






I dati sono sempre più riconosciuti come la valuta aziendale dell'era digitale. Le aziende vogliono sfruttare i dati per ottenere approfondimenti che portino a un vantaggio competitivo rispetto ai colleghi. Secondo le proiezioni di IDC, il totale dei dati a livello mondiale raggiungerà i 163 zettabyte (ZB) entro il 2025, con un aumento di 10 volte rispetto alla quantità attuale. Questa potenziale miniera d'oro di dati digitali è pronta a scatenare una nuova era di innovazione, aprendo ulteriori flussi di entrate, potenziando i prodotti di nuova generazione e offrendo alle aziende le conoscenze necessarie per ottenere efficienza e aumentare la produttività. Questa esplosione di dati ha spinto le aziende ad andare oltre il mondo del data warehousing tradizionale e ad esplorare come costruire con successo dei data lake all'interno del sito cloud per accedere e analizzare i dati a cui non erano in grado di accedere in passato.
La chiave dell'innovazione è la gestione dei dati
La chiave per sbloccare tutta questa innovazione guidata dai dati sta nel modo in cui i dati vengono acquisiti, elaborati, gestiti e analizzati. Ma il volume, la varietà e la velocità dei dati di oggi rendono quasi impossibile che il data warehouse aziendale sia il centro di un'architettura di dati. Il data warehouse aziendale non ha le caratteristiche di scalabilità o di performance necessarie per gestire la marea di informazioni strutturate e non strutturate raccolte dalle applicazioni aziendali esistenti e provenienti da fonti in tempo reale come sensori, video, weblog e Internet of Things (IoT). Un data warehouse può gestire i dati non strutturati, ma non lo fa nel modo più efficiente. Con una tale quantità di dati in circolazione, archiviare tutti i dati in un data warehouse tradizionale può diventare molto costoso. Un data lake è un luogo in cui archiviare i dati strutturati e non strutturati, nonché un metodo per organizzare grandi volumi di dati altamente diversificati provenienti da fonti diverse. Il data lake tende a ingerire i dati molto rapidamente e a prepararli successivamente, al volo, man mano che le persone vi accedono.
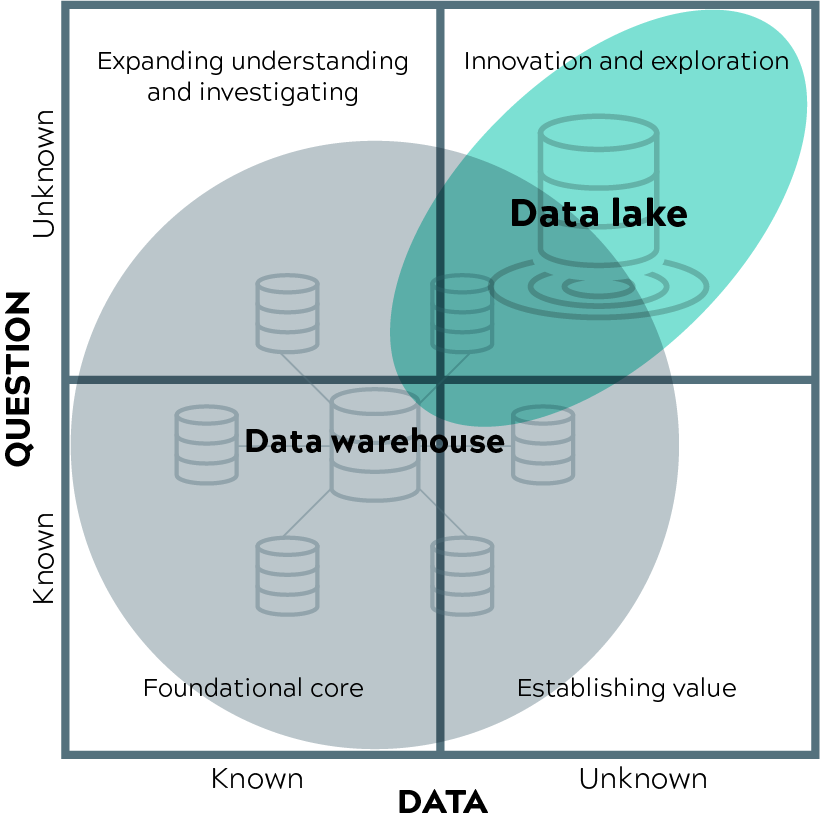
Ecco un quadro di riferimento ispirato da Gartner, per capire dove ha più senso un data warehouse tradizionale o un data lake. Dipende se si sa di cosa si ha bisogno e se i dati di cui si ha bisogno sono noti o meno.
Come si fa a stabilire se un data lake è in grado di rispondere alle sfide di gestione dei dati della propria organizzazione e come ci si prepara ad affrontarlo, se effettivamente è in programma? Ecco cinque domande da tenere a mente:
Qual è la composizione del mix di dati? Se le esigenze di business di un'organizzazione sono soddisfatte dall'aggregazione e dall'analisi di informazioni tabellari, per lo più strutturate, archiviate in sistemi basati sulle transazioni, come l'ERP (Enterprise Resource Planning), i data warehouse tradizionali sono probabilmente ancora l'approccio migliore. Tuttavia, se il mix di dati inizia a comprendere materiale non strutturato o addirittura semi-strutturato e, soprattutto, si accumula a un ritmo rapido (si pensi ai dati in tempo reale e in streaming), allora un data lake dovrebbe essere preso in considerazione come metodo più economico per gestire il volume su scala.
Esiste una strategia ben definita per il data lake? Gran parte dell'attrattiva di un data lake è il suo appetito quasi insaziabile per l'ingestione di tutti i tipi di dati e la flessibilità che si può conservare per un uso successivo senza necessariamente sapere cosa si vuole fare con essi. Allo stesso tempo, senza una strategia iniziale che comprenda la provenienza dei dati, i destinatari dei dati e alcune specifiche pratiche di governance, le organizzazioni IT potrebbero ritrovarsi al punto di partenza: Una serie di sistemi isolati che non soddisfano adeguatamente le esigenze del business e che non possono essere scalati in modo efficace.
Avete accesso immediato alle competenze sui big data? Le organizzazioni che dispongono di esperti di data warehouse e di analisti aziendali non sono necessariamente in grado di lavorare con l'universo dei big data, in particolare con i data lake. La familiarità con le nuove tecnologie open source come Hadoop, MapReduce, Flink, Flume, Kafka o Spark è ormai fondamentale, così come la necessità di ingegneri dei dati in grado di scrivere codice per elaborare i dati su scala utilizzando linguaggi di programmazione come Scala, Java e Python. C'è anche bisogno di data scientist in grado di utilizzare linguaggi di programmazione come Python e R per preparare i dati e costruire modelli analitici per ottenere approfondimenti. Oltre a questo nuovo gioco di tecniche e strumenti, le organizzazioni devono anche riorientare le pratiche di gestione dei dati per abbracciare metodologie agili e massimizzare i vantaggi di un'architettura di data lake.
Quali sono i vincoli temporali da considerare? I dati che vengono inseriti in un data warehouse aziendale devono essere puliti e preparati prima di essere archiviati. E con i dati non strutturati di oggi che vengono generati in vari formati grezzi a un ritmo rapido, può essere un processo arduo arrivare alle fasi di pulizia e preparazione quando non si è nemmeno del tutto sicuri di come i dati verranno utilizzati. Il data lake è progettato per gestire i dati non strutturati nel modo più conveniente possibile, dove i livelli di calcolo e di storage possono essere scalati indipendentemente in modo elastico. Con un approccio di tipo data lake, gli utenti possono inserire i loro dati il più rapidamente possibile, in modo da poter affrontare i casi d'uso operativi di reporting, analisi e monitoraggio aziendale.
Come affronterete le esigenze di integrazione dei dati? Un rapporto di Cap Gemini sul payoff dei big data ha identificato le sfide di integrazione come uno dei principali ostacoli al successo dei big data (citato dal 35% degli intervistati). Un altro rapporto di TDWI ha rilevato che la mancanza di strumenti di integrazione dei dati costituisce un ostacolo al successo dell'implementazione dei data lake per il 32% degli intervistati. Prima di procedere, è necessario definire una roadmap per l'acquisizione e l'integrazione dei dati che si adatti in modo ottimale al nuovo paradigma.
Il data warehouse aziendale continuerà a rimanere un componente mission-critical di una moderna architettura dei dati aziendali (MEDA), ma ora dovrebbe essere visto come un'applicazione "a valle", una destinazione, ma non il centro dell'universo dei dati. I laghi di dati, pur non essendo una panacea, hanno un enorme potenziale non solo per consentire a un pubblico più ampio di accedere a dati che in passato non erano in grado di raggiungere, ma anche per supportarlo in modo economicamente vantaggioso. Non basta saltare sull'ultimo carrozzone high-tech, ma è necessario porsi le domande giuste e fare tutte le considerazioni del caso per assicurarsi che un data lake sia l'approccio giusto per le esigenze di dati della propria organizzazione.






