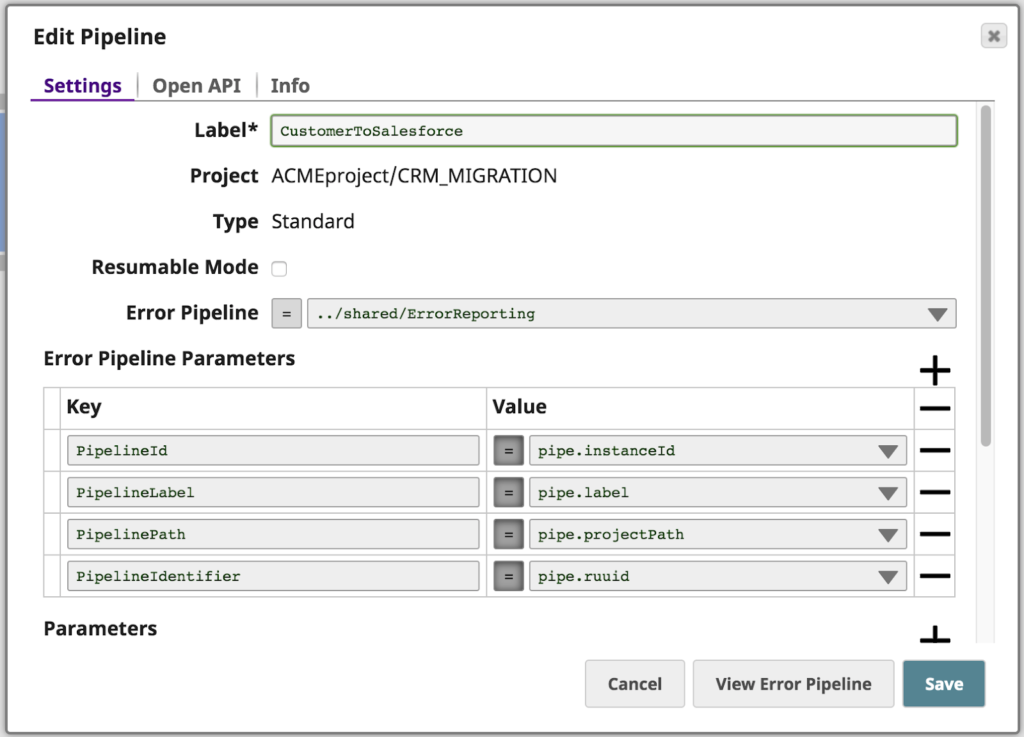
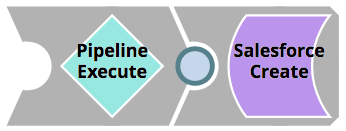
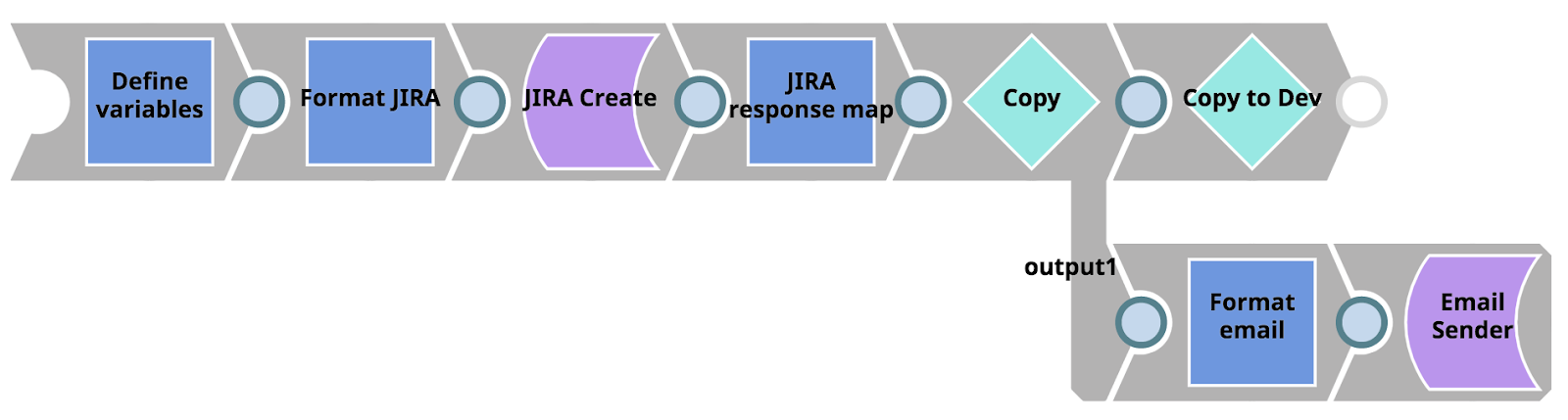
La pipeline degli errori può essere vista di seguito. In primo luogo, prende le informazioni sull'errore e i parametri della pipeline e li mappa nel file JIRA Crea snap. Quindi, prende la risposta da JIRA (in particolare l'URL del ticket JIRA risultante) e passa il documento a due rami utilizzando lo snap Copy. Il ramo superiore passa il documento a un'altra pipeline utilizzando lo snap Pipeline Execute Snap. Il ramo inferiore formatta le informazioni in un'e-mail HTML che viene inviata a Operazioni utilizzando lo snap Mittente e-mail.
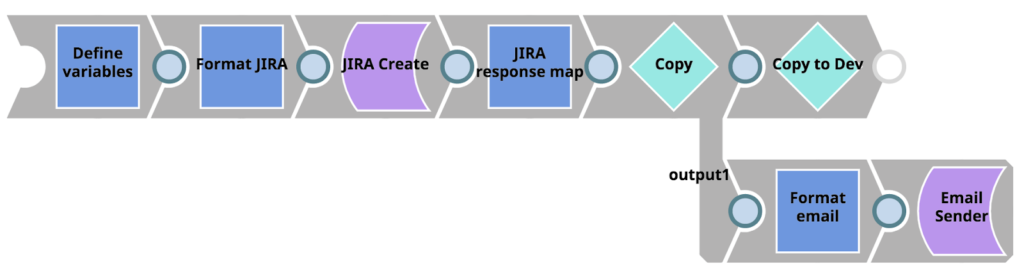
Per prima cosa, concentriamoci sulla pipeline figlia invocata dalla nostra pipeline Errore usando lo snap Esegui pipeline (etichettato come "Copia su Dev"). Semplicemente, questa pipeline sfrutta il pacchetto Metadata Snap Pack per elencare, recuperare, mappare e aggiornare le risorse tra il progetto in produzione e l'Issue Space nell'ambiente di sviluppo. sviluppo sviluppo. Al termine della pipeline, le copie esatte degli asset del progetto in cui si è verificato l'errore saranno disponibili per l'integratore. Integratore per iniziare a lavorare nell'ambiente di sviluppo org.
È importante non tentare di risolvere il problema nella cartella di produzione eludendo i processi e i controlli esistenti.

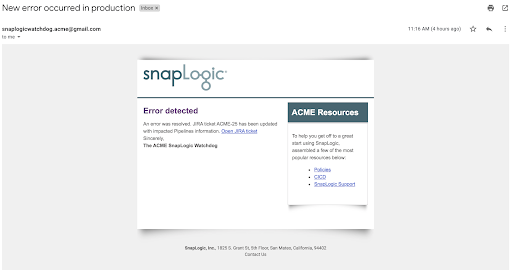
In secondo luogo, vediamo il risultato delle altre azioni intraprese dalla pipeline degli errori. L'immagine seguente mostra l'email che è stata inviata automaticamente a Operazioni. Essa cita alcuni link rilevanti, ma soprattutto rimanda al ticket JIRA generato automaticamente.
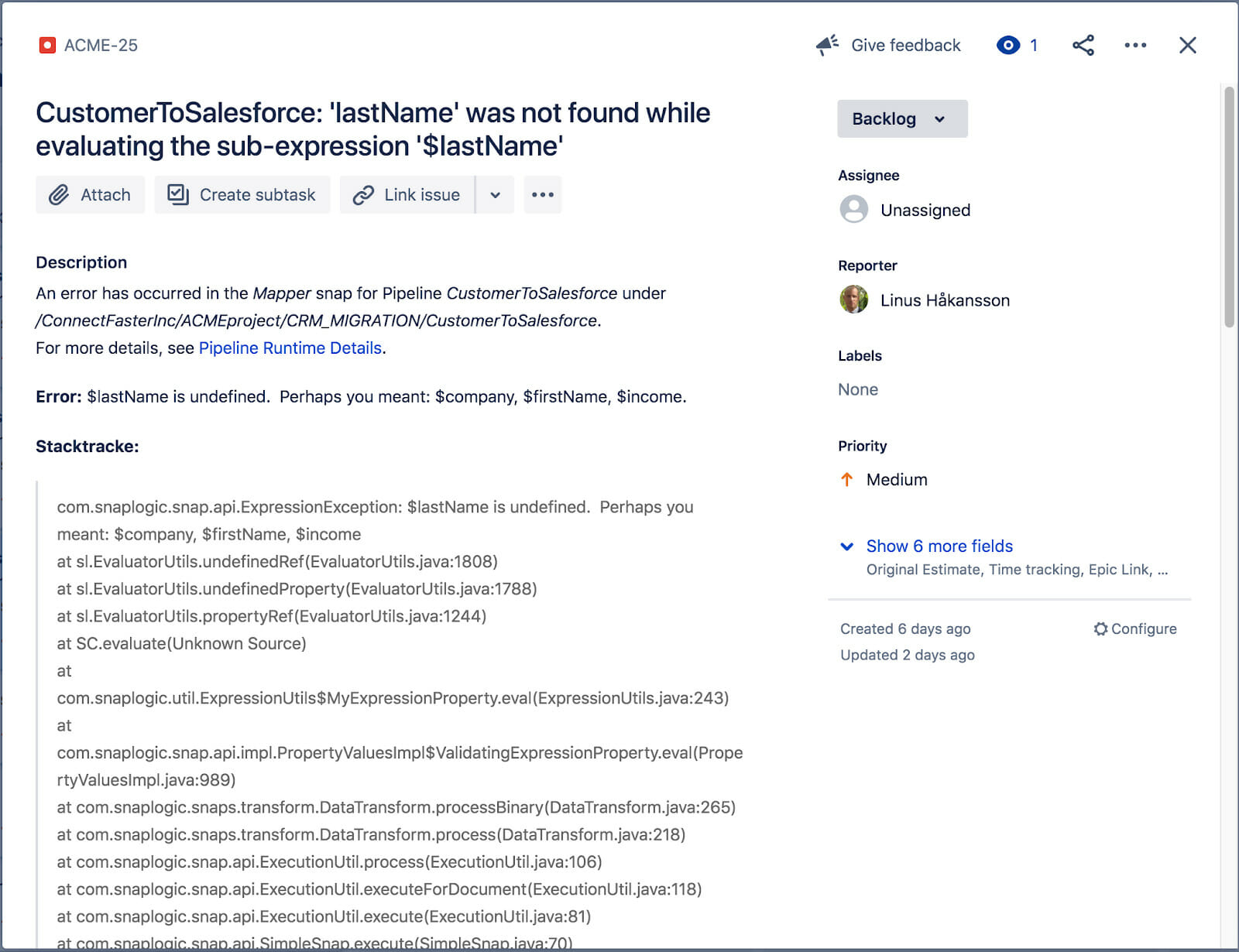
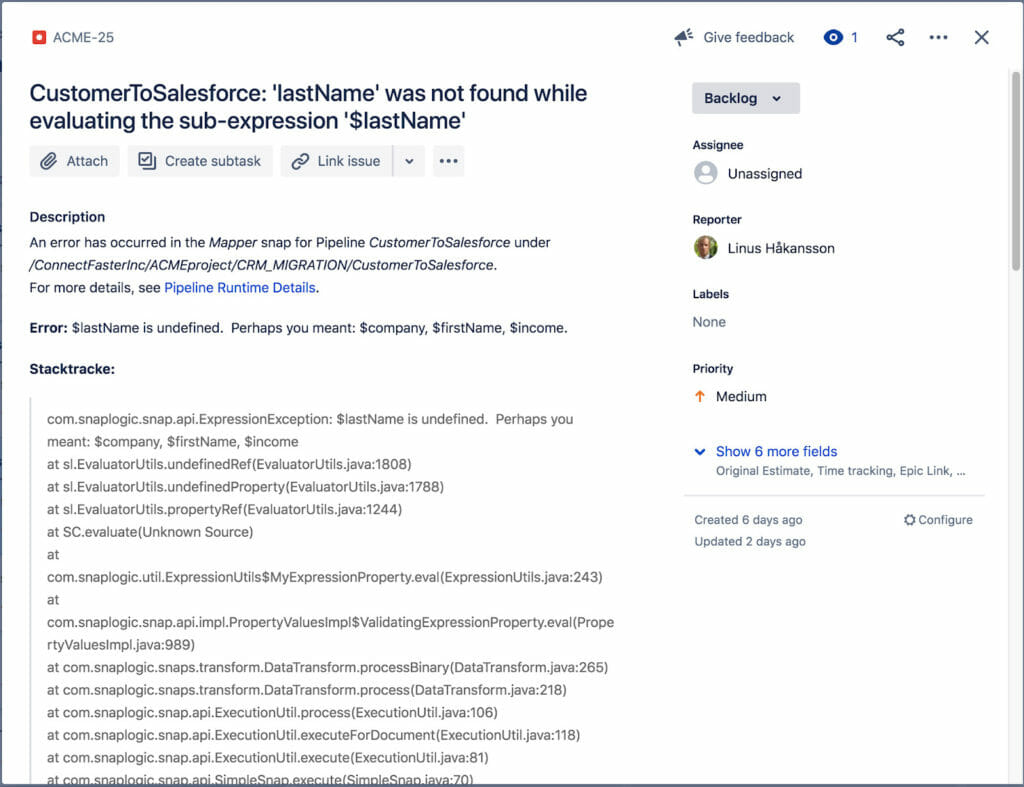
Il ticket JIRA collegato è visibile qui sotto. Include il titolo dell'errore, la descrizione, lo stacktrace, la risoluzione (non sullo schermo) e un link ai dettagli dell'esecuzione della pipeline in cui si è verificato l'errore. Il nostro Operazioni e Integratore avranno ora informazioni sufficienti per iniziare a risolvere il problema.
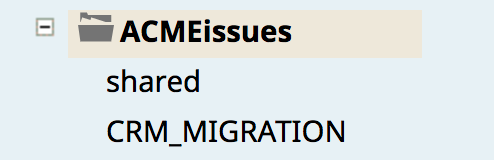
Infine, l'immagine seguente mostra la nuova copia di CRM_MIGRAZIONE (che contiene la pipeline CustomerToSalesforce e il task) che è stato copiato dalla cartella di produzione produzione all'ambiente di sviluppo dell'ambiente di sviluppo (ACMEissues).
Risoluzione dei problemi + test unitari + Git Push
Il nostro integratore è ora in grado di assegnare il problema ad alta priorità e di iniziare il suo lavoro. Poiché ora dispone di requisiti e linee guida di test adeguati da parte del suo Test leadcreerà anche dei test unitari per garantire che l'errore non si ripeta. Una volta terminato, userà la 'Gitlab Push Pipeline' per avere un nuovo commit spinto sul ramo Master di Git.
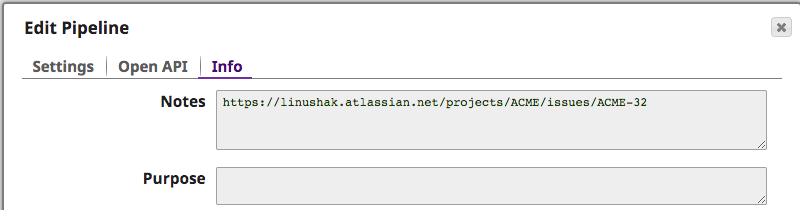
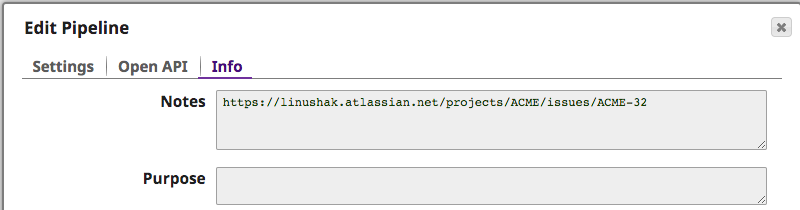
Per capire meglio quale errore ha causato il problema, l'integratore può ispezionare le note della pipeline copiata che ha causato il problema. Automaticamente, il ticket JIRA è stato inserito per fornire ulteriori informazioni, come si può vedere di seguito.
Il Responsabile dei test raccomanda la seguente logica per abilitare i test unitari per le pipeline.
Break out the logic into a separate Pipeline. This will not only make unit testing easier, but also enable reuse of components. This Pipeline should be called <Pipeline_name>_target. The original Pipeline should now instead have a Pipeline Execute Snap that executes the Pipeline housing the logic.
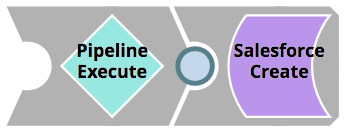
- Create a pipeline as <Pipeline_name>Prova che carica i dati di test ed esegue il task <Pipeline_name>_target Pipeline con questi dati. Quindi salva il risultato in un file separato.
- The test data should reside in a file as <Pipeline_name>_input.json
- The result data should be written to a file as <Pipeline_name>_result.json

Nota: le modalità di esecuzione dei test sono trattate in un passaggio successivo di questo post.
Il Integratore adatta la pipeline CustomerToSalesforce come sopra e crea le pipeline CustomerToSalesforce_target (per la logica) e CustomerToSalesforce_test (per leggere e salvare i dati di input/output). Per assicurarsi che le proprietà del cliente CRM richieste esistano e per risolvere efficacemente l'errore, adatta la pipeline logica come segue
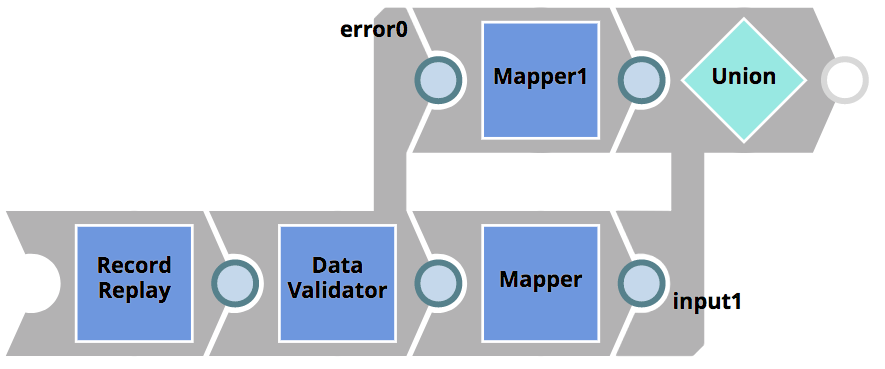
Il Validatore di dati Snap è usato per verificare l'esistenza delle proprietà richieste (ad es. nomeNome e cognome). Se i controlli non vengono superati, il documento viene indirizzato alla vista di errore prima di essere ritrasmesso al client. Con questa logica, il client CRM legacy avrà la possibilità di agire sull'errore.
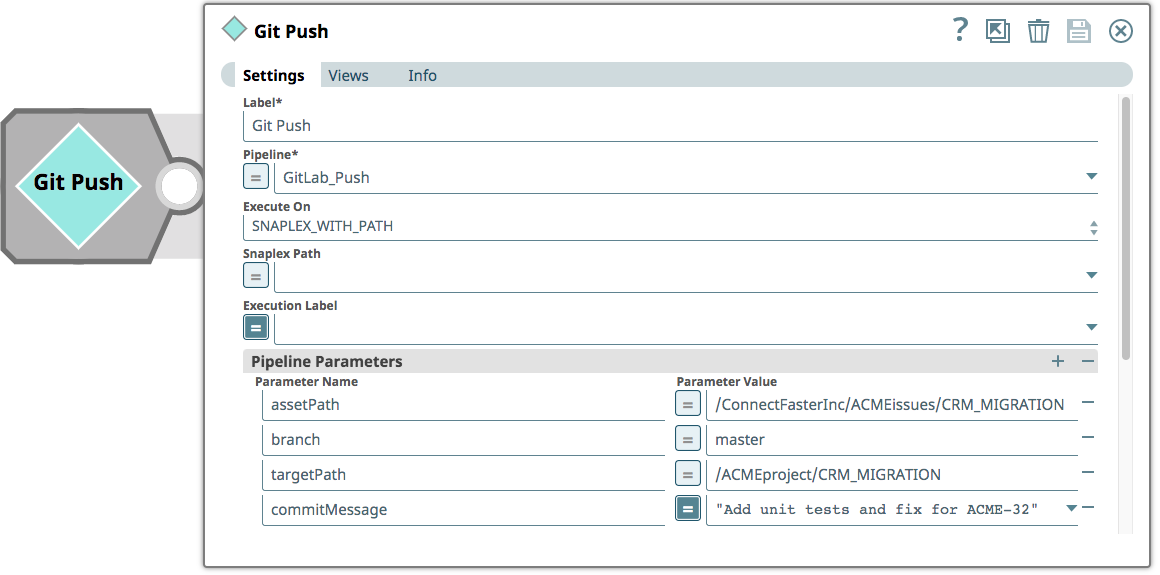
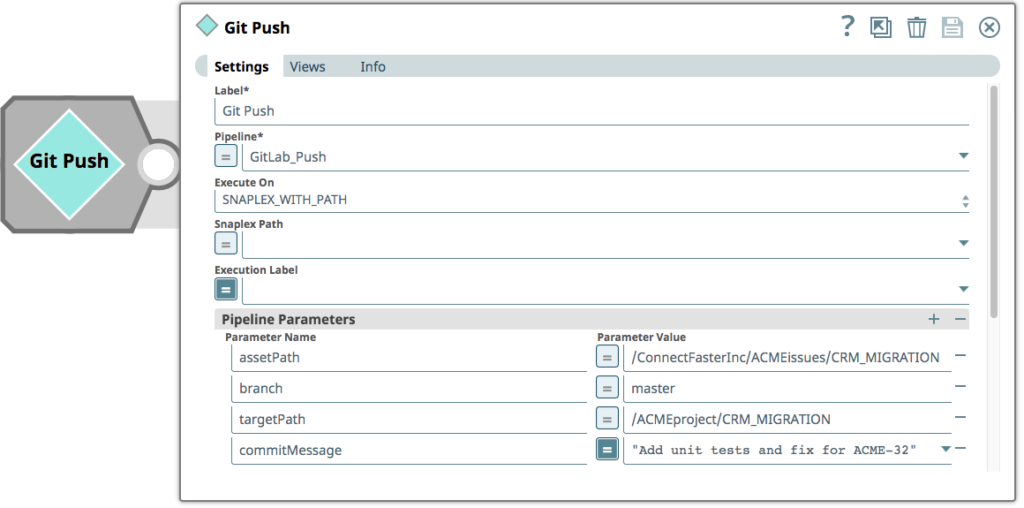
Infine, l'integratore invia le pipeline al ramo Master del repository GitLab. La pipeline usata per invocare il processo di push di un commit su GitLab consiste in un singolo Snap 'Pipeline Execute' che accetta i parametri per il percorso dell'asset (il progetto in cui cercare le modifiche), il ramo (nel repository GitLab), un percorso di destinazione (il progetto effettivo - il repository Git non contiene riferimenti agli ambienti) e un messaggio di commit - in questo caso riferito al numero del ticket JIRA.
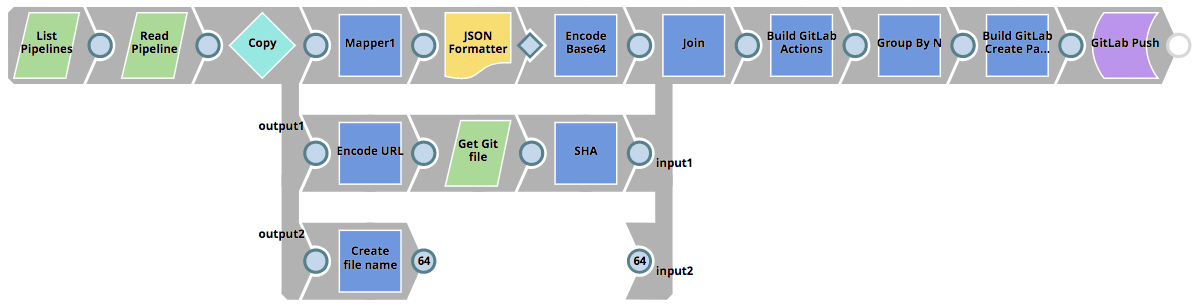
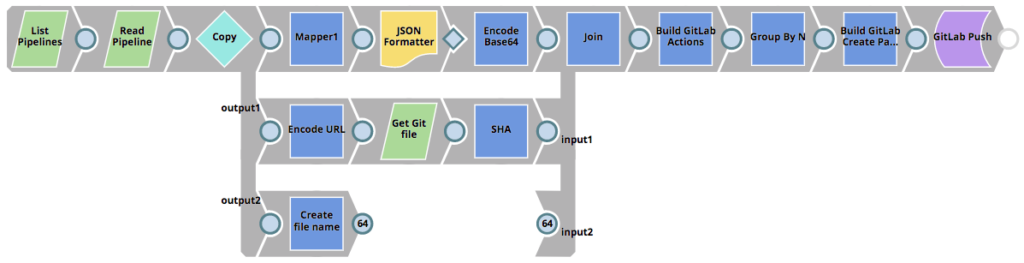
La pipeline GitLab_Push che viene invocata può essere vista di seguito. Legge tutte le pipeline del progetto selezionato, determina se le pipeline devono essere create nel repository Git o aggiornate (se esiste già un SHA) e quindi invia un commit a GitLab.
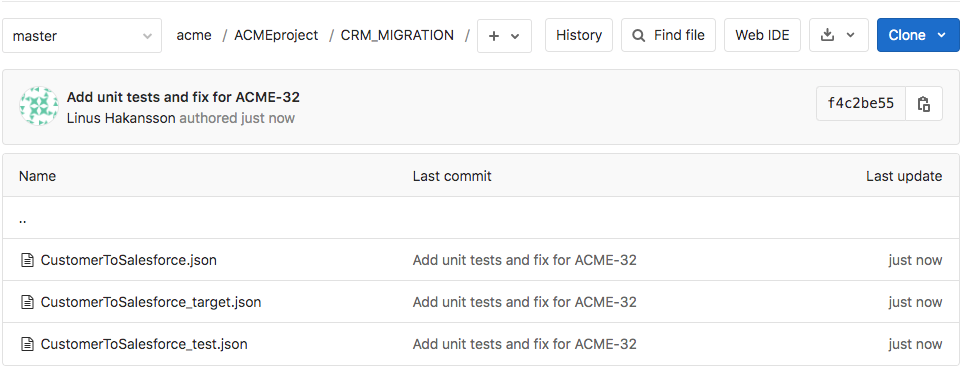
Il risultato dell'esecuzione della pipeline GitLab_Push si riflette nel repository GitLab come indicato nell'immagine seguente. Nell'immagine, il ramo Master è attualmente selezionato e il browser dei file sta visualizzando i file nella directory ACMEproject/CRM_MIGRATION. Le modifiche alla pipeline CustomerToSalesforce e le due nuove pipeline di test unitario sono state aggiunte al repository come parte del commit.
Consultate la seconda parte di questa serie, dove scoprirete le migliori pratiche per la gestione del ciclo di vita delle richieste di unione e la promozione delle modifiche all'ambiente di produzione per le vostre risorse di integrazione!