Di recente, ho lavorato con un cliente per effettuare il reverse engineering di uno script Pig che esegue un lavoro MapReduce in Hadoop e poi lo ha orchestrato come pipeline SnapReduce con la Elastic Integration Platform di SnapLogic. L'interfaccia utente Designer di SnapLogic, basata su HTML5 cloud, e la raccolta di componenti precostituiti chiamati Snaps hanno permesso di creare una rappresentazione visiva e funzionale del flusso di lavoro di analisi dei dati senza conoscere le complessità di Pig e MapReduce. Ecco una breve descrizione:
Che cos'è il linguaggio di scripting Pig?
Lo script Pig è un linguaggio di scripting di alto livello utilizzato con Apache Hadoop, per la creazione di applicazioni complesse per affrontare problemi aziendali. Pig viene utilizzato per lavori interattivi e batch con MapReduce come modalità di esecuzione predefinita.
Informazioni su SnapReduce e Hadooplex
SnapReduce e il nostro Hadooplex consentono all'iPaaS di SnapLogic di funzionare in modo nativo su Hadoop come un'applicazione YARN che scala elasticamente per alimentare l'analisi dei big data. SnapLogic consente agli utenti di Hadoop di sfruttare un'interfaccia utente drag-and-drop basata su HTML5, un'ampia connettività (chiamata Snaps) e un'architettura moderna. Per saperne di più , cliccate qui.
Caso d'uso complessivo (analisi dell'uso del prodotto)
I dati grezzi sull'utilizzo dei prodotti provenienti dalle app dei consumatori vengono caricati nelle tabelle Hadoop HCatalog e memorizzati in formato RCFile. Il programma legge i campi dei dati: nome del prodotto, utente e cronologia di utilizzo con data e ora, pulisce i dati ed elimina i record duplicati raggruppandoli per timestamp. Trova i record unici per ogni utente e scrive i risultati nelle partizioni HDFS in base a data e ora. Gli analisti di prodotto creano quindi una tabella esterna in Hive sopra i dati già partizionati per eseguire query e creare rapporti sull'uso dei prodotti e sulle tendenze. Scriveranno questi report su un file o li esporteranno in uno strumento di analisi visiva come Tableau.
Ecco la parte dello script Pig per il caso d'uso sopra descritto (pulizia dei dati):
REGISTER / apps / cloudera / parcels / CDH / lib / hive / lib / hive - exec.jar SET default_parallel 24; DEFINE HCatLoader org.apache.hcatalog.pig.HCatLoader(); raw = load
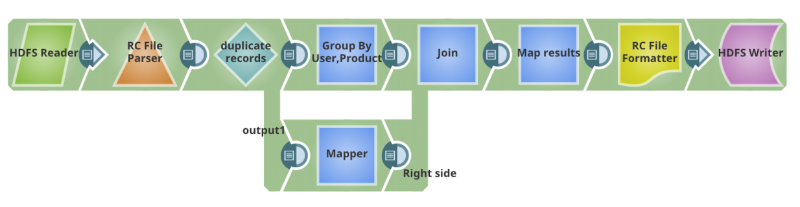
'sourcedata.sc_survey_results_history' USING HCatLoader(); in = foreach raw generate user_guid, survey_results, date_time, product as product; grp_in = GROUP in BY(user_guid, product); grp_data = foreach grp_in { order_date_time = ORDER in BY date_time DESC; max_grp_data = LIMIT order_date_time 1; GENERATE FLATTEN(max_grp_data); }; grp_out_data = foreach grp_data generate max_grp_data::user_guid as user_guid, max_grp_data::product as product, '$create_date' as create_date, CONCAT('-"product"="', CONCAT(max_grp_data::product, CONCAT('",', max_grp_data::survey_results))) as survey_results; results = STORE grp_out_data INTO 'hdfs://nameservice1/warehouse/marketing/sc_surSnapReduce Pipeline equivalente per lo script Pig
Questa pipeline SnapReduce viene tradotta in un lavoro MapReduce in Hadoop. Può essere programmata o attivata per automatizzare l'integrazione. Può anche essere trasformata in un modello di integrazione riutilizzabile. Come si vedrà, è piuttosto facile e intuitivo creare una pipeline usando la GUI HTML5 di SnapLogic e gli Snap per sostituire uno script Pig.
Il caso d'uso completo dell'analisi dei dati è stato creato in SnapLogic. Qui ho trattato solo la parte dello script Pig e ho intenzione di scrivere sul resto del caso d'uso in un secondo momento. Spero che questo sia d'aiuto! Ecco una dimostrazione della nostra soluzione di integrazione dei big data in azione. Contattateci per saperne di più.