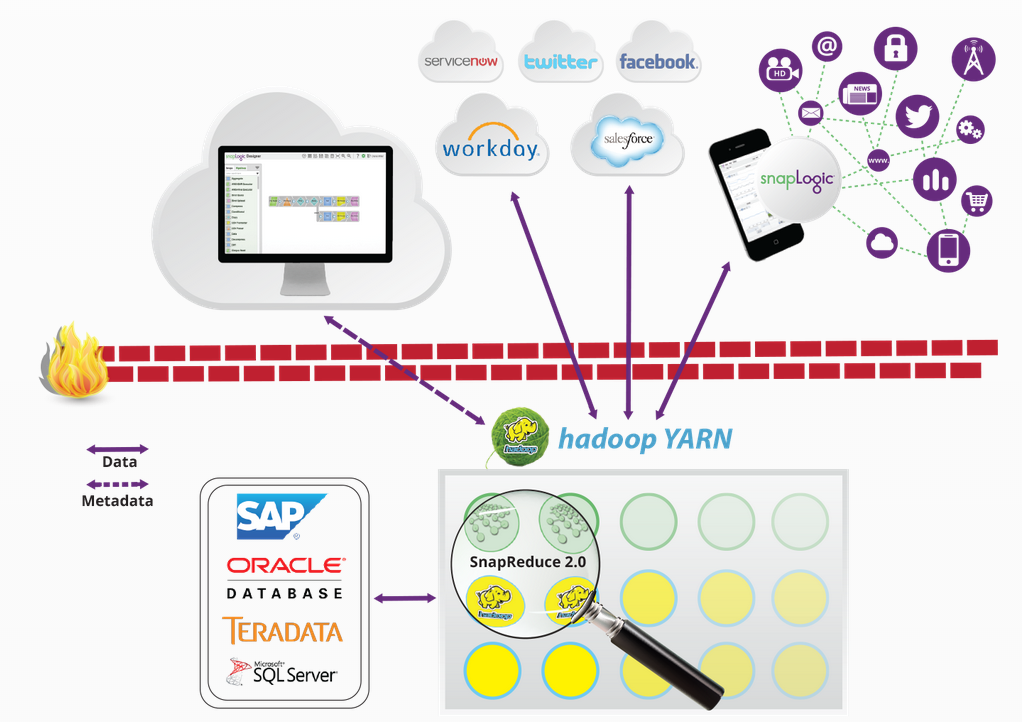
Questa settimana SnapLogic ha annunciato SnapReduce 2.0, che consente a SnapLogic Elastic Integration Platform as a Service(iPaaS) di funzionare in modo nativo su Hadoop come risorsa gestita da YARN che scala in modo elastico e facilita l'acquisizione, la preparazione e la fornitura di big data. Ho incontrato Greg Benson, professore di informatica presso l'Università di San Francisco e Chief Scientist di SnapLogic. Negli ultimi 20 anni Greg ha lavorato alla ricerca sui sistemi distribuiti, sulla programmazione parallela, sui kernel dei sistemi operativi e sui linguaggi di programmazione. Il suo team sta guidando l'innovazione di SnapLogic nell'integrazione dei big data. Ecco cosa ha da dire su SnapReduce 2.0, YARN e sull'opportunità per i clienti di beneficiare della piattaforma di integrazione software-defined di SnapLogic:
Che cos'è SnapReduce?
SnapReduce 1.0 sfruttava Hadoop trasformando le pipeline di SnapLogic in lavori Hadoop MapReduce. Queste pipeline trasformate potevano lavorare esclusivamente sui dati Hadoop esistenti. Pur essendo potente, questa tecnologia non apriva l'intera gamma di connettività di SnapLogic a Hadoop. Ora, con YARN, SnapLogic può essere eseguito all'interno di Hadoop e consentire l'esecuzione di qualsiasi pipeline SnapLogic all'interno di un cluster Hadoop.
SnapReduce 2.0 sfrutta il vostro investimento in Hadoop consentendovi di moltiplicare le risorse Hadoop per le attività di integrazione oltre che per le altre applicazioni Hadoop. Le attività di integrazione possono ora scalare in base alla capacità del cluster Hadoop, secondo le necessità. Inoltre, SnapReduce 2.0 semplifica l'acquisizione e la distribuzione dei dati Hadoop utilizzando un designer grafico e la connettività Snap a un'ampia gamma di applicazioni e data store.
Cosa rende SnapReduce 2.0 unico?
SnapReduce 2.0 è unico perché è sia conforme a YARN sia collegato all'iPaaS elastico di SnapLogic. In questo modo si ottengono tutti i vantaggi di utilizzo delle risorse e di scalabilità di Hadoop, senza però rinunciare alla manutenzione di un servizio cloud . Inoltre, fondamentale per SnapLogic è il supporto nativo per i documenti gerarchici. Questo supporto nativo può essere utilizzato per creare facilmente file di dati JSON in HDFS e record orientati alle righe, a seconda delle necessità.
Quali problemi risolve SnapReduce 2.0?
Vediamo alcuni clienti che vogliono iniziare a spostare il loro data warehouse e l'archiviazione a lungo termine in Hadoop per il suo vantaggio economico rispetto ai prodotti di archiviazione proprietari. Inoltre, i clienti stanno iniziando a ripensare l'analisi in termini di Hadoop e vogliono collegare il maggior numero di dati possibile al loro hub di dati aziendali. I clienti vedono in questo passaggio un'opportunità per liberarsi dalle vecchie manette dell'ETL e passare a una piattaforma moderna che abbraccia sia cloud sia i big data.
Attualmente gli approcci mainstream per portare i dati in Hadoop sono limitati a Flume per i dati di log, Scoop per i dati relazionali e alle applicazioni personalizzate per altri tipi di dati. Ora, tutto ciò a cui SnapLogic può connettersi diventa un'origine dati per Hadoop, ad esempio file di registro, dati relazionali, applicazioni on premise e applicazioni cloud . Allo stesso modo, queste fonti di dati diventano facilmente destinazioni di dati. Rendiamo elastici i big data fornendo un'acquisizione e una distribuzione flessibile dei dati, in modo che non siano più isolati da strumenti per sviluppatori difficili da configurare e da usare.
Quando sarà disponibile SnapReduce 2.0?
Come abbiamo dichiarato nel comunicato stampa, la disponibilità è prevista per le prossime settimane. Attualmente stiamo collaborando con i principali partner di distribuzione di Hadoop per le certificazioni e abbiamo avviato un programma di accesso anticipato per alcuni dei nostri clienti esistenti e potenziali con progetti big data attivi. Per saperne di più su SnapReduce 2.0 e per iscriversi al programma, visitate il sito web di SnapLogic.
Ottimo materiale. Grazie per l'aggiornamento Greg. Non vediamo l'ora di saperne di più su questa e altre iniziative di integrazione dei big data che arriveranno presto dal vostro team!
Prossimi passi:
- Per saperne di più su SnapReduce 2.0
- Scarica il kit di strumenti per l'integrazione dei dati elastici
- Scoprite come stiamo alimentando gli analytics basati su Amazon Redshift cloud
- Guarda un video su SnapTV
- Contattateci per discutere i vostri requisiti di integrazione di cloud e dei big data.