





I volumi di dati stanno aumentando in modo esponenziale e molte organizzazioni iniziano a rendersi conto della complessità del movimento dei dati e delle soluzioni di gestione degli stessi.. I dati esistono in vari sistemi e ricavarne un valore significativo è diventata una sfida importante per molte aziende. Inoltre, la maggior parte dei dati è solitamente archiviata in sistemi relazionali come MySQL, PostgreSQL e Oracle, che sono i database mainstream utilizzati principalmente per scopi OLTP. Anche i sistemi NoSQL come Cassandra, MongoDB e DynamoDB sono emersi con un modello di consistenza sintonizzabile per archiviare alcuni di questi dati mission critical. I clienti spostano poi questi dati su sistemi molto più grandi, come Teradata e Hadoop (OLAP), in grado di memorizzare grandi quantità di dati, in modo da poter eseguire analisi, report o query complesse. Recentemente si è diffusa anche la tendenza a spostare alcuni di questi dati su cloud, in particolare su Amazon RedShift o Snowflake e anche su HDInsights o Azure Data Warehouse.
Se parliamo delle tendenze precedenti e attuali del flusso di dati tra i vari sistemi, ecco come si presenta la situazione:
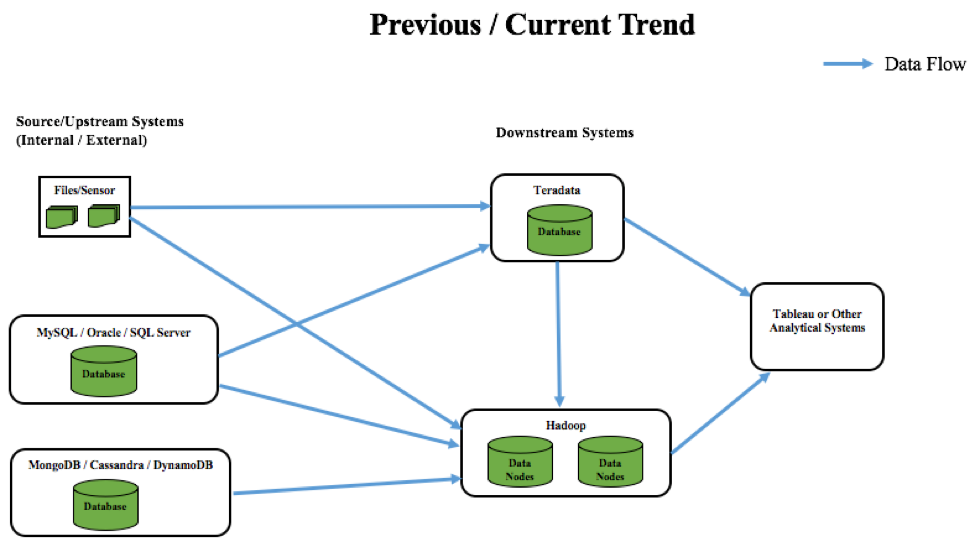 A titolo di esempio: Pensate a un importante settore alimentare o alla vendita al dettaglio. Il modo tradizionale di analizzare i modelli/tendenze di acquisto consisteva nell'archiviare i dati in file piatti o database operativi, per poi spostarli in un sistema di data warehouse basato su cloud come Teradata (tendenza precedente). Questo processo era più che altro un'operazione orientata al batch, senza approfondimenti in tempo reale. Ad esempio, la ricezione di coupon da parte dei clienti che fanno acquisti in questi settori si basava esclusivamente su ricerche e raccomandazioni storiche. Alcuni di questi coupon potevano essere rilevanti per molti acquirenti, ma il più delle volte non lo erano.
A titolo di esempio: Pensate a un importante settore alimentare o alla vendita al dettaglio. Il modo tradizionale di analizzare i modelli/tendenze di acquisto consisteva nell'archiviare i dati in file piatti o database operativi, per poi spostarli in un sistema di data warehouse basato su cloud come Teradata (tendenza precedente). Questo processo era più che altro un'operazione orientata al batch, senza approfondimenti in tempo reale. Ad esempio, la ricezione di coupon da parte dei clienti che fanno acquisti in questi settori si basava esclusivamente su ricerche e raccomandazioni storiche. Alcuni di questi coupon potevano essere rilevanti per molti acquirenti, ma il più delle volte non lo erano.
Se si considerano le tendenze attuali, i dati stanno esplodendo a livello globale. Di conseguenza, aumenta anche il numero di sistemi (sensori, ecc.) per catturarli, per cui sono emersi sistemi NoSQL scalabili per archiviare questi insiemi di dati variegati. Questi tipi di insiemi di dati in costante aumento devono essere trasferiti in sistemi scalabili e a basso costo per l'analisi. È qui che i big data si sono evoluti e gli utenti hanno iniziato a spostare i dati su Hadoop invece che su Teradata, soprattutto per motivi di costo. Tutti questi sistemi vengono poi integrati con strumenti di BI come Tableau per la visualizzazione dei dati. Con questa configurazione, il settore alimentare e della vendita al dettaglio è in grado di inviare rapidamente i dati a diversi sistemi e di analizzarli al volo con un rapido ciclo di feedback. Questo porta a un approccio efficiente incentrato sul cliente e alla stampa di coupon basati su una combinazione di acquisti recenti o precedenti.
Se parliamo di tendenze future nel flusso di dati tra i vari sistemi, ecco come si possono prevedere:
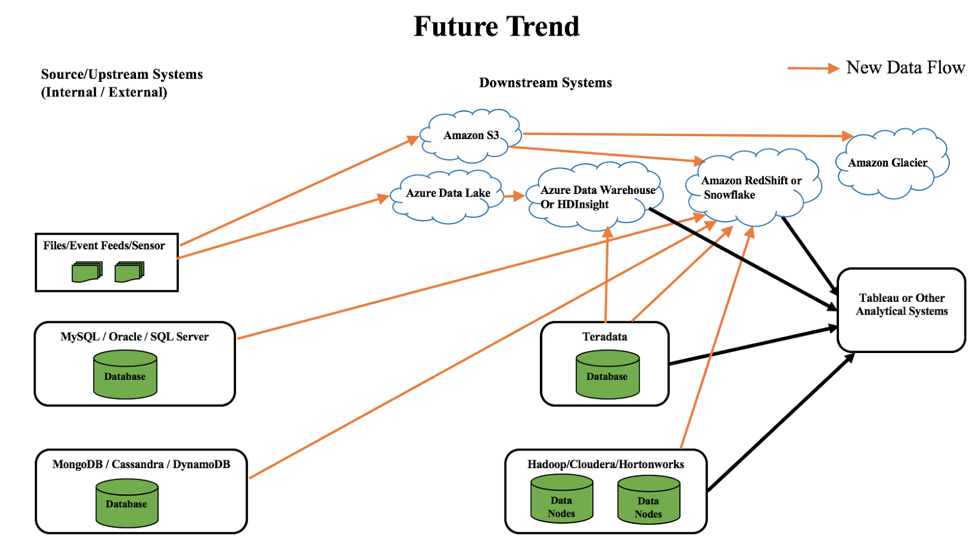
Come si vede nel diagramma precedente, cloud è destinato a rimanere e sta diventando più importante che mai. I clienti stanno lentamente spostando i dati su cloud, in modo da ridurre la manutenzione dell'infrastruttura, i costi e altre complessità interne. Alcune delle tendenze future dei dati includono:
- Spostamento dei dati da sistemi operativi e NoSQL a Redshift o Snowflake
- Spostamento dei dati da Teradata a Hadoop su cloud come HDInsights o Azure Data Warehouse.
- Spostamento dei dati da sensori/flussi di eventi ad Azure Data Lake o Amazon S3. In seguito, si potrebbe utilizzare Amazon Glacier per archiviare i dati freddi o usati di rado.
Nel complesso, lamovimentazione dei dati è diventata fondamentale in tutti questi sistemi per ricavare il valore del core business. Ciò richiede un ulteriore sforzo di sviluppo ETL se effettuato manualmente. Ma Snaplogic rende davvero semplice per gli utenti spostare i dati verso sistemi diversi, sia per le applicazioni che per i database/magazzini di dati (on-premises o cloud), costruendo pipeline attraverso connettori precostituiti chiamati Snaps, senza alcuno sforzo di codifica. Con un semplice meccanismo di trascinamento fornito dalla piattaforma scalabile di Snaplogic, i clienti possono facilmente costruire pipeline con gli Snaps pertinenti e spostare i dati da vari sistemi in modo da poterne ricavare rapidamente il valore aziendale. Questi Snaps eseguono anche la trasformazione, la pulizia o il wrangling dei dati, in modo che i sistemi a valle possano ottenere i dati desiderati che possono aiutare i risultati di business.
Di seguito sono riportate alcune pipeline SnapLogic per le tendenze attuali e future:

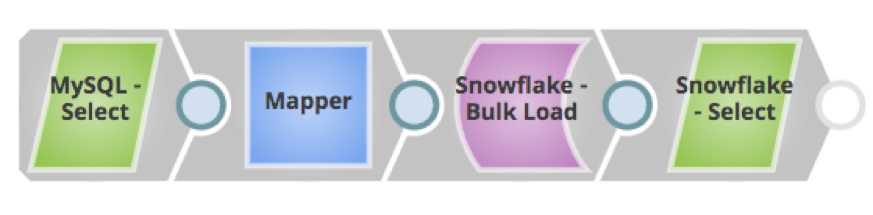 In sintesi, cloud diventerà mainstream in quanto sempre più aziende vi sposteranno i dati, grazie ai vari vantaggi e alle flessibilità qui menzionati. La piattaforma cloud di SnapLogic è in prima linea per favorire questo processo.
In sintesi, cloud diventerà mainstream in quanto sempre più aziende vi sposteranno i dati, grazie ai vari vantaggi e alle flessibilità qui menzionati. La piattaforma cloud di SnapLogic è in prima linea per favorire questo processo.





