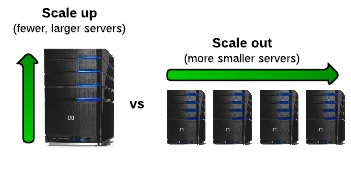
 Le tecnologie di integrazione dei dati e delle applicazioni tradizionali sono state progettate per scalare e non per scalare. Come abbiamo discusso nel nostro recente webinar con iRobot, l'elasticità è una caratteristica fondamentale del computing cloud e noi di SnapLogic riteniamo che sia un requisito fondamentale per una piattaforma di integrazione aziendale come servizio (iPaaS). Finora in questa serie di post su Cosa cercare in una moderna piattaforma di integrazioneAbbiamo parlato della necessità di un set completo di funzionalità basate su cloud (e un'architettura definita dal software) e una piattaforma unica per i casi d'uso di integrazione di applicazioni, dati e API. In questo post esamineremo i vantaggi del requisito iPaaS per una scala elastica. Il contrario di elastico è "rigido" e questa è una delle principali sfide che le tecnologie di integrazione legacy devono affrontare quando si tratta di gestire le attuali tecnologie sociali, mobili, analitiche, cloud e l'Internet delle cose (SMACT). Quando annunciato Nel 2013, con la piattaforma di integrazione elastica SnapLogic, abbiamo introdotto il concetto di elasticità a tre vie:
Le tecnologie di integrazione dei dati e delle applicazioni tradizionali sono state progettate per scalare e non per scalare. Come abbiamo discusso nel nostro recente webinar con iRobot, l'elasticità è una caratteristica fondamentale del computing cloud e noi di SnapLogic riteniamo che sia un requisito fondamentale per una piattaforma di integrazione aziendale come servizio (iPaaS). Finora in questa serie di post su Cosa cercare in una moderna piattaforma di integrazioneAbbiamo parlato della necessità di un set completo di funzionalità basate su cloud (e un'architettura definita dal software) e una piattaforma unica per i casi d'uso di integrazione di applicazioni, dati e API. In questo post esamineremo i vantaggi del requisito iPaaS per una scala elastica. Il contrario di elastico è "rigido" e questa è una delle principali sfide che le tecnologie di integrazione legacy devono affrontare quando si tratta di gestire le attuali tecnologie sociali, mobili, analitiche, cloud e l'Internet delle cose (SMACT). Quando annunciato Nel 2013, con la piattaforma di integrazione elastica SnapLogic, abbiamo introdotto il concetto di elasticità a tre vie:
- Scalare in sede per affrontare le applicazioni aziendali che si trovano dietro il firewall del cliente;
- Scalare in cloud per integrare i dati dalle applicazioni cloud/SaaS; e,
- La spedizione delle funzioni in modo elastico tra l'ambiente on-premise e il sito cloud, ottimizzando così la velocità di esecuzione dell'integrazione, portando l'elaborazione ai dati anziché spedire i dati all'elaborazione.
In un articolo di Wired, il cofondatore e CEO di SnapLogic, Gaurav Dhillon, ha descritto i vantaggi dell'integrazione elastica in questo modo:
"Le aziende avranno sempre dati sia on-premise che sul sito cloud. Il trucco consiste nell'integrare i dati su questi due piani in modo rapido, flessibile e scalabile, in modo da poter elaborare una varietà di tipi di dati, grandi, relazionali, semi-strutturati o non strutturati, e fornirli in una varietà di modi, tra cui batch, basati su eventi o streaming, spedendo in modo intelligente funzioni o dati di qualsiasi volume, indipendentemente da dove risiedono i dati, in modo controllato e distribuito in modo flessibile".
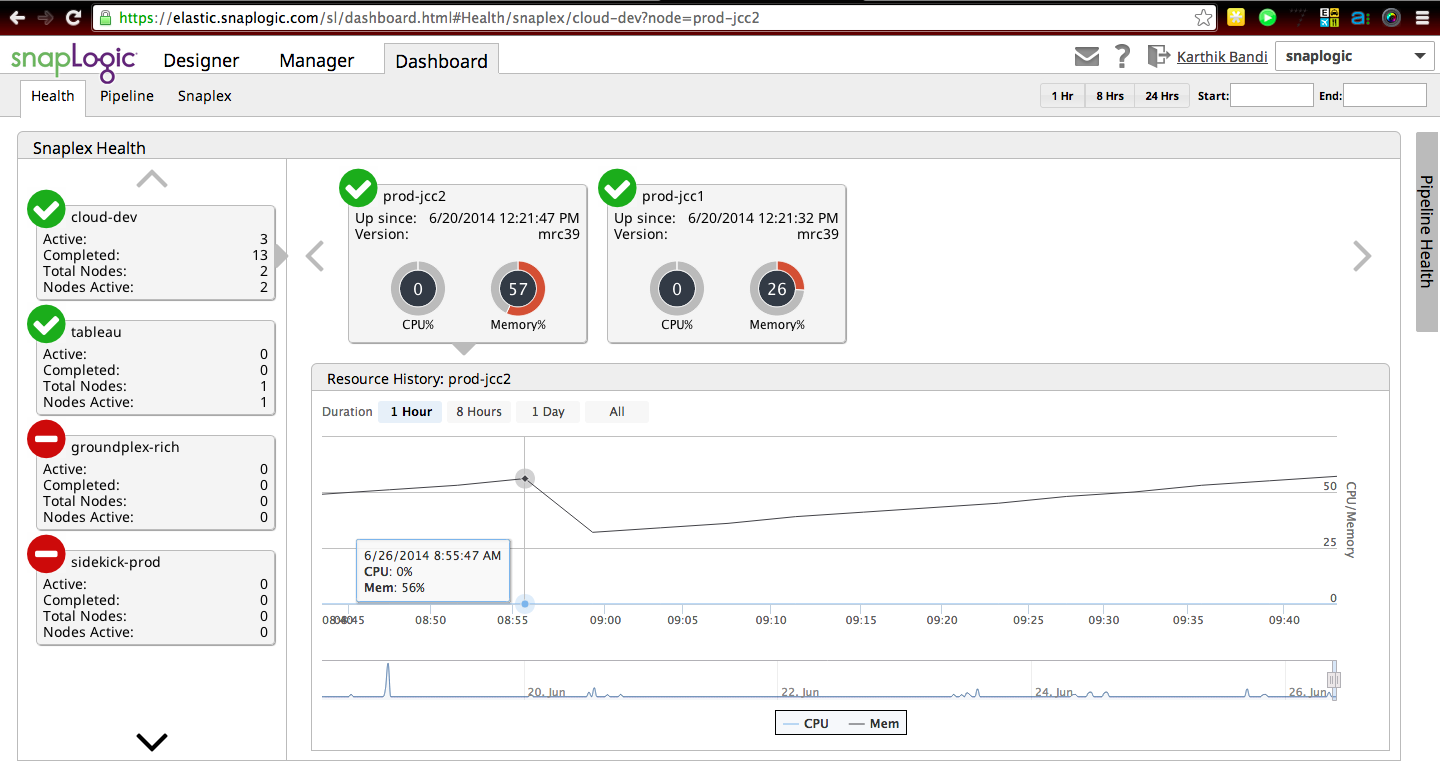
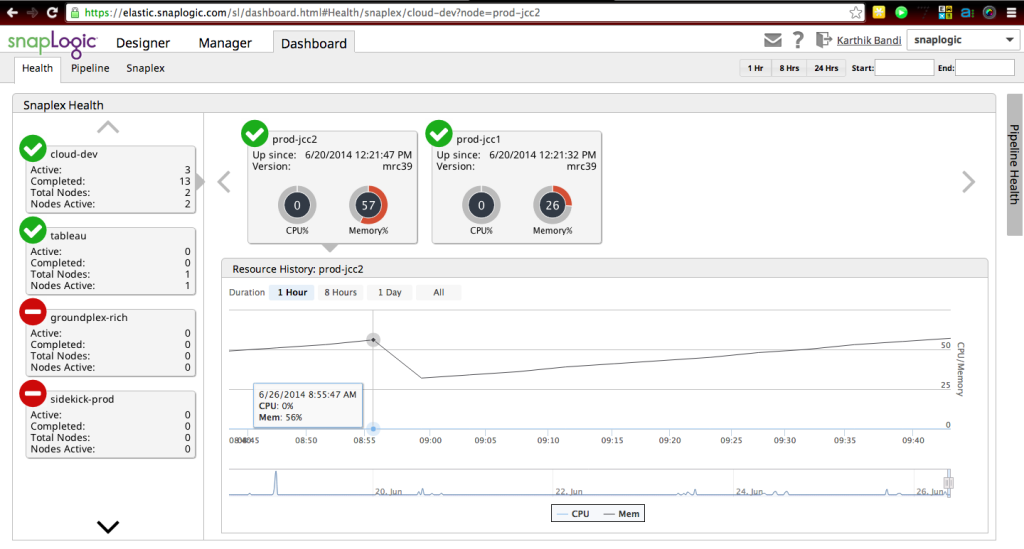
In un recente TechTalk su SnapReduce 2.0, Greg Benson, Chief Scientist di SnapLogic, ha discusso di come un numero sempre maggiore di attività di gestione dei dati verrà eseguito su Hadoop, compresa la migrazione delle integrazioni di dati e delle attività ETL esistenti in Hadoop per eseguirle su scala Hadoop. Ecco una schermata del dashboard di SnapLogic che monitora lo stato di salute del servizio di integrazionecloud , mostrando la rete di integrazione elastica, chiamata Snaplex, che si ridimensiona man mano che vengono richiesti più capacità/nodi. Come abbiamo discusso in questo post:
"Ogni Snaplex può espandersi e contrarsi elasticamente in base al traffico di dati che lo attraversa. L'unità di scalabilità all'interno di Snaplex è una JVM. L'integrazione SnapLogic Cloud è dotata di funzioni intelligenti per scalare automaticamente lo Snaplex per gestire carichi di traffico variabili. Ad esempio, ogni Snaplex viene inizializzato con un numero preconfigurato di JVM (ad esempio una). Quando l'utilizzo di una JVM raggiunge una certa soglia (ad esempio l'80%), viene automaticamente avviata una nuova JVM per gestire il carico di lavoro aggiuntivo. Una volta che il traffico di dati in eccesso è stato elaborato e la seconda JVM è inattiva, essa viene ridotta per tornare alle sue dimensioni originali".
 Nel prossimo post di questo Serie di requisiti iPaaSParleremo dei moderni standard web: REST e JSON.
Nel prossimo post di questo Serie di requisiti iPaaSParleremo dei moderni standard web: REST e JSON.