






Punti di forza
- L'intelligenza artificiale è ovunque, ma con un alto rischio di fallimento
- Il facile accesso ai dati è la chiave del successo dell'IA
- L'integrazione dei dati deve essere allineata agli obiettivi aziendali
Come si svolge la scena
Il team di SnapLogic era presente in forze al Gartner Data & Analytics Summit di Londra. Si tratta di uno dei migliori eventi dell'anno per le conversazioni di alto valore, dove i partecipanti tendono a essere persone con obiettivi e problemi specifici, oltre che con la volontà e le risorse per affrontarli.
L'esigenza di soluzioni concrete è emersa fin dal keynote di apertura, quando Adam Ronthal e Alys Woodward hanno condiviso la loro scoperta che la maturità di dati e analisi ha un impatto positivo del 30% sulle prestazioni finanziarie. La governance e la gestione, tuttavia, tendono ancora a essere sottovalutate rispetto alle metriche più tecniche.
Le aziende di successo, tuttavia, stanno rivedendo il loro approccio alla narrazione dei dati e alle metriche D&A, per essere più orientate al business. Questo maggiore impegno con il business sarà un argomento ricorrente nei tre giorni della conferenza, e naturalmente è qualcosa che noi di SnapLogic sosteniamo da tempo, con il nostro approccio all'integrazione low-code/no-code.
Un altro argomento che (senza sorpresa) è stato presente ovunque durante la conferenza è stato l'IA e, ancora una volta, la raccomandazione è stata quella di valutare i progetti sia per la fattibilità che per il valore commerciale. La sperimentazione tecnica sulla fattibilità dell'IA è ben avviata nel nostro settore.
Gartner riporta che il 75% degli amministratori delegati ha già provato la GenAI secondo il "2023 CEO Survey Research Collection and Midyear Update AI Findings" - ma il 53% ritiene che non sarebbe in grado di gestire i rischi dell'IA. Esempi di fallimento di alto profilo sono Tay di Microsoft e il chatbot di Air Canada per i consigli di viaggio.

La conclusione è che la mancanza di dati pronti per l'AI è la sfida principale per il successo delle implementazioni GenAI. È proprio questo il problema che SnapLogic affronta, con una piattaforma di integrazione dei dati potente e onnivora per garantire la disponibilità dei dati e il toolkit GenAI Builder per renderli facilmente accessibili agli utenti finali.
Tessuto dati
Questa base tecnologica rientra nell'ambito del "data fabric", di cui ha parlato Michele Launi in un'interessante presentazione. Michele Launi ha chiarito che il data fabric non è un singolo strumento o prodotto che può essere acquistato e distribuito in un'unica fase, ma l'integrazione dei dati è un componente chiave, ed è qui che SnapLogic può aiutare. Il nostro modello di sviluppo low-code/no-code affronta anche una delle sfide principali all'adozione del data fabric, ovvero la mancanza di talenti specializzati.
Rendere disponibili i dati nell'ambito di un approccio data fabric significa garantire che la piattaforma sia in grado di supportare una varietà di stili di dati, dall'ETL tradizionale all'ETL inverso e all'ELT, nonché lo streaming, attraverso tipi di dati strutturati e non strutturati. Tutti questi aspetti, e altri ancora, sono emersi nelle conversazioni con i partecipanti allo stand di SnapLogic e nel corso della fiera.
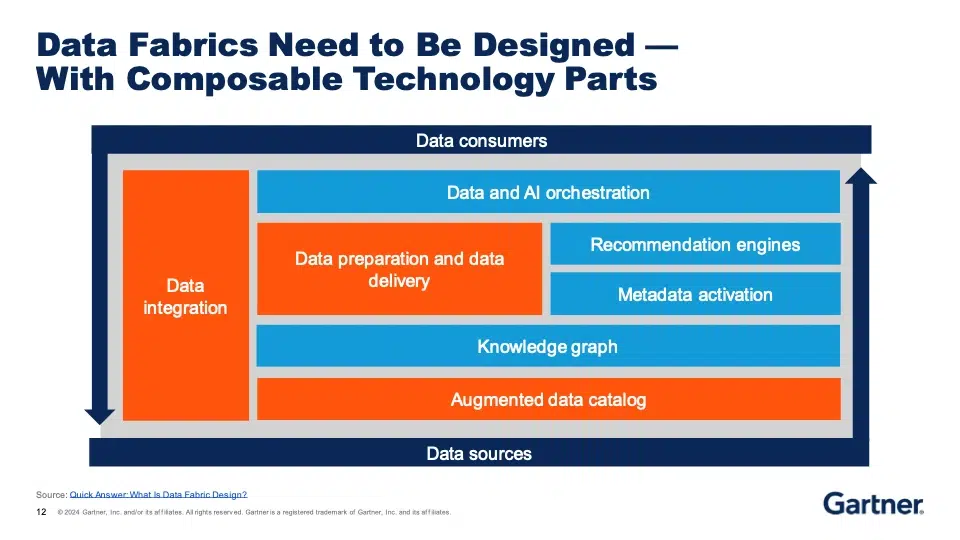
Michele ha anche detto che molti leader IT in particolare si aspettano che l'automazione riduca l'impegno nella condivisione dei dati. I risparmi sono reali e confermati dall'esperienza dei clienti SnapLogic in tutto il mondo, ma siamo anche d'accordo con Michele sul fatto che il vero valore si ottiene quando i dati vengono inseriti nel contesto aziendale.
Questo approccio self-service richiede una certa attenzione all'operatività e alla governance, un aspetto che il mio team di Enterprise Architect di SnapLogic è impegnato ad aiutare i nostri clienti a implementare attraverso il nostro Sigma Framework for Operational Excellence.
Il tema della maturità organizzativa è stato ripreso nel corso dello show durante una conversazione tra Mark Beyer e Robert Thanaraj sulle sovrapposizioni, a volte confuse, tra i concetti correlati di "data fabric" e "data mesh". In particolare, hanno condiviso la loro scoperta che le organizzazioni dedicano fino al 94% del loro tempo alla preparazione dei dati, e quindi solo tra il 6% e il 17% del loro tempo a utilizzare effettivamente i dati faticosamente raccolti per i loro scopi aziendali.
Per ridurre al minimo questo attrito, si consiglia di adottare un approccio più iterativo alla pianificazione, che consenta una maggiore flessibilità di fronte agli inevitabili cambiamenti. Questa flessibilità significa che la proprietà e la governance devono spettare all'azienda, poiché l'IT è troppo a valle; gli specialisti tecnici forniscono la piattaforma abilitante, ma i proprietari dell'azienda sono responsabili del risultato effettivo.
Secondo le stime di Gartner, poche organizzazioni hanno la maturità necessaria per effettuare questi cambiamenti culturali, ma il modello di SnapLogic consente la rapida iterazione, che è la chiave del successo, e la mette direttamente nelle mani degli esperti del settore, riducendo la necessità di specialisti IT e portando i vantaggi di questo approccio alle organizzazioni che si trovano più in basso nella curva di maturità di Gartner.
IA - ma come? E perché?
Sono riuscito a non parlare troppo di IA, ma come già detto, l'argomento è stato onnipresente durante la conferenza e descritto esplicitamente come l'obiettivo di gran parte delle attività di raccolta e integrazione dei dati. Tuttavia, il problema principale è che meno della metà dei progetti di IA entra in produzione e il rapporto è ancora peggiore per l'IA generativa, dove, secondo Gartner, meno del 10% arriva fino in fondo.
Per questo Sumit Agarwal ha affermato senza mezzi termini che l'IA generativa scenderà dall'attuale picco di aspettative gonfiate verso il baratro della disillusione.
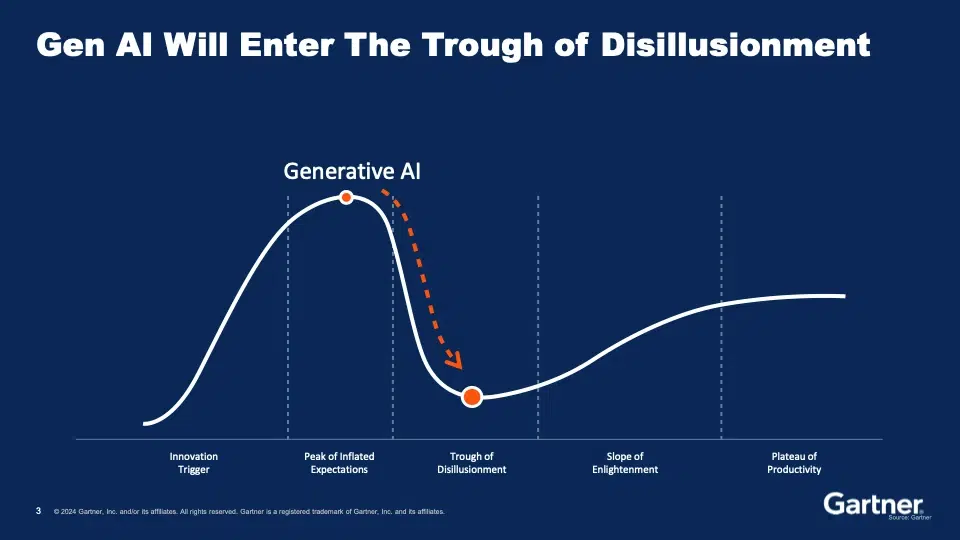
Sono d'accordo con Sumit: l'unico modo per uscire dalla crisi è dimostrare il valore dei progetti di IA e farlo su scala. Ecco perché SnapLogic offre il toolkit GenAI Builder. Riducendo al minimo la distanza tra i dati e le esigenze aziendali, GenAI Builder di SnapLogic consente agli utenti di prototipare e distribuire rapidamente servizi che sfruttano la potenza dell'IA, utilizzando i dati preziosi dell'organizzazione, e di farlo in modo sicuro e su scala.
Il valore di questo approccio è stato rafforzato da Gareth Herschel nel keynote di chiusura della seconda giornata: "L'AI si costruisce sulle fondamenta dell'architettura dei dati già esistente". La solidità delle fondamenta è particolarmente importante perché l'AI è un momento di "scommessa sul business", in cui il successo o il fallimento avranno enormi implicazioni per il futuro.
SnapLogic e Syngenta
Tanti temi generali, ma le proiezioni e i quadranti degli analisti hanno un peso limitato. La vera prova è nelle storie reali e concrete dei clienti. Per questo motivo sono stato molto felice di avere l'opportunità di intervistare Maks Shah, responsabile delle piattaforme di dati R&S di Syngenta, sul palco di un auditorium di mille persone.
Gli obiettivi aziendali non sono molto più concreti di quelli di Syngenta: nutrire il mondo in modo sicuro e prendersi cura del nostro pianeta. Tuttavia, la scienza digitale ha rappresentato una sfida: tempi lunghi per ottenere informazioni, un modello operativo insostenibile e problemi di qualità dei dati. I vincoli esterni che gravano su Syngenta Ricerca e Sviluppo sono significativi. Se qualcosa va storto in una sperimentazione sul campo o i risultati sono inconcludenti, bisogna aspettare un anno prima che la stagione di crescita successiva e i parassiti per quella coltura si ripresentino per poter ripetere l'esperimento.
Grazie a SnapLogic, i data scientist di Syngenta iniziano ad avere un accesso più rapido alle oltre 300 fonti di dati interne e alle oltre 100 esterne. Stanno ingerendo sia dati strutturati che semi-strutturati, in modalità batch e streaming, a seconda dei requisiti precisi di ciascuna fonte. Questa perfetta integrazione sta già dando i suoi frutti, con progetti quali:
- Integrazione tra applicazioni legacy e moderne per semplificare il panorama dell'integrazione dei dati
- Disaccoppiamento dell'architettura event-driven esistente e passaggio a un'architettura a microservizi più flessibile e a prova di futuro.
- Gestione API per consentire l'integrazione self-service
Non vediamo l'ora di continuare a lavorare con Syngenta, con gli altri clienti del settore life sciences e di molti altri settori, e con tutti i nuovi amici che abbiamo conosciuto al Gartner D&A. Se avete visitato il nostro stand in fiera, vi ringraziamo e vi contatteremo presto. E se vi siete persi l'evento, ma siete interessati a saperne di più su ciò che avete appena letto, saremo lieti di parlare di come SnapLogic può aiutarvi a smantellare i silos di dati e a portare la connettività nell'azienda.






