






Osservando il panorama di ciò che oggi viene definito uno stack di dati moderno, noi di SnapLogic ci chiediamo: le definizioni attuali sono abbastanza moderne?
È una domanda importante da porsi perché, quando si progetta un'architettura dei dati, le aziende vogliono essere lungimiranti e pensare alle loro esigenze di dati del futuro e non solo a quelle di oggi.
Pertanto, se non sono sufficientemente moderne, le aziende corrono il rischio di implementare una soluzione che potrebbe risultare insufficiente per le loro esigenze di dati in tutta l'azienda, di stallare con il passare del tempo (cioè di non essere a prova di futuro), di aumentare la complessità con più strumenti per compensare, di aumentare i costi e di rallentare il time-to-value dei prodotti di dati.
Cosa rende moderna un'architettura dei dati?
Di seguito è riportato un rapido riepilogo di ciò che si trova di solito quando si ricerca la definizione di uno stack di dati moderno o di un'architettura di dati moderna. Le architetture di dati moderne sono:
- Cloudnativo - ospitato in cloud per una rapida implementazione e una facile scalabilità
- Facilmente accessibile - per un'ampia gamma di utenti, al di là dell'IT o dell'ingegneria, per accedere ai dati
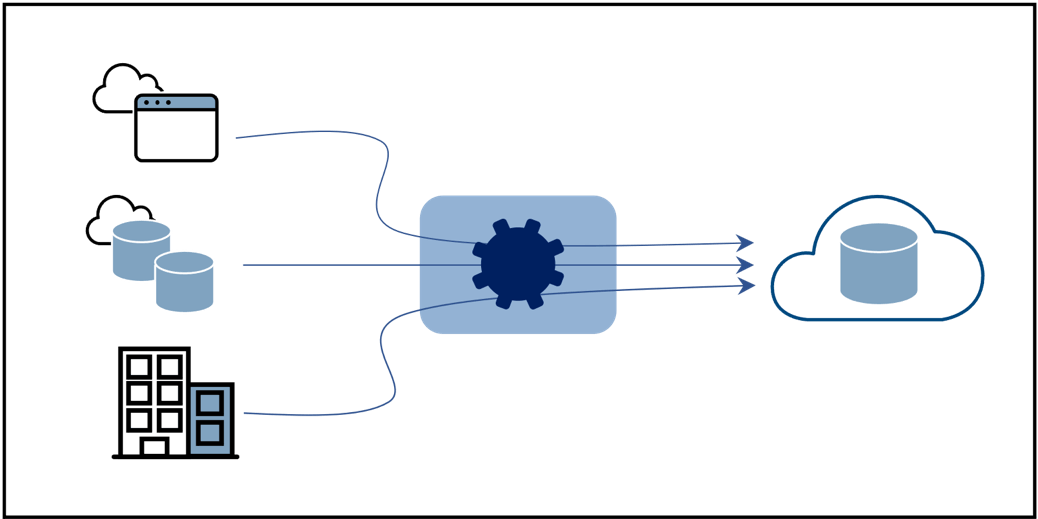
- Integrazione dei dati mirata: tutti i dati integrati vengono indirizzati a un data warehouse cloud , a una piattaforma dati cloud o a un data lake.
- Orientamento all'implementazione centralizzata: i casi d'uso dominanti sono legati all'analisi e alla business intelligence.
Sebbene si tratti di un elenco solido, con un diagramma a blocchi rappresentativo dell'architettura mostrato nella Figura 1, presenta limiti e rischi. Continua a leggere.
L'integrazione dei dati da sola non è abbastanza moderna - Combinate l'integrazione da app ad app
L'invio dei dati a un data warehouse cloud (CDW) o a una piattaforma di dati cloud , come BigQuery, Redshift, Snowflake e altri, o a un data lake aumenta certamente l'agilità, l'agilità e la capacità di scalare rapidamente i carichi di lavoro dell'analisi dei dati. La sfida è che, sebbene l'analisi dei dati sia un carico di lavoro dominante, non è l'unico carico di lavoro. Non tutti i casi d'uso sono centralizzati, soprattutto se si considera che il data mesh/data fabric continua a essere un argomento di discussione molto caldo tra gli architetti aziendali.
Inoltre, i carichi di lavoro analitici, per loro stessa natura, sono post-produzione e non operativi. I sistemi di dati operativi coinvolgono applicazioni che agiscono o condividono dati a livello di record (rispetto all'analisi di set di dati) più vicini al tempo reale. L'integrazione dei dati a colonne è ottima per l'analisi, ma non altrettanto per la condivisione dei dati operativi in tempo reale, da applicazione ad applicazione. L'integrazione basata sulle righe, che bypassa il CDW, tende a essere più veloce.
Carrie Craig, direttore delle applicazioni aziendali di WD-40 Company, afferma: "I dati del CRM vengono inviati direttamente al nostro sistema ERP tramite l'integrazione tra applicazioni SnapLogic, perché è più veloce e più semplice per i nostri scienziati dei dati aziendali accedere ai dati di cui hanno bisogno". Per noi è un vantaggio competitivo disporre di dati just in time per il processo decisionale".
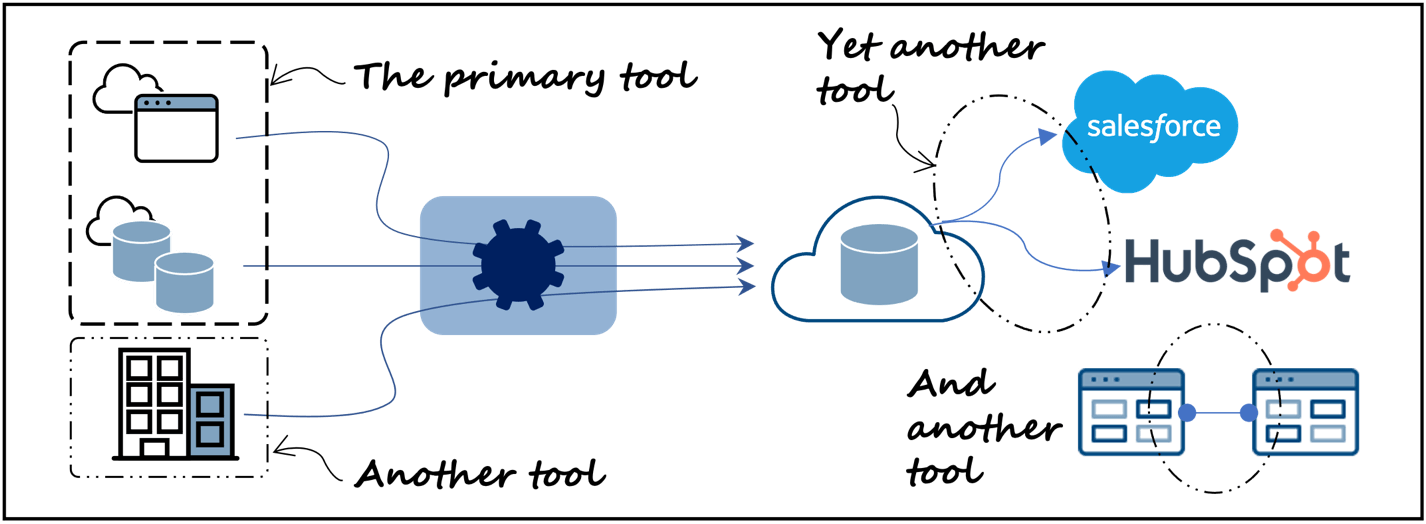
Per ottenere questo risultato, dovrete aggiungere un altro strumento di integrazione da app ad app (Figura 2, in basso a destra) al vostro stack se utilizzate strumenti di integrazione dei dati come Fivetran, Matillion, Informatica o simili. Ciò comporterà un aumento della complessità e potenzialmente dei costi.
Prodotti di dati moderni con sincronizzazioni bidirezionali - Senza complicazioni
Allo stesso modo, se siete un'organizzazione che produce prodotti di dati o un gruppo di analisi che arricchisce i dati, una volta che avete fatto le vostre cose all'interno del data warehouse o del data lake, potreste voler riportare il prodotto di dati o i dati arricchiti in un sistema o in un'applicazione operativa. Prendiamo ad esempio un caso d'uso che calcola il rischio di abbandono di un cliente. I dati dei clienti vengono estratti da un sistema CRM, come Hubspot o Salesforce, e poi caricati nel data warehouse per eseguire l'analisi del churning o altri arricchimenti. È bello che i dati sul rischio di abbandono dei clienti vengano poi riportati al sistema CRM per fornire un accesso coerente e un'esperienza di visualizzazione ai dirigenti e ai rappresentanti di vendita che desiderano ulteriori approfondimenti sui clienti. Si tratta di un'esperienza superiore e più facile per l'utente rispetto all'accesso al sistema CRM per una serie di esigenze e alla successiva richiesta separata all'IT o al team di analisi dei dati per accedere alle informazioni sul rischio di abbandono dei clienti.
Per completare un'operazione di questo tipo per questo caso d'uso sarà necessario scaricare i dati dal data warehouse e poi caricarli nuovamente nel sistema CRM, ovvero una sincronizzazione bidirezionale o un lavoro di reverse-ETL (extract, transform, load) in altre parole. La moderna architettura dei dati illustrata nella Figura 1 richiederebbe un altro strumento, come Hightouch, Census o Hevo, per eseguire questa operazione (Figura 2, in alto a destra). Ciò significa, come prima, aggiungere uno strumento, aumentare la complessità.
A dire il vero, alcuni strumenti di sola integrazione dei dati si sono evoluti per adattarsi ai casi d'uso bidirezionali/reverse-ETL. Tuttavia, è necessario guardare sotto il cofano per capire fino a che punto è supportata la sincronizzazione bidirezionale.
Gestite i dati residenti sia on-premise che su Cloud senza bisogno di strumenti aggiuntivi.
Una cosa è dire che uno stack di dati o un'architettura moderna è cloud-hosted, ma non significa (o, a nostro avviso, non dovrebbe) che i dati su cui si opera debbano trovarsi all'interno di cloud. Le moderne società finanziarie, le compagnie assicurative e le agenzie governative, ad esempio, hanno diverse esigenze e possono avere politiche di sicurezza che richiedono che i dati sensibili rimangano in sede. L'invio di dati sensibili all'indirizzo cloud per la manipolazione e il successivo ritorno a un repository in sede crea un rischio per la sicurezza.
Se uno strumento di integrazione dei dati o una piattaforma di dati ospitata su cloud ha difficoltà a raggiungere gli ambienti on-premise, a operare dietro un firewall e a eseguire operazioni sui dati che devono rimanere on-premise, sarà necessario un altro strumento (Figura 2, in basso a sinistra). Anche questo aggiunge complessità e può cambiare l'esperienza operativa.
Una soluzione migliore consiste nel separare il controllo di cloud dall'esecuzione on-premises all'interno dello stesso strumento di integrazione.
Diventare più moderni, eseguire più velocemente con meno debito tecnico e complessità
In questo blog ho rivelato tre aree in cui uno stack moderno orientato all'integrazione dei dati è carente e richiede strumenti aggiuntivi, che portano a un maggiore debito tecnico e a una maggiore complessità.
Spesso quando si parla di uno stack di dati o di un'architettura moderna, lo si fa dal punto di vista dell'integrazione dei dati. Ciò è intrinsecamente limitante se si considera la portata che uno stack o un'architettura di dati moderni devono avere per soddisfare le esigenze più ampie delle aziende moderne in tutte le loro imprese.
Per rendere la vostra architettura moderna più moderna, combinate l'integrazione da app ad app, la sincronizzazione bidirezionale dei dati e l'ETL inverso e le funzionalità di esecuzione dei dati on-premises all'interno della stessa piattaforma di integrazione, piuttosto che come strumenti individuali nella vostra architettura dei dati. I vantaggi sono la riduzione del debito tecnico, la riduzione della complessità, cioè la semplicità, e l'accelerazione del time-to-value delle integrazioni.
Considerate i commenti di Geoff Shakespeare, direttore operativo di National Broadband Ireland (NBI), un'azienda con un'ambiziosa iniziativa per collegare la banda larga ad ampie porzioni dell'Irlanda rurale: "Dopo aver esaminato una serie di soluzioni di integrazione, abbiamo organizzato un test di idoneità chiedendo ai fornitori di creare in una mattinata una funzionalità in grado di cercare un codice postale e di fornire un valore negativo o positivo sulla possibilità di distribuire la banda larga a quel codice postale. SnapLogic ha portato a termine il compito in due ore e mezza. Il time to market è di fondamentale importanza per questo progetto e SnapLogic ci ha aiutato a raggiungere gli obiettivi chiave".
È uscita la seconda parte di questa serie di blog! Trattiamo altre due aree importanti per rendere i vostri dati moderni più moderni.







