





La trasformazione dei dati riconcilia e standardizza i dati in modo che siano utili come unica fonte di "verità dei dati". Per decenni, il metodo di trasformazione e migrazione preferito è stato l'ETL (extract, transform, load). Le organizzazioni che utilizzano l'archiviazione dei dati on-premise spesso pagano un sovrapprezzo per lo spazio e la potenza di elaborazione extra, per cui era logico che pulissero e trasformassero i loro dati prima di caricarli sull'archiviazione.
Oggi, grazie all'ascesa dello storage cloud , abbiamo una seconda opzione: ELT (extract, load, transform). Le organizzazioni che sono passate a cloud non sono più vincolate dalle dimensioni e dalla potenza di elaborazione, quindi molte scelgono di trasformare i dati dopo averli caricati sullo storage.
Questo significa che l'ELT è il processo più favorevole? Spesso, ma non sempre. Continuate a leggere per conoscere le differenze funzionali tra i due processi ed esplorare le rispettive considerazioni e casi d'uso.
Che cos'è l'ETL?
ETL è l'acronimo di "Extract, Transform, and Load" (estrazione, trasformazione e caricamento) ed è il processo di estrazione dei dati da una o più fonti e il loro trasferimento in un ambiente di staging. Qui i dati vengono puliti e trasformati prima di essere caricati in un data warehouse per l'archiviazione e l'analisi.
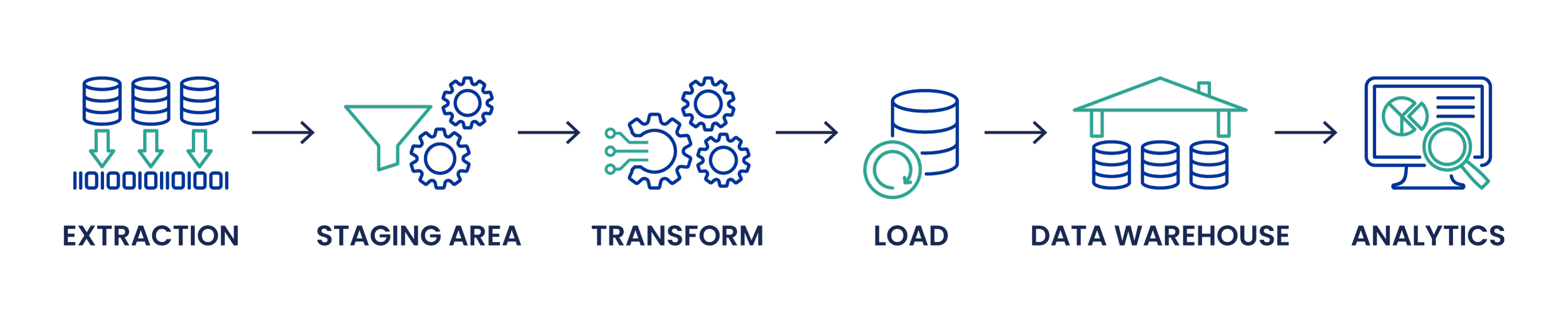
Ecco la ripartizione delle tre fasi dell'ETL:
Estratto
- I dati vengono estratti da una o più fonti e spostati in un'area di staging. I formati comuni delle fonti di dati includono database relazionali, XML, JSON e file piatti, ma possono includere anche database non relazionali come i sistemi di gestione delle informazioni.
- I dati vengono convalidati al momento dell'estrazione per garantirne l'accuratezza. I dati che non soddisfano le regole di convalida vengono rifiutati, quindi scartati o (idealmente) restituiti alla fonte per un'ulteriore diagnostica.
Trasformazione
- I dati convalidati vengono puliti nell'area di staging. Questa parte cruciale del processo di trasformazione dei dati prevede l'identificazione di dati corrotti, duplicati, irrilevanti, rumorosi o non rappresentativi e la loro sostituzione, modifica o eliminazione.
- Altre trasformazioni avvengono in modo che i dati possano essere memorizzati in una forma utile. Le trasformazioni più comuni comprendono l'ordinamento e il filtraggio, l'unione di dati provenienti da più fonti, la combinazione o la divisione di righe e colonne, la traduzione di valori codificati e l'esecuzione di calcoli di base. I dati sensibili vengono inoltre sottoposti a scrubbing, crittografia, riformulazione e protezione prima di essere esposti agli utenti aziendali.
Carico
- I dati vengono caricati sulla destinazione finale per essere archiviati. Per l'ETL, la destinazione finale è solitamente un data warehouse, ma può essere qualsiasi data store. Il processo di caricamento dei dati varia molto a seconda delle esigenze organizzative. Quelle che non si basano sui dati storici possono sovrascrivere i vecchi dati con le nuove informazioni, mentre altre potrebbero voler creare uno storico caricando i dati in forma storica a intervalli regolari.
- Anche i vincoli definiti all'interno del database possono essere attivati al momento del caricamento, filtrando ulteriormente i dati. Il database può filtrare i duplicati già presenti nel database, rifiutare i dati mancanti di campi obbligatori o eseguire altre azioni in base ai parametri impostati dall'organizzazione.
- I dati archiviati sono ora pronti per ulteriori analisi. Gli strumenti di analisi dei dati più diffusi sono Tableau, Microsoft Power BI e Qlik Sense.
L'obiettivo principale dell'ETL è quello di caricare dati puliti e coerenti nel magazzino. Il caricamento dei soli dati necessari libera spazio di archiviazione e potenza di elaborazione, quindi è una buona scelta per le organizzazioni che archiviano i propri dati in sede o utilizzano un'altra soluzione di archiviazione che non è scalabile. La maggior parte degli strumenti ETL tradizionali è orientata ai database on-premise.
Che cos'è l'ELT?
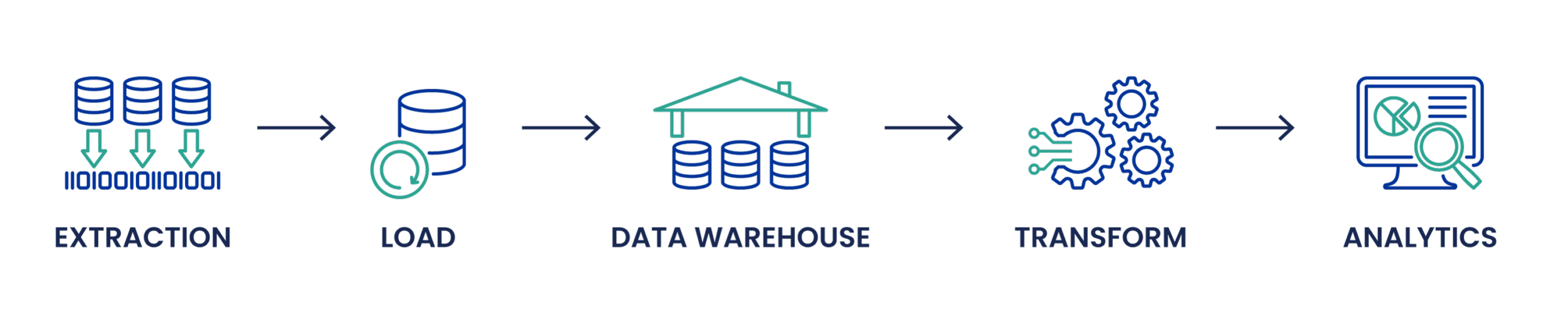
Nel processo di ELT, i dati vengono caricati in memoria prima che avvenga qualsiasi trasformazione.
ELT utilizza i data warehouse di cloud per caricare tutti i tipi di dati senza dover prima effettuare trasformazioni complesse. Questo processo è possibile grazie ai data lake, un tipo speciale di archiviazione in cui è possibile caricare qualsiasi informazione grezza. Una volta raggiunta la destinazione, i dati possono essere selezionati e trasformati secondo le necessità.
Con l'ELT, l'azienda acquisisce tutti i dati, indipendentemente dal fatto che li utilizzi o meno, per cui nessuno deve perdere tempo a trasformare dati che alla fine non saranno utili.
La velocità e la scalabilità di ELT sono rese possibili dalla moderna tecnologia dei server cloud . Utilizzando i data warehouse basati su cloud, le aziende ottengono capacità di archiviazione esponenziali e possono scalare drasticamente la loro potenza di elaborazione. Piattaforme come Amazon Redshift e Snowflake hanno capacità di elaborazione immense e rendono possibili le pipeline ELT.
L'ELT non funziona con i sistemi on-premise.
Estratto
- I dati vengono estratti da una o più fonti e spostati in un'area di staging. A differenza dell'ETL, in questa fase i dati non vengono sottoposti a un processo di convalida.
Carico
- I dati vengono immediatamente caricati nel loro formato grezzo nel data lake, dove saranno immagazzinati. Le soluzioni di storage cloud più diffuse sono Amazon Web Services, Cloudera, Google Cloud e Microsoft Azure.
Trasformazione
- I dati vengono trasformati in base alle necessità. In questo modo si risparmia tempo nel lungo periodo, perché non si applicano trasformazioni a dati che non servono.
Pro e contro di ETL vs. ELT
Quando si decide se l'ETL o l'ELT sono adatti alla propria organizzazione, i fattori principali da considerare sono il costo e la complessità dell'archiviazione dei dati. L'ELT è più veloce, in quanto si basa sullo storage cloud con data lake in grado di gestire un'enorme quantità di dati grezzi, non strutturati e semi-strutturati. Se si utilizza uno storage on-premise, l'ETL consente di evitare i costi di archiviazione dei dati non necessari.
Un'altra considerazione è la sensibilità dei dati grezzi. Nell'ETL, i dati sensibili possono essere mascherati o rimossi durante il processo di trasformazione. Nell'ELT, tutti i dati vengono inviati al magazzino, esponendo potenzialmente le organizzazioni a violazioni HIPAA, CCPA o GDPR. Tuttavia, è possibile proteggere i dati sensibili durante il processo di ELT con la crittografia e una corretta governance dei dati.
In definitiva, la scelta si riduce alle seguenti domande: Avete bisogno di essere selettivi riguardo ai dati che memorizzate (ETL)? Oppure siete disposti ad acquisire e memorizzare tutti i vostri dati, anche se non li utilizzate mai (ELT)?
Vantaggi dell'ETL
- Maggiore flessibilità - L' ETL consente trasformazioni più complesse e set di strumenti più ampi, riducendo al minimo i silos di dati e i lock-in per i dati trasformati.
- Conformità più facile - I set di dati sensibili possono essere redatti o crittografati, rendendo più facile soddisfare gli standard di conformità GDPR, HIPAA, CCPA e altri. Trasformando i dati prima che arrivino al data warehouse, si riduce notevolmente il rischio di esporre dati non conformi.
- Disponibilità più ampia - L'ETL esiste da 20 anni; ci sono numerosi strumenti ETL nello spazio dell'integrazione dei dati e la conoscenza dell'ETL è una competenza comune tra gli sviluppatori.
Sfide dell'ETL
- Processo più lento: l'ETL richiede un'ulteriore fase di caricamento dei dati in un'area di staging prima di elaborarli.
- Maggiore potenziale di errore umano - Dal momento che non si ingeriscono i dati e non li si carica direttamente nel magazzino, c'è un maggiore potenziale di caricamento di dati errati nel magazzino. Dal momento che non vengono effettuate trasformazioni dopo questo punto, i dati errati rischiano di essere utilizzati per l'analisi.
Vantaggi dell'ELT
- Disponibilità più rapida - L'ELT garantisce una disponibilità e un caricamento dei dati più rapidi per un'analisi più veloce.
- Maggiore attenzione - L'ELT è ideale per i set di dati più piccoli con trasformazioni semplici che hanno un impatto minimo sull'utilizzo dell'elaborazione del data warehouse cloud .
- Costi ridotti - L'ELT si basa su cloud e non richiede un hardware costoso e completo.
- Minore manutenzione - Il sistema ELT incorpora generalmente soluzioni automatizzate, per cui è necessaria una manutenzione molto ridotta.
- Più scalabile - Poiché l'ELT è flessibile e non è vincolato dalle dimensioni, la soluzione è facilmente scalabile.
Le sfide dell'ELT
- Può essere costoso - Gli strumenti e le risorse per l'ELT possono essere più costosi di quelli per l'ETL perché si elaborano più informazioni in meno tempo. L'ELT può anche richiedere maggiori competenze rispetto a una soluzione ETL, il che può richiedere l'assunzione di esperti di ELT.
ETL vs. ELT: un confronto a tutto campo
La tabella seguente mostra il confronto tra l'ETL e l'ELT in base a fattori chiave come i costi, la complessità e i tempi di manutenzione.
| Fattore/Considerazione | ETL | ELT |
| Dimensione del set di dati | Piccolo | Grande |
| Tempo - trasformazione | Richiede molto tempo, in quanto il processo di trasformazione deve essere completamente completato prima del caricamento. | Può richiedere meno tempo, poiché i dati possono essere trasformati in base alle esigenze. |
| Tempo - caricamento | Lento | Veloce, poiché i dati grezzi vengono caricati direttamente nel sistema di destinazione. |
| Tempo di manutenzione | Alta manutenzione | Bassa manutenzione, ma inizialmente può richiedere competenze aggiuntive |
| La privacy | Le riduzioni e le trasformazioni pre-caricamento mantengono la privacy dei dati | Sono necessarie maggiori tutele per la privacy |
| Tipi di dati supportati | Dati strutturati | Dati grezzi, non strutturati, semi-strutturati e strutturati |
| Supporto per il data lake | No, l'ETL non è compatibile con i data lake. | Sì, l'ELT è compatibile con i laghi di dati. |
| Supporto al magazzino dati | Utilizzato solo per dati relazionali on-premise | Utilizzato nell'infrastruttura cloud |
| Costo | I server separati possono creare problemi di costo, ma la minore complessità dei dati può compensare i costi. | Può essere costoso a seconda delle esigenze di elaborazione e di competenza, ma lo stack di dati semplificato può compensare i costi. |
ETL vs. ELT: qual è la scelta giusta per voi?
L'ETL e l'ELT sono entrambe soluzioni valide per la movimentazione e la trasformazione dei dati, ma si adattano meglio a casi d'uso aziendali diversi.
L'ETL può essere la soluzione migliore se:
- Non stanno utilizzando dati in tempo reale.
- Avere insiemi di dati più piccoli che non richiedono trasformazioni complesse.
- Deve ridurre il rischio di esporre dati non conformi.
- Utilizzare un database relazionale OLAP o un data warehousing SQL.
- Non è necessario passare dati non strutturati in un sistema di dati di destinazione.
- Sono disposti ad attendere lunghi tempi di caricamento.
L'ELT può essere la soluzione migliore se:
- Volete acquisire tutti i dati strutturati e non strutturati, indipendentemente dalle dimensioni, a cui la vostra azienda ha accesso.
- Acquisizione dei dati in tempo reale.
- Disporre delle risorse necessarie per gestire i data lake e assumere esperti di ELT.
- Disporre di un potente sistema di dati di destinazione basato su cloud per elaborare i volumi di dati in arrivo.
- Privilegiare il caricamento rapido dei dati.
Semplificare la migrazione dei dati con SnapLogic ELT
Processi di migrazione e trasformazione affidabili alimentano dati affidabili. Che si scelga l'ETL o l'ELT, la capacità di fidarsi dei dati e di accedervi prontamente è fondamentale per il successo dell'azienda. SnapLogic offre tutti questi metodi di spostamento e trasformazione dei dati in una piattaforma collaudata e potente basata su cloud che risponde alle esigenze e agli obiettivi specifici della vostra organizzazione.
L'iPaaS (integration platform as a service) di SnapLogic può aiutarvi a semplificare e automatizzare l'integrazione di dati e applicazioni. L'iPaaS utilizza endpoint API che consentono alle diverse applicazioni dell'organizzazione di condividere le informazioni attraverso un canale di comunicazione comune, consentendo flussi di lavoro più collaborativi.
Mentre la maggior parte delle soluzioni iPaaS può integrarsi con cloud, sistemi on-premise e ibridi, SnapLogic offre anche una soluzione ELT dedicata. SnapLogic ELT è una piattaforma low-code/no-code che offre la flessibilità di sfruttare la potenza di un data warehouse cloud per trasformare i dati. Lo strumento utilizza un linguaggio di programmazione visuale per caricare rapidamente i dati e trasformarli in loco. Allo stesso tempo, sfrutta la potenza di calcolo del data warehouse cloud per preparare i dati strutturati per l'analisi.
Con oltre 700 Snaps precostituiti, SnapLogic consente l'ingestione dei dati dagli endpoint delle applicazioni e dei dati. Nel frattempo, le funzionalità ELT della piattaforma gestiscono la trasformazione attraverso data warehouse cloud come Snowflake, Redshift, Azure Synapse, Google BigQuery e Databricks Delta Lake. Ciò consente alla piattaforma di estrarre dati sintetizzati da un data warehouse cloud a qualsiasi applicazione o endpoint di analisi, consentendo di ottenere maggiori informazioni sull'efficienza del carico, sul consumo di calcolo, sulle tendenze del volume di dati e altro ancora.
Ulteriori domande frequenti
1. In che modo la scelta tra ETL e ELT influisce sulla privacy e sulla conformità dei dati?
Nel contesto della privacy e della conformità dei dati, le organizzazioni che impiegano l'ETL devono concentrarsi sull'implementazione di solide misure di redenzione e crittografia durante il processo di trasformazione. È fondamentale definire e rispettare gli standard di conformità come HIPAA, CCPA o GDPR, assicurando che i dati sensibili siano gestiti in modo sicuro. Per quanto riguarda l'ELT, è necessario porre l'accento sulla crittografia e sulla protezione dei dati una volta caricati nel magazzino, considerando la potenziale esposizione di tutti i dati. La definizione di politiche complete di governance dei dati è essenziale per ridurre i rischi per la privacy sia nei processi ETL che ELT.
2. Quali sono le principali differenze in termini di competenze richieste per l'implementazione di soluzioni ETL e ELT?
Le competenze richieste per l'ETL riguardano principalmente la trasformazione dei dati, la gestione dei database e la conoscenza degli strumenti ETL. D'altro canto, l'ELT richiede competenze nella gestione dei data lake, dei data warehouse basati su cloud e nella comprensione delle moderne tecnologie dei server cloud . Le organizzazioni che optano per l'ELT dovrebbero considerare l'assunzione di esperti che abbiano familiarità con piattaforme cloud come Amazon Redshift, Snowflake o Microsoft Azure. Mentre le competenze in materia di ETL sono molto diffuse tra gli sviluppatori a causa della loro lunga presenza, l'ELT può richiedere un set di competenze più specializzate, con un impatto sui costi iniziali ma potenzialmente in grado di portare a una maggiore efficienza.
3. In che modo le organizzazioni dovrebbero decidere tra ETL e ELT in base alle caratteristiche dei loro dati?
Nel decidere tra ETL e ELT in base alle caratteristiche dei dati, le organizzazioni devono valutare fattori quali il volume dei dati, le esigenze di elaborazione in tempo reale e la natura del sistema di dati di destinazione. L'ETL è preferibile per le organizzazioni con insiemi di dati più piccoli, con esigenze di dati non in tempo reale e per quelle che utilizzano data warehousing on-premise o SQL. L'ELT è adatto a scenari in cui l'acquisizione di tutti i dati strutturati e non strutturati, l'elaborazione in tempo reale e il data warehousing basato su cloud sono prioritari. La comprensione dei casi d'uso specifici dei dati, dei requisiti di scalabilità e delle preferenze in termini di velocità di elaborazione guiderà le organizzazioni verso la scelta più adatta tra ETL e ELT.





