





 Da Sharath Punreddy
Da Sharath Punreddy
Come probabilmente sapete, le pipeline di dati SnapLogic utilizzano gli Stream, un flusso continuo di dati da un'origine a una destinazione. Elaborando ed estraendo preziose informazioni dai dati di streaming, un utente/sistema può prendere decisioni più rapidamente rispetto all'elaborazione batch tradizionale. L'analisi dei dati in streaming fornisce ora analisi quasi in tempo reale, se non addirittura in tempo reale, compresa l'analisi delle API in streaming di Twitter.
In quest'epoca guidata dai dati, la tempestività dell'analisi dei dati e degli approfondimenti è diventata un fattore di differenziazione fondamentale. In alcuni casi, i dati diventano meno rilevanti, se non addirittura obsoleti, man mano che invecchiano. L'analisi dei dati nel momento in cui affluiscono è fondamentale per casi d'uso quali l'analisi del sentimento per il lancio di nuovi prodotti nel settore della vendita al dettaglio, il rilevamento di transazioni fraudolente nel settore finanziario, la prevenzione dei guasti alle macchine nel settore manifatturiero, l'elaborazione dei dati dei sensori per le previsioni meteorologiche, le epidemie nel settore sanitario, ecc. L'elaborazione dei flussi consente di elaborare in tempo quasi reale, se non addirittura in tempo reale, consentendo all'utente o al sistema di trarre spunti dai dati più recenti. Oltre alle API tradizionali, le aziende forniscono API di streaming per il rendering dei dati in tempo reale mentre vengono generati. A differenza delle API ReST/SOAP tradizionali, le API di streaming stabiliscono una connessione al server e trasmettono continuamente i dati per il periodo di tempo desiderato. Una volta trascorso il tempo, la connessione viene terminata. Apache Spark con Apache Kafka come piattaforma di Streaming è diventato uno standard di settore de facto per l'elaborazione dei flussi.
In questo post del blog, illustrerò i passaggi per la creazione di una semplice pipeline per recuperare ed elaborare le analisi di Twitter streamingAPI. Potete anche vedere il video esplicativo qui.
Flussi di Twitter
Twitter è diventato una fonte di dati primaria per l'analisi del sentiment. Le API di Twitter Streaming forniscono l'accesso ai Tweet globali e possono essere consultate in tempo reale mentre le persone twittano. Lo Snap "Twitter Streaming Query" di Snaplogic consente agli utenti di recuperare i Tweet in base a una parola chiave presente nel testo del Tweet. I tweet possono poi essere elaborati utilizzando Snap come Filter Snap, Mapper Snap o Aggregate Snap, rispettivamente per filtrare, trasformare e aggregare. SnapLogic offre anche uno Snap "Spark Script" che consente di eseguire un programma Python esistente sui Tweet in arrivo. Con l'analisi delle API di streaming di Twitter, i tweet possono anche essere indirizzati a diverse destinazioni in base a una condizione, copiati su più destinazioni (RDBMS, HDFS, S3, ecc.) per essere archiviati e analizzati ulteriormente.
Come iniziare
Di seguito è riportata una semplice pipeline per recuperare i tweet, filtrarli in base alla lingua e pubblicarli su un cluster Kafka.
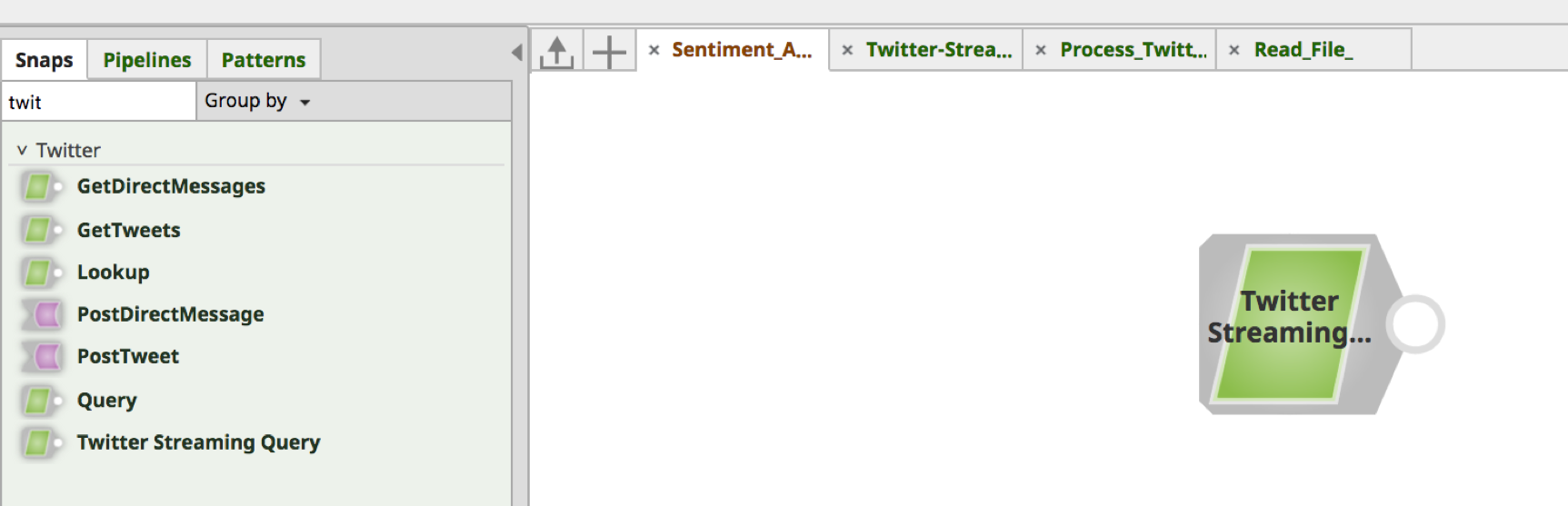
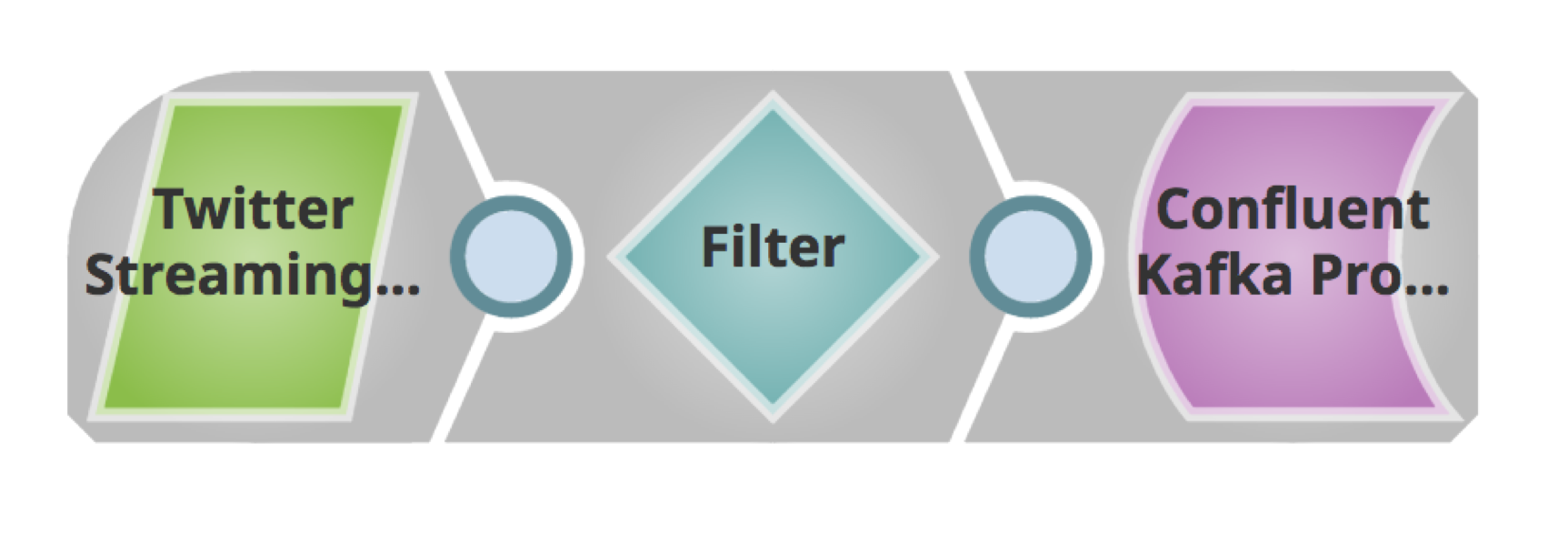 Utilizzando la scheda Snap nel riquadro di sinistra, cercare lo Snap. Trascinare e rilasciare lo snap sull'area di disegno del Designer (spazio bianco a destra).
Utilizzando la scheda Snap nel riquadro di sinistra, cercare lo Snap. Trascinare e rilasciare lo snap sull'area di disegno del Designer (spazio bianco a destra).
 a. Fare clic sullo snap per aprire il modulo Impostazioni snap.
a. Fare clic sullo snap per aprire il modulo Impostazioni snap.
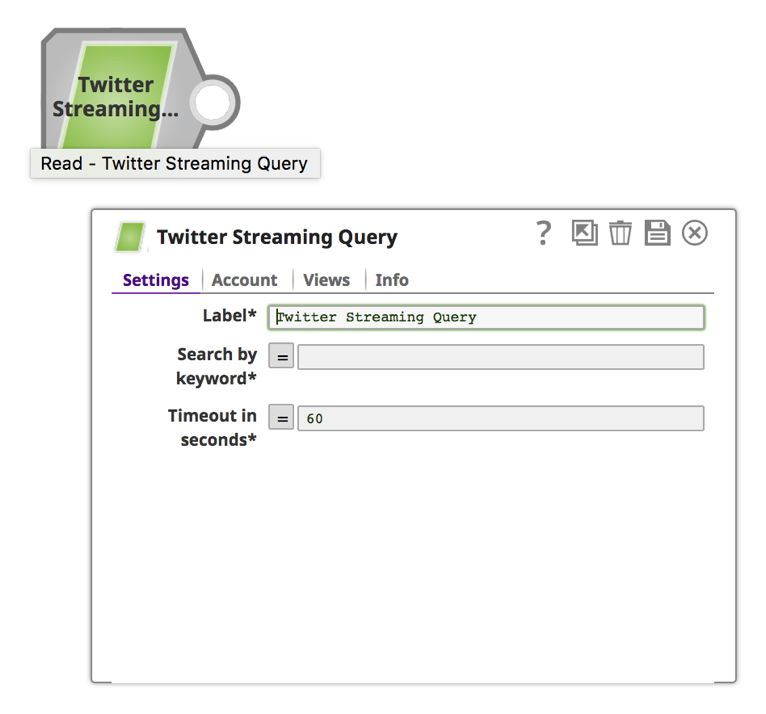 Nota: Lo snap "Twitter Streaming Query", e quindi l'analisi dell'API di streaming di Twitter, richiede un account Twitter, che può essere creato tramite Designer durante la creazione della pipeline o tramite Manager prima della creazione della pipeline.
Nota: Lo snap "Twitter Streaming Query", e quindi l'analisi dell'API di streaming di Twitter, richiede un account Twitter, che può essere creato tramite Designer durante la creazione della pipeline o tramite Manager prima della creazione della pipeline.
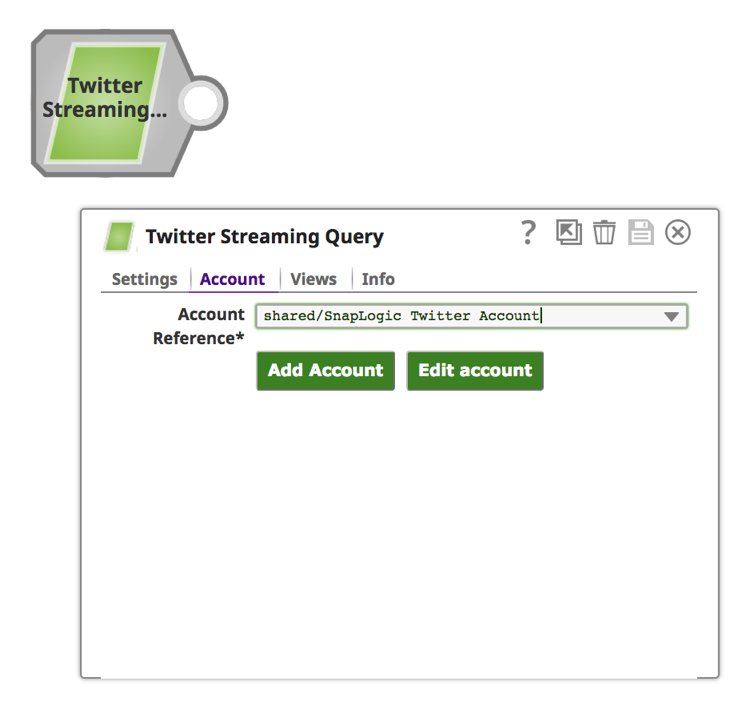
b. Fare clic sulla scheda "Account".
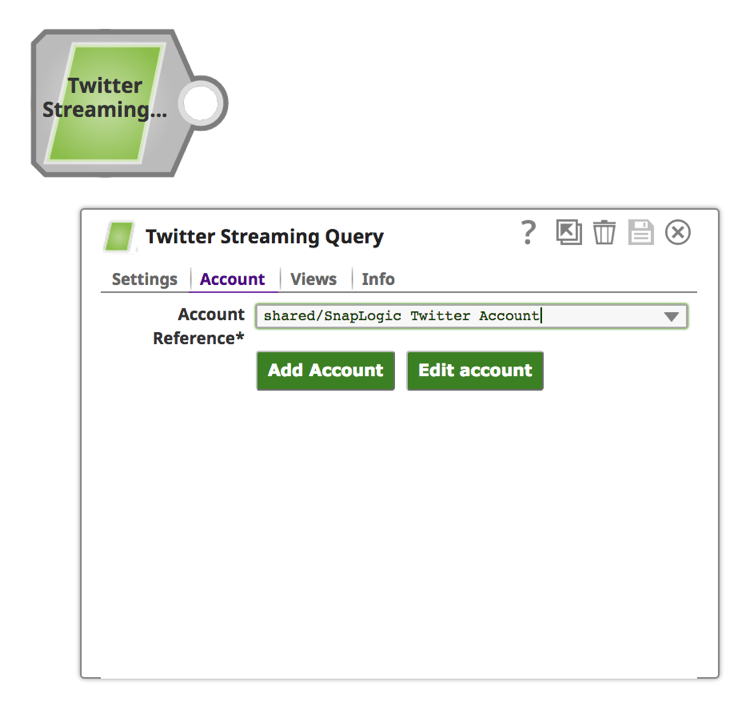 c. Fare clic sul pulsante "Aggiungi account".
c. Fare clic sul pulsante "Aggiungi account".
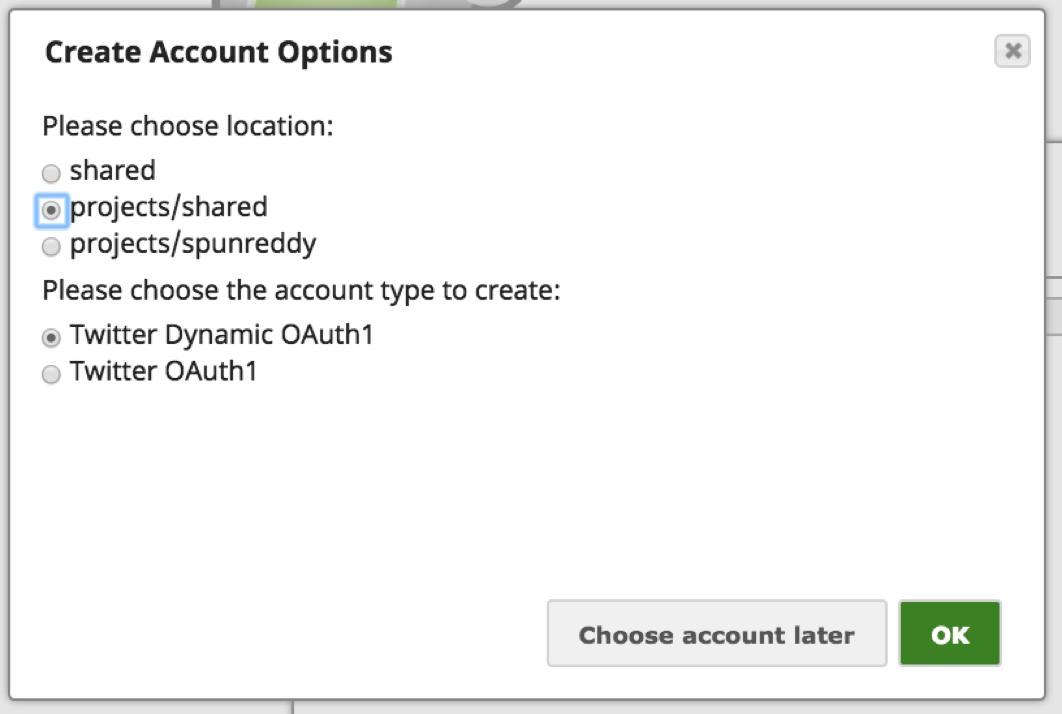 Nota: Twitter offre un paio di modalità di autenticazione applicazioni all'account Twitter. Il "Twitter Dynamic OAuth1" è per Autenticazione solo per le applicazioni e "Twitter OAuth1" è per Autenticazione utente in cui all'utente viene richiesto di autenticare l'applicazione tramite l'accesso a Twitter. In questo caso, utilizziamo il meccanismo di autenticazione dell'utente.
Nota: Twitter offre un paio di modalità di autenticazione applicazioni all'account Twitter. Il "Twitter Dynamic OAuth1" è per Autenticazione solo per le applicazioni e "Twitter OAuth1" è per Autenticazione utente in cui all'utente viene richiesto di autenticare l'applicazione tramite l'accesso a Twitter. In questo caso, utilizziamo il meccanismo di autenticazione dell'utente.
d. Scegliere un'opzione appropriata in base all'accessibilità dell'Account:
i. Per la posizione dell'account: Condiviso rende l'account accessibile a tutta l'organizzazione, "progetti/condiviso" rende l'account accessibile a tutti gli utenti del progetto e "progetto/" rende l'account accessibile solo all'utente.
ii. Per il tipo di account: Scegliere l'opzione "Twitter OAuth1" per garantire l'accesso all'account Twitter del singolo utente.
iii. Fare clic su "OK".
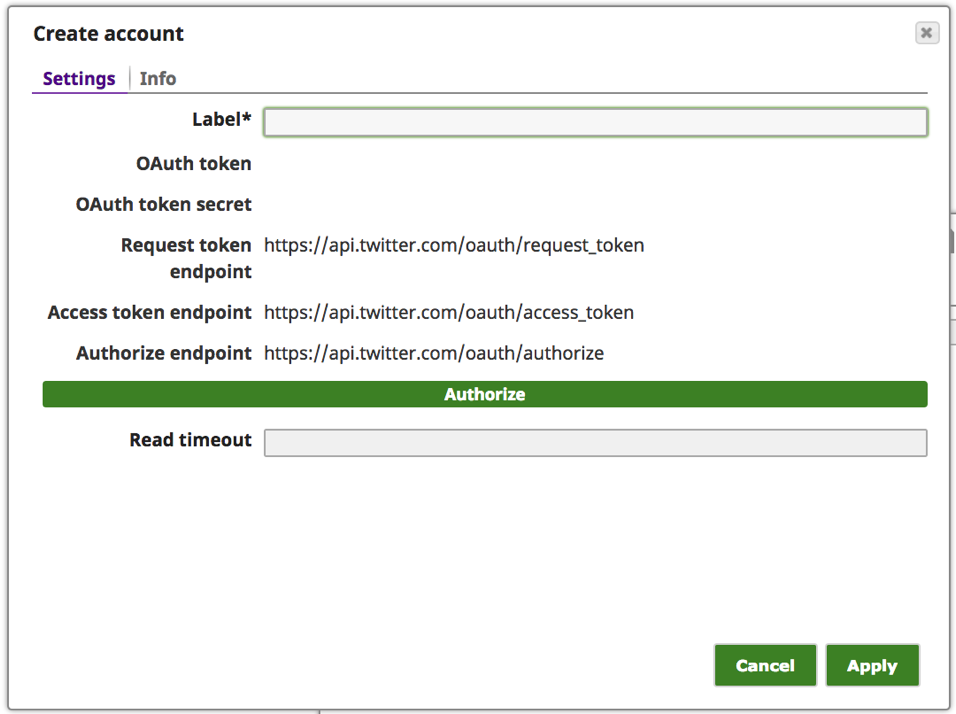
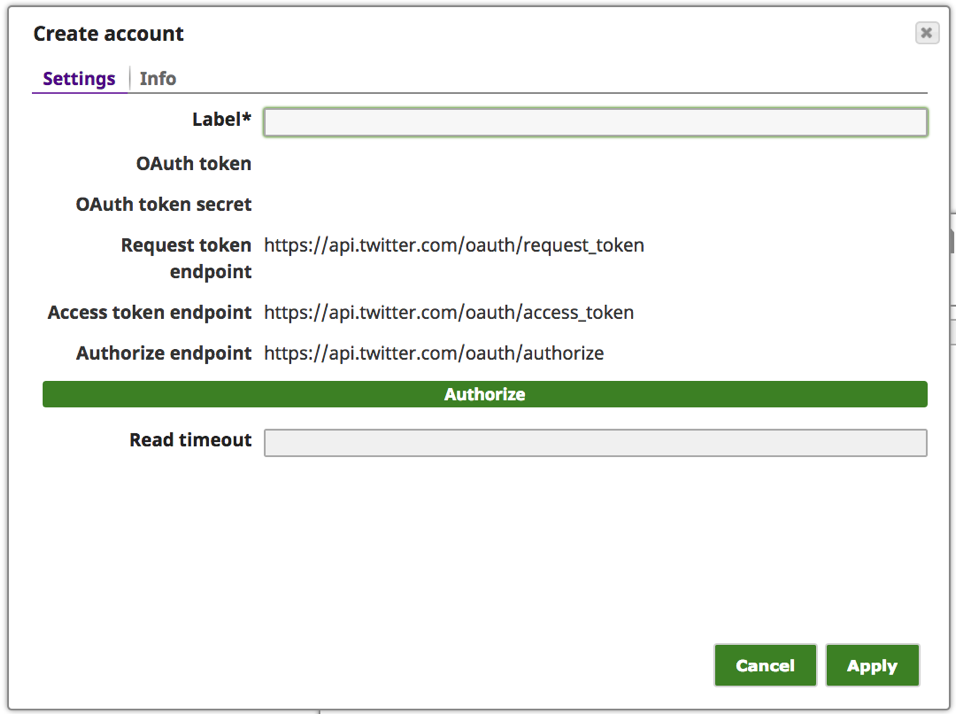 e. Inserite un testo significativo per l'"Etichetta", ad esempio [Twitter_di_] e fate clic sul pulsante "Autorizza".
e. Inserite un testo significativo per l'"Etichetta", ad esempio [Twitter_di_] e fate clic sul pulsante "Autorizza".
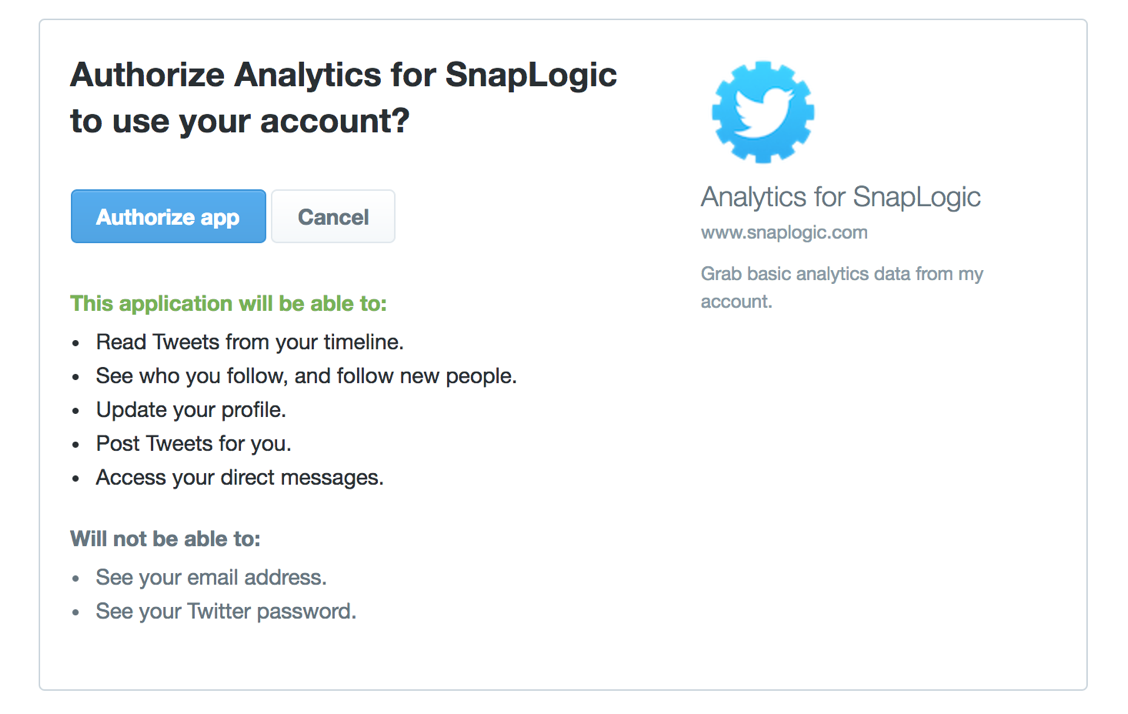 Nota: Se l'utente ha effettuato l'accesso a Twitter con una sessione attiva, verrà portato alla pagina "Autorizza" del sito web di Twitter per consentire all'utente di accedere all'applicazione. Se l'utente non ha effettuato l'accesso o non ha una sessione attiva, verrà portato alla pagina di accesso di Twitter per effettuare l'accesso.
Nota: Se l'utente ha effettuato l'accesso a Twitter con una sessione attiva, verrà portato alla pagina "Autorizza" del sito web di Twitter per consentire all'utente di accedere all'applicazione. Se l'utente non ha effettuato l'accesso o non ha una sessione attiva, verrà portato alla pagina di accesso di Twitter per effettuare l'accesso.
f. Fare clic sul pulsante "Autorizza app".
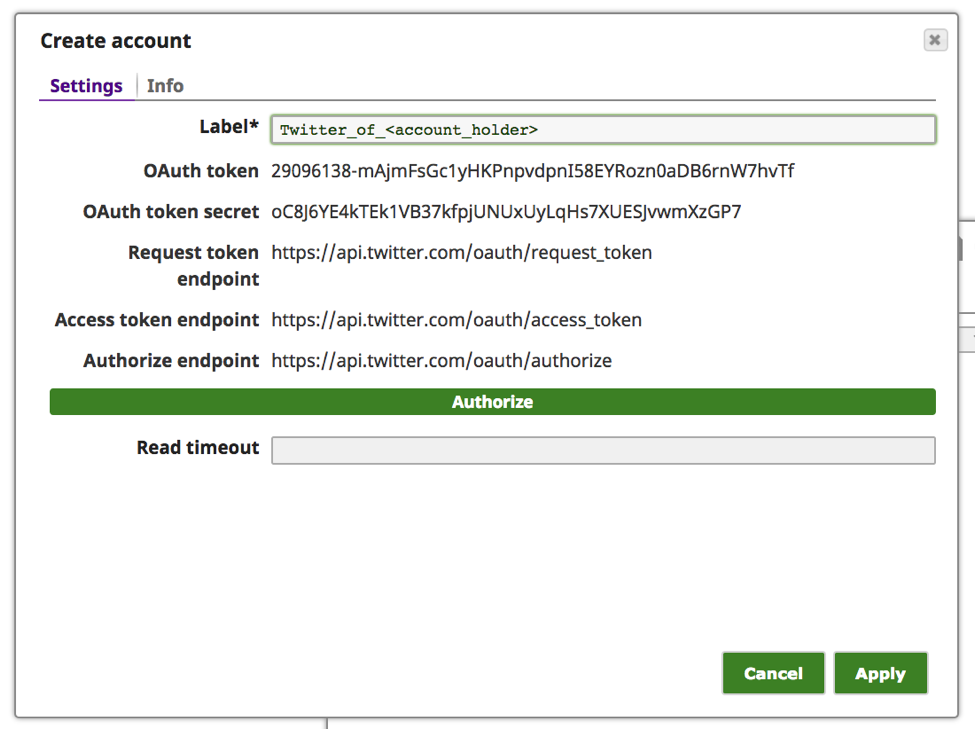 Nota: I valori "OAuth token" e "OAuth token secret" di cui sopra non sono attivi e sono solo a titolo di esempio.
Nota: I valori "OAuth token" e "OAuth token secret" di cui sopra non sono attivi e sono solo a titolo di esempio.
g. A questo punto, il "token OAuth" e il "segreto del token OAuth" dovrebbero essere stati compilati. Fare clic su "Applica".
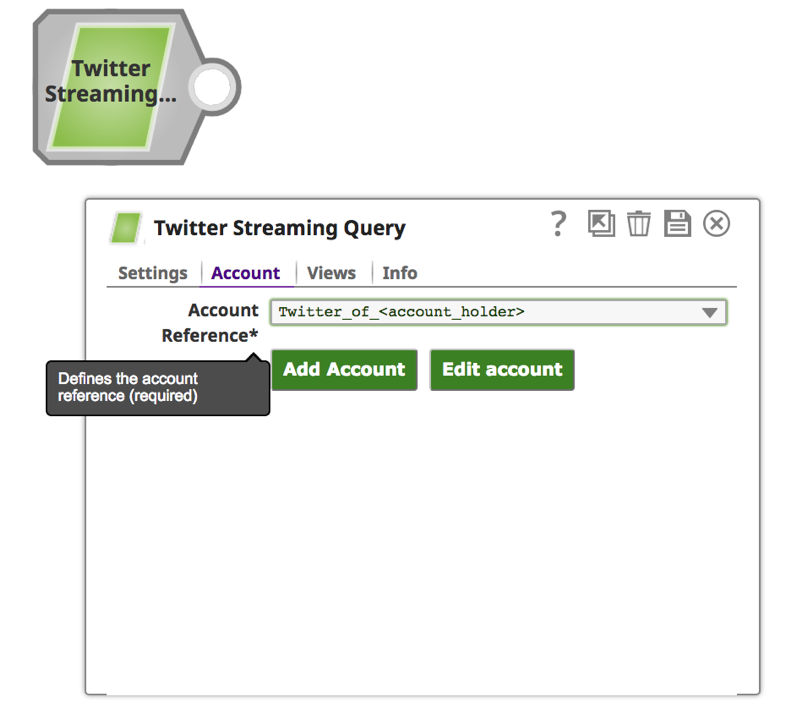 2. Una volta che l'account è stato configurato con successo, fare clic sulla scheda "impostazioni" per fornire la parola chiave e l'ora della ricerca.
2. Una volta che l'account è stato configurato con successo, fare clic sulla scheda "impostazioni" per fornire la parola chiave e l'ora della ricerca.
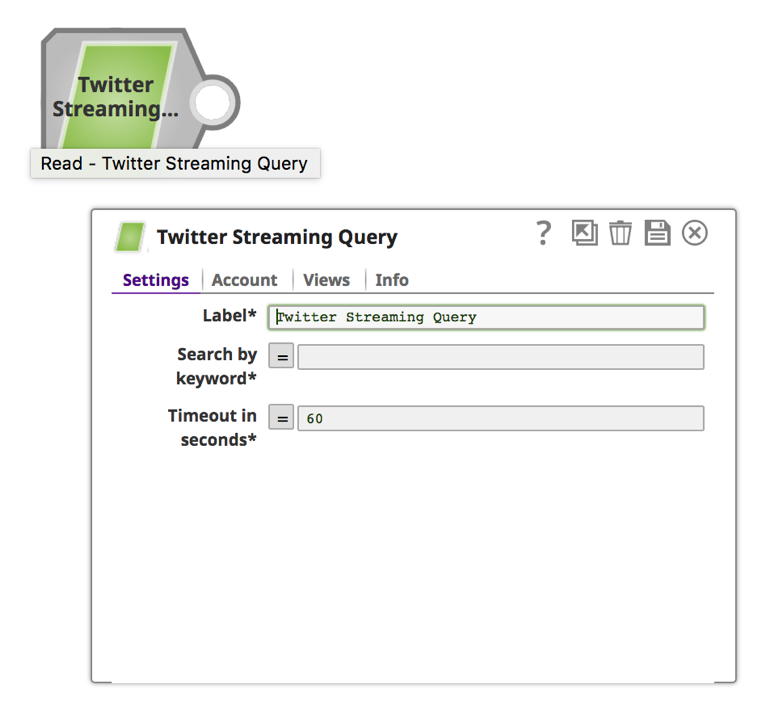 Nota: Twitter Snap recupera i tweet per un periodo di tempo prestabilito. Per un recupero continuo, è possibile fornire un valore di "0" a "Timeout in secondi".
Nota: Twitter Snap recupera i tweet per un periodo di tempo prestabilito. Per un recupero continuo, è possibile fornire un valore di "0" a "Timeout in secondi".
a. Immettere una parola chiave e una durata in secondi.
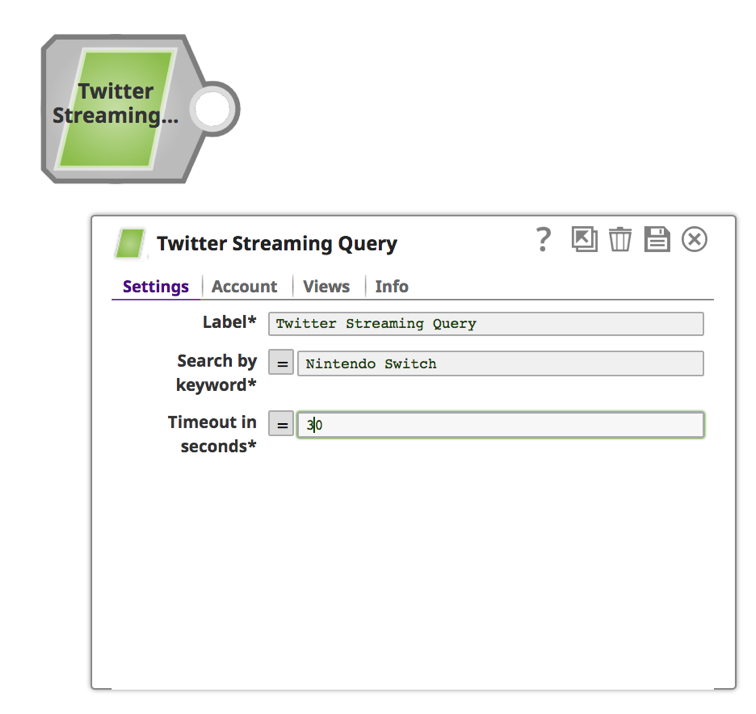
3. Salvare facendo clic sull'icona del disco in alto a destra. ![]() . La convalida viene attivata e dovrebbe diventare un segno di spunta.
. La convalida viene attivata e dovrebbe diventare un segno di spunta. ![]() se la convalida ha esito positivo.
se la convalida ha esito positivo.
4. Cliccare sull'elenco ![]() per visualizzare l'anteprima dei dati.
per visualizzare l'anteprima dei dati.
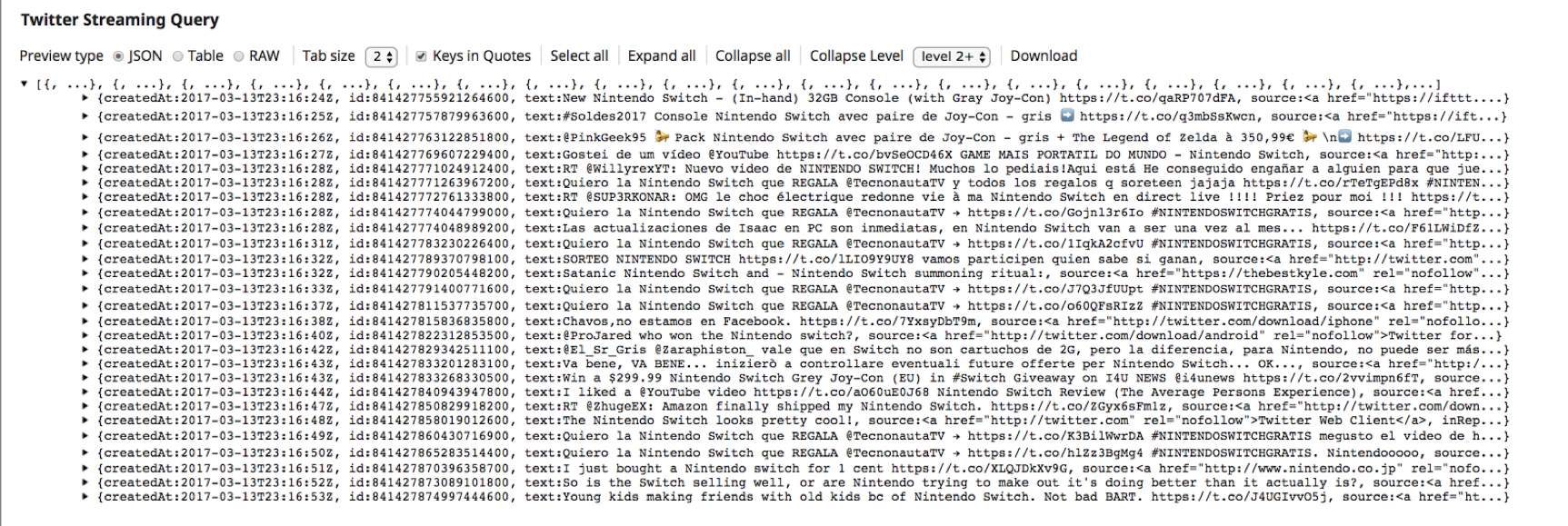 5. Questo conferma che lo snap "Twitter Streaming Query" ha stabilito con successo la connessione all'account Twitter e sta recuperando i tweet.
5. Questo conferma che lo snap "Twitter Streaming Query" ha stabilito con successo la connessione all'account Twitter e sta recuperando i tweet.
6. Lo snap "Filtro" viene utilizzato per filtrare i tweet. Cercare "Filtro" utilizzando la scheda Snap sul riquadro di sinistra. Trascinare lo snap "Filtro" sull'area di disegno.
 a. Fare clic su "Filtro" Snap per aprire il modulo Impostazioni.
a. Fare clic su "Filtro" Snap per aprire il modulo Impostazioni.
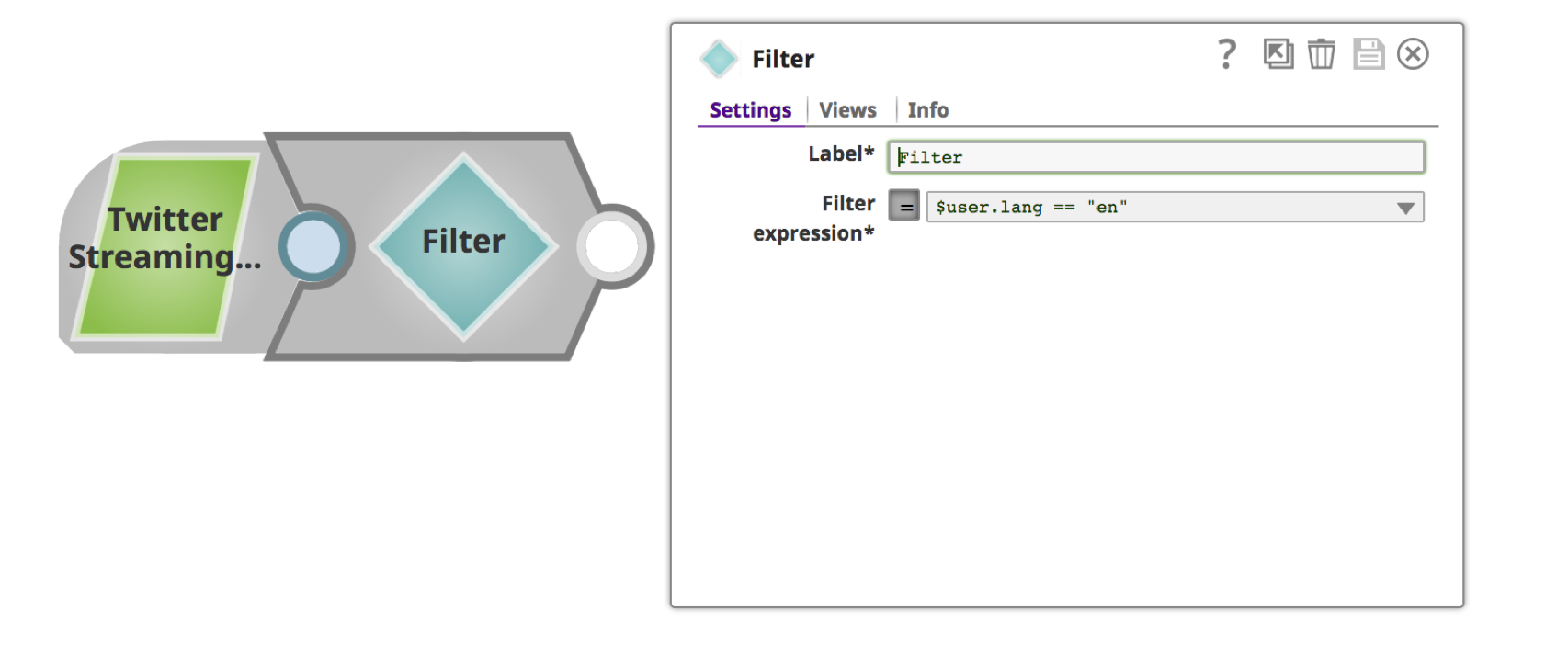 b. Fornire un nome significativo, ad esempio "Filtro per lingua" per "Etichetta" e condizione di filtro per "Espressione filtro". È possibile utilizzare il menu a tendina per scegliere l'attributo del filtro.
b. Fornire un nome significativo, ad esempio "Filtro per lingua" per "Etichetta" e condizione di filtro per "Espressione filtro". È possibile utilizzare il menu a tendina per scegliere l'attributo del filtro.
7. Fare clic sull'icona del disco ![]() per salvarlo, il che fa scattare di nuovo la convalida. A questo punto è stato completato con successo uno snap "Filtro".
per salvarlo, il che fa scattare di nuovo la convalida. A questo punto è stato completato con successo uno snap "Filtro".
8. Cercare lo snap "Confluent Kafka Producer" utilizzando la scheda Snap sulla cornice sinistra. Trascinare e rilasciare lo snap sulla tela.
 Nota: Confluente è una distribuzione di Apache Kafka pensata per le imprese.
Nota: Confluente è una distribuzione di Apache Kafka pensata per le imprese.
a. Il "Confluent Kafka Producer" richiede un account per connettersi al cluster Kafka. Scegliere i valori appropriati in base alla posizione e al tipo di account.
 b. Fornire un testo significativo per l'"etichetta" dei server di bootstrap. In caso di più server di bootstrap, utilizzare una virgola per separarli, insieme alla porta.
b. Fornire un testo significativo per l'"etichetta" dei server di bootstrap. In caso di più server di bootstrap, utilizzare una virgola per separarli, insieme alla porta.
 c. L'"URL del registro Schema" è opzionale, ma è necessario nel caso in cui Kafka debba analizzare il messaggio in base allo Schema.
c. L'"URL del registro Schema" è opzionale, ma è necessario nel caso in cui Kafka debba analizzare il messaggio in base allo Schema.
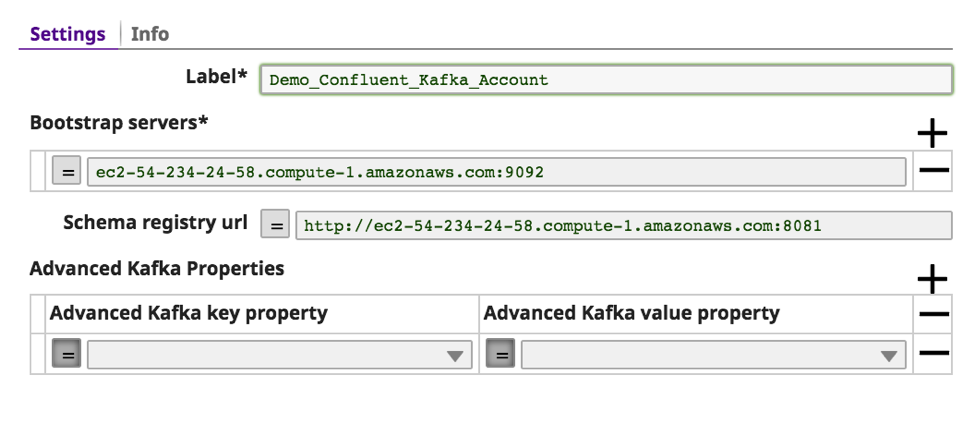 d. Le altre proprietà opzionali di Kafka possono essere passate a Kafka usando le "Proprietà avanzate di Kafka". Fare clic su "Convalida".
d. Le altre proprietà opzionali di Kafka possono essere passate a Kafka usando le "Proprietà avanzate di Kafka". Fare clic su "Convalida".
e. Se la convalida è andata a buon fine, si dovrebbe vedere un messaggio in alto come "Convalida dell'account riuscita". Fare clic su "Applica".
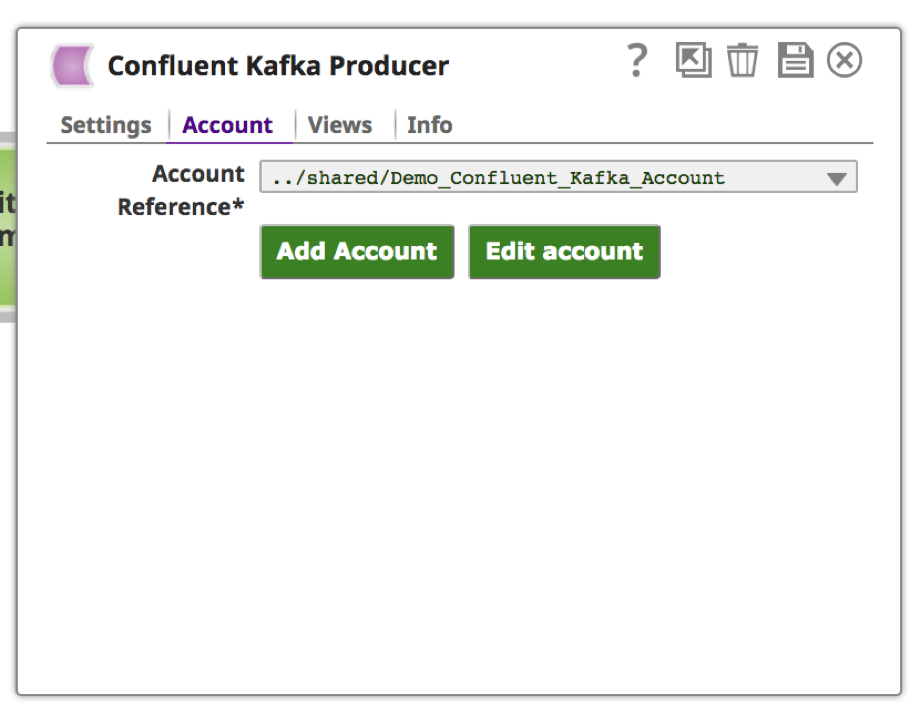 9. Una volta impostato e scelto l'account, fare clic sulla scheda "Impostazioni" per fornire l'argomento e il messaggio Kafka.
9. Una volta impostato e scelto l'account, fare clic sulla scheda "Impostazioni" per fornire l'argomento e il messaggio Kafka.
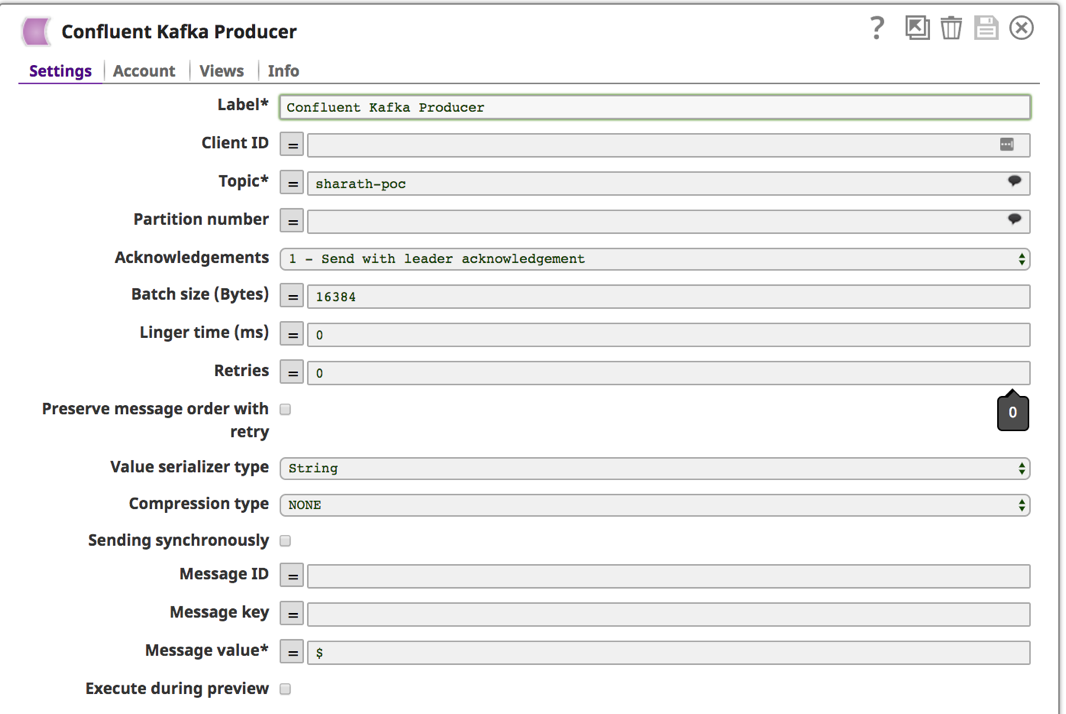
a. È possibile scegliere dall'elenco degli argomenti disponibili facendo clic sull'icona della bolla. ![]() accanto al campo "Argomento". Lasciare gli altri campi come predefiniti. Un altro campo obbligatorio è "Valore del messaggio". Immettere "$" per inviare l'intero Tweet e le informazioni sui metadati. Salvare facendo clic sull'icona del disco
accanto al campo "Argomento". Lasciare gli altri campi come predefiniti. Un altro campo obbligatorio è "Valore del messaggio". Immettere "$" per inviare l'intero Tweet e le informazioni sui metadati. Salvare facendo clic sull'icona del disco ![]() .
.
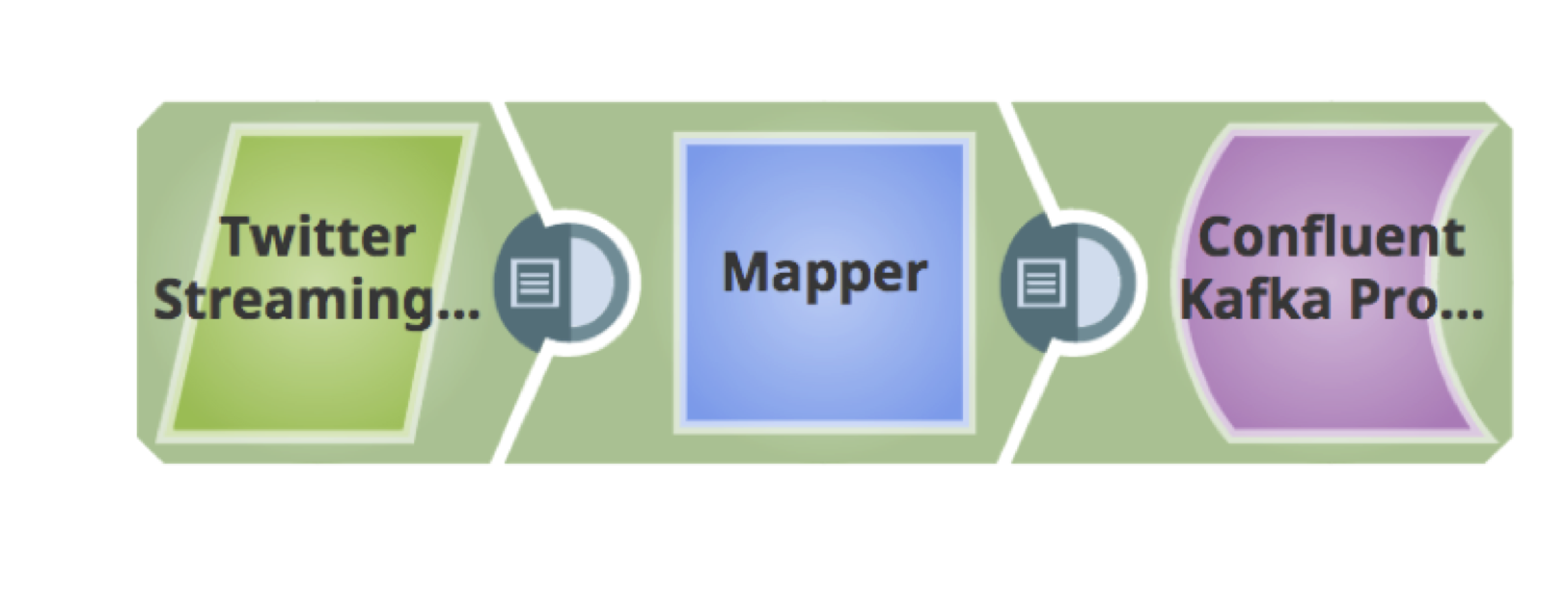 10. Questa è una pipeline completamente validata per recuperare i tweet e caricarli in Kafka.
10. Questa è una pipeline completamente validata per recuperare i tweet e caricarli in Kafka.
11. A questo punto, la pipeline è pronta a ricevere i tweet e a inviarli agli argomenti di Kafka. Eseguire la pipeline facendo clic sul pulsante play nell'angolo superiore destro. ![]() . Visualizzare l'avanzamento facendo clic sul pulsante di visualizzazione
. Visualizzare l'avanzamento facendo clic sul pulsante di visualizzazione ![]() .
.
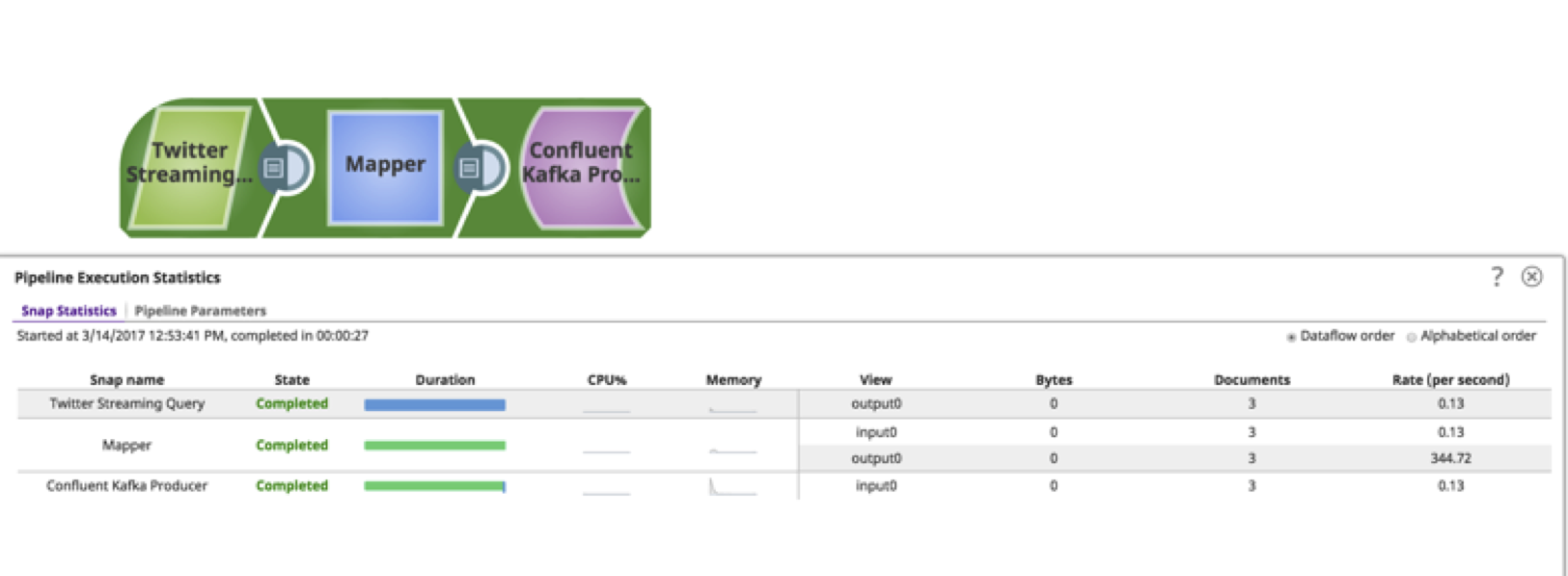 Come si può vedere, la pipeline può essere costruita in meno di 15 minuti senza richiedere alcuna conoscenza tecnica approfondita. Questo tutorial e video fornisce un esempio di base di ciò che si può ottenere utilizzando questi snap. Esistono diversi altri snap che possono agire sui dati, come filtrare, copiare, aggregare, attivare eventi, inviare email e altri. Snaplogic è orgogliosa di portare la tecnologia complessa al cittadino integratore. Spero che lo abbiate trovato utile!
Come si può vedere, la pipeline può essere costruita in meno di 15 minuti senza richiedere alcuna conoscenza tecnica approfondita. Questo tutorial e video fornisce un esempio di base di ciò che si può ottenere utilizzando questi snap. Esistono diversi altri snap che possono agire sui dati, come filtrare, copiare, aggregare, attivare eventi, inviare email e altri. Snaplogic è orgogliosa di portare la tecnologia complessa al cittadino integratore. Spero che lo abbiate trovato utile!
Sharath Punreddy è architetto di soluzioni aziendali presso SnapLogic. Seguitelo su Twitter @srpunreddy.





{kind=link}