







Non c'è AI senza dati. La versione di maggio della piattaforma SnapLogic accelera la capacità di utilizzare i dati per trasformare l'organizzazione con applicazioni GenAI. Con questa release è possibile:
- Connessione ai modelli di fondazione di Anthropic Claude e a un altro database vettoriale: Ricerca vettoriale dell'Atlante MongoDB
- Governate tutte le integrazioni e i metadati da un'unica postazione con il nuovissimo Catalogo delle integrazioni.
- Caricare e trasformare i dati con facilità grazie alle nuove funzioni AutoSync e al supporto degli endpoint, all'appiattimento dei file Parquet, ecc.
- Sfruttare dati diversi in più luoghi, come il supporto per i dati geospaziali in SQL Server.
- Automatizzare i cicli di vita delle API e dell'infrastruttura della piattaforma con un maggior numero di API pubbliche.
E molto altro ancora. Scopriamo questi aggiornamenti!
LLM più supportati e supporto di VectorDB in GenAI Builder
L'ultima versione di GenAI Builder aggiunge il supporto per i modelli di fondazione di Anthropic Claude come parte dell'Amazon Bedrock LLM Snap Pack. È possibile sfruttare qualsiasi modello di Anthropic Claude e generare risposte ai messaggi. Questa funzionalità consente di creare applicazioni GenAI che migliorano la produttività dei dipendenti, assistono i clienti con una migliore esperienza di servizio, migliorano l'esperienza dei partner e altro ancora.
Guardate questo video su come potete creare flussi di lavoro per alimentare le vostre applicazioni GenAI con Anthropic Claude.
Stiamo anche aggiungendo il supporto per un nuovo database vettoriale, MongoDB Atlas Vector Search, per aiutarvi a costruire applicazioni GenAI. Se utilizzate il database MongoDB Atlas Vector Search, potete collegarlo alle vostre applicazioni GenAI. Con MongoDB Atlas Vector Search Snap, è possibile eseguire interrogazioni avanzate basate su vettori, come ricerche di somiglianza, interrogazioni approssimate di prossimità (ANN), interrogazioni di intervallo, ecc. Ora è possibile creare assistenti AI di generazione aumentata di recupero con i dati aziendali che risiedono su MongoDB Atlas Vector Search.
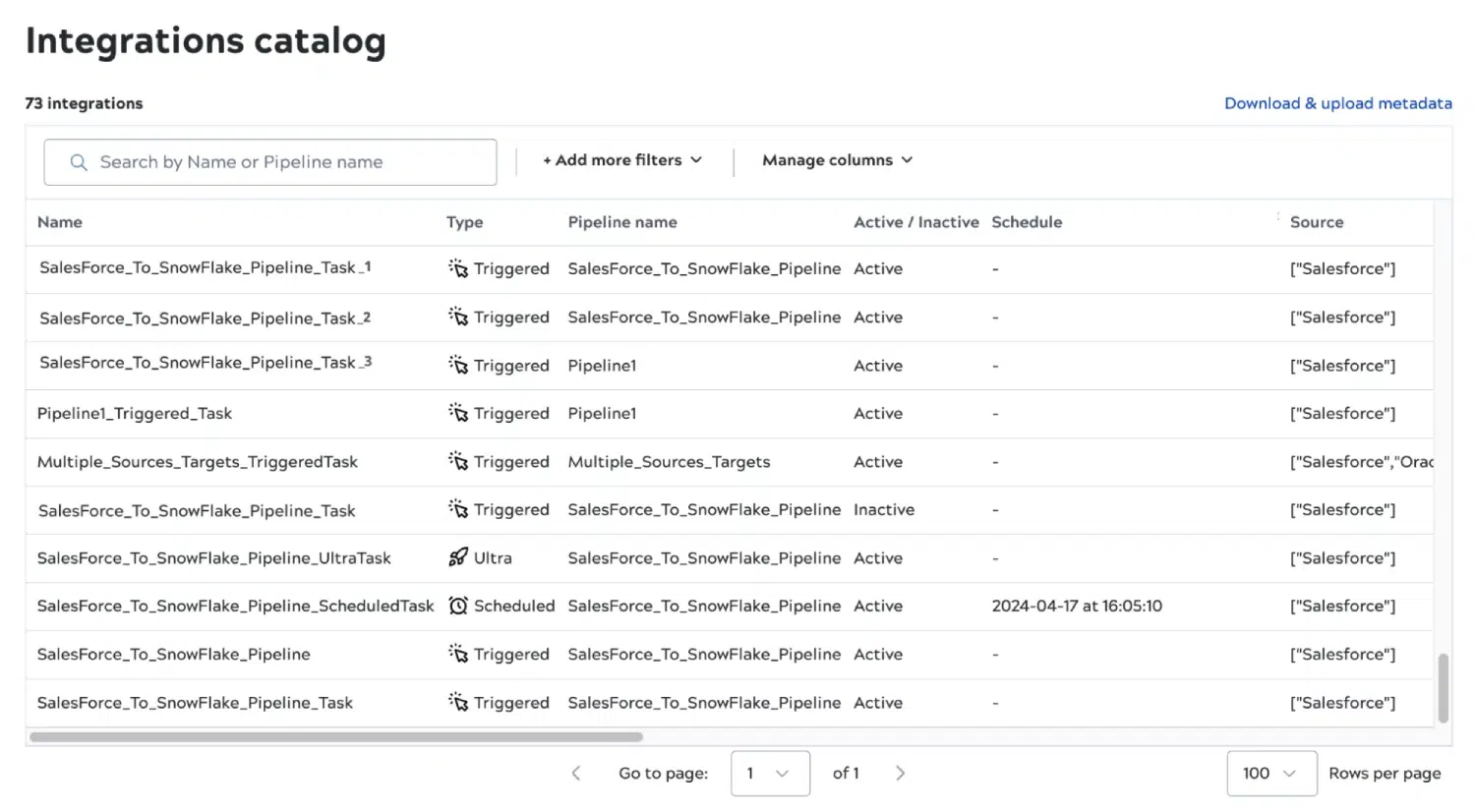
Tutto il nuovo catalogo delle integrazioni
Siamo estremamente entusiasti di introdurre un nuovissimo Catalogo delle integrazioni con questa release, per offrirvi una visione unificata di tutte le vostre integrazioni e dei relativi metadati. Il catalogo offre una directory di tutte le integrazioni, consentendo ai team di trovare, comprendere e gestire facilmente le integrazioni. Grazie al catalogo, è possibile comprendere il panorama delle integrazioni in base al dominio aziendale e alle applicazioni, identificare le pipeline in base agli endpoint a cui si connettono e ridurre i costi delle integrazioni per i flussi di lavoro nuovi ed esistenti. È inoltre possibile tenere facilmente traccia di ciò che fa ogni pipeline, in modo da poter sfruttare le integrazioni esistenti per nuovi flussi di lavoro, riducendo così i tempi di integrazione.
Il catalogo delle integrazioni espone metadati non disponibili altrove sulla piattaforma, come il proprietario, la pianificazione e il conteggio degli snap. Un'altra caratteristica importante è la possibilità di aggiungere metadati personalizzati. Con i metadati personalizzati, i team IT centrali possono mappare le integrazioni ai processi aziendali per ridurre i costi delle operazioni o migliorare il tempo medio di ripristino (MTTR). Inoltre, possono utilizzare i metadati personalizzati per creare report sulle applicazioni e sugli endpoint di dati connessi e comprendere i potenziali rischi del sistema.
Gli utenti possono caricare metadati personalizzati per le pipeline di integrazione e anche esportare metadati per integrarli con un catalogo di dati di terze parti.
Scoprite il catalogo delle integrazioni in questo video dimostrativo.
Operazioni e trasformazioni di dati migliorate in AutoSync
Negli ultimi mesi SnapLogic AutoSync ha ricevuto un notevole incremento di funzionalità. Oltre al connettore HTTPClient Source, che consente di acquisire dati praticamente da qualsiasi endpoint con API RESTFul, questa release aggiunge nuovi endpoint di destinazione come Databricks, Amazon S3, Azure Data Lake Storage (ADLS) Gen2.
AutoSync offre ora nuove funzioni che consentono di interrompere una pipeline nel bel mezzo dell'esecuzione. Tuttavia, poiché l'interruzione di una pipeline può compromettere l'integrità dei dati, si consiglia di implementarla solo come ultima risorsa e di procedere con un carico completo quando si è pronti.
La piattaforma consente ora anche di aggiornare gli endpoint di una pipeline AutoSync senza soluzione di continuità. Ciò consente di risparmiare giorni di lavoro nel corso della vita di una pipeline AutoSync, poiché non è più necessario costruire la stessa pipeline da zero.
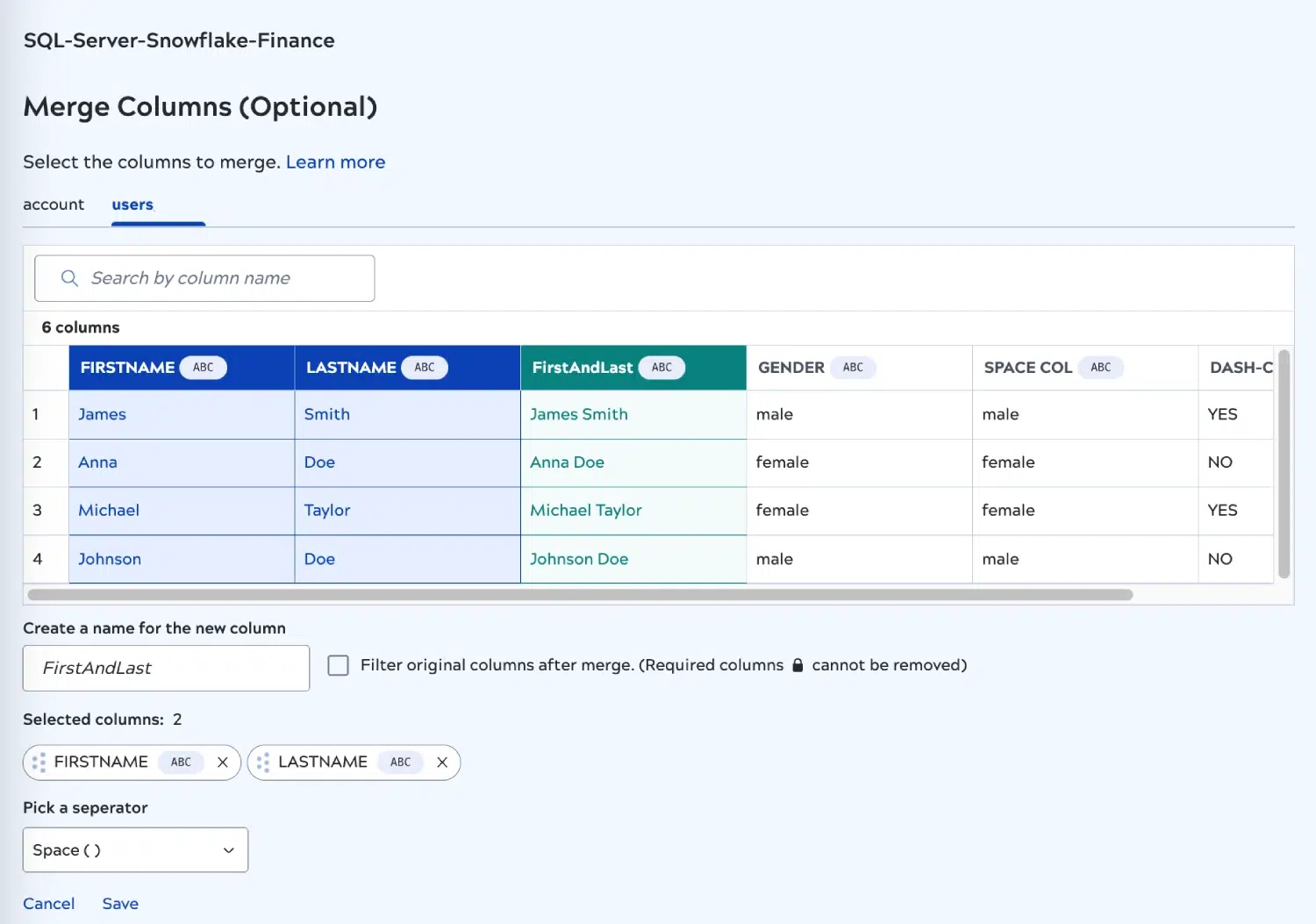
La versione di maggio introduce anche nuove funzioni di trasformazione. È ora possibile concatenare più colonne di tipo "String" utilizzando la nuova funzione Merge Column. Ciò consente di semplificare le strutture di dati nel target, ottenendo un'archiviazione efficiente e una risposta più rapida alle query.
Migliore gestione dei dati di parquet in ELT
I clienti che desiderano caricare file di parquet in un data warehouse cloud , come Snowflake, tramite carichi di lavoro ELT, possono ora gestire facilmente i set di dati annidati. La funzione ELT Load consente ora di appiattire i dati in entrata. Questa funzionalità consente di eseguire una preelaborazione più efficiente, che riduce i tempi e i costi di elaborazione all'interno del data warehouse cloud .
Aggiornamenti Snap
La versione di maggio apporta numerosi miglioramenti ai nostri Snap Pack. Ecco un riepilogo degli aggiornamenti principali:
Snowflake Snap Pack: La release di maggio aggiunge il supporto per le popolari tabelle Apache Iceberg agli snap Bulk Load e Insert dello Snowflake Snap Pack. Le tabelle Iceberg suddividono i dati su più nodi per accelerare l'elaborazione dei dati e, di conseguenza, sono state molto apprezzate dalla comunità degli utenti. La funzione è in anteprima in Snowflake, ma sappiamo che molti di voi l'hanno già adottata. Questo miglioramento consente ora di sfruttare le pipeline di SnapLogic per creare e manipolare le tabelle Iceberg.
SQL Server Snap Pack: I dati geospaziali sono fondamentali nei settori della vendita al dettaglio, della catena di approvvigionamento e delle assicurazioni. Per questo motivo, su richiesta dei clienti, abbiamo aggiunto il supporto per i dati geospaziali (sia geografici che geometrici) a Microsoft SQL Server Snap Pack. Questo supporto consente di inserire, leggere e selezionare i dati geospaziali presenti in Microsoft SQL Server.
Pacchetto Snap MongoDB: Stiamo aggiungendo MongoDB Execute Snap al MongoDB Snap Pack in modo da poter eseguire qualsiasi comando Data Definition Language (DDL) e Data Manipulation Language (DML) sul database MongoDB.
NetSuite Snap Pack: Gli aggiornamenti di maggio dello Snap Pack di NetSuite aggiungono ora nuovi snap per spostare i record in blocco. Lo snap Aggiungi elenco consente di aggiungere nuovi record in blocco a NetSuite. L'analogo Async Add List aggiunge questi record in modo asincrono, ossia restituendo all'utente un ID di lavoro. Il processo viene completato in background ed è possibile controllare lo stato del lavoro per verificare se i record sono stati aggiunti.
Automatizzare il ciclo di vita delle API e l'infrastruttura SnapLogic
Con la release di maggio, stiamo aggiungendo diverse API pubbliche, in modo che possiate automatizzare il ciclo di vita delle API con strumenti CI/CD, proprio come gestite il ciclo di vita del vostro codice o delle vostre pipeline. Con le nuove API pubbliche, è possibile Creare un ramo, Creare una versione API, Eseguire il checkout del ramo, Estrarre le ultime modifiche, Tag Git, Controllare lo stato di Repo, Scartare le modifiche e Eliminare un ramo. Se state sviluppando API per i vostri clienti interni o esterni, con queste API pubbliche potete aspettarvi di risparmiare ore di noioso lavoro manuale ogni settimana.
Le nuove API pubbliche consentono anche di effettuare una cancellazione morbida delle API e delle versioni delle API. Le API finiranno nel cestino invece di essere eliminate per sempre. Ciò consentirà ai gestori delle API di risparmiare tempo e di creare un'esperienza utente migliore, grazie alla possibilità di ripristinare le cancellazioni, se necessario.
Nuove API pubbliche permettono di creare, aggiornare e cancellare un Groundplex per creare al volo un'infrastruttura per test transitori o iniziative di staging prima di promuovere le modifiche alla produzione. Un'altra API pubblica consente di scartare le modifiche locali in modo che non vengano tracciate dal repository GIT.
Sicurezza migliorata per gli endpoint proxy
È ora possibile aggiungere un criterio JWT agli endpoint proxy gestiti in API Manager. L'utente può configurare un criterio JWT (JSON Web Token) in uscita per aggiungere un ulteriore livello di autenticazione e sicurezza alle proprie API.
Un altro miglioramento consente di aggiungere più criteri di collegamento degli account, come Outbound Basic Auth e Outbound OAuth, a un endpoint proxy ed entrambi i criteri saranno applicati in ordine. In precedenza, il primo criterio veniva ignorato. Questa modifica consente all'utente di avere più criteri di collegamento dell'account in un endpoint proxy/proxy. Questa modifica riguarda tutti i criteri di autenticazione in uscita.
Per saperne di più sulla release di maggio, consultate le note di rilascio o contattate il team di Customer Success.





