In questo ultimo post della serie tratta dal whitepaper di Mark Madsen: Will the Data Lake Drown the Data Warehouse?, riassumerò il ruolo di SnapLogic nel data lake aziendale.
SnapLogic è l'unica piattaforma di integrazione unificata di dati e applicazioni come servizio(iPaaS). La piattaforma di integrazione elastica SnapLogic dispone di oltre 350 connettori intelligenti precostituiti, chiamati Snaps, per collegare tutto, da AWS Redshift a Zuora, e di un'architettura di streaming che supporta i requisiti di integrazione aziendale in tempo reale, basati sugli eventi e a bassa latenza, oltre all'elevato volume, alla varietà e alla velocità dell'integrazione dei big data nella stessa interfaccia self-service e di facile utilizzo.
L'architettura distribuita e orientata al web di SnapLogic si adatta in modo naturale al consumo e allo spostamento di grandi insiemi di dati che risiedono in sede, sul sito cloud, o in entrambi, e alla loro consegna a e dal data lake. SnapLogic Elastic Integration Platform fornisce molti dei servizi fondamentali di un data lake, tra cui la gestione dei flussi di lavoro, il flusso di dati, il movimento dei dati e i metadati.
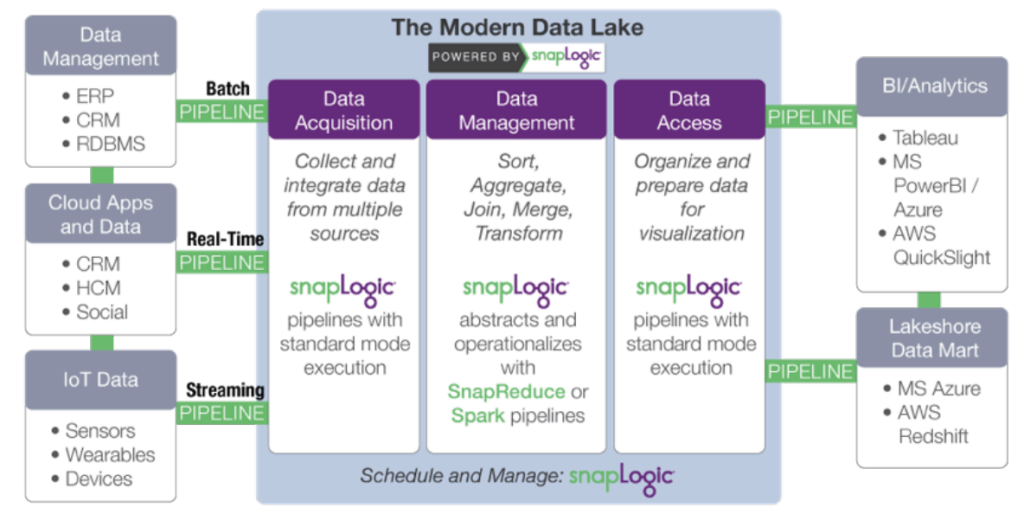
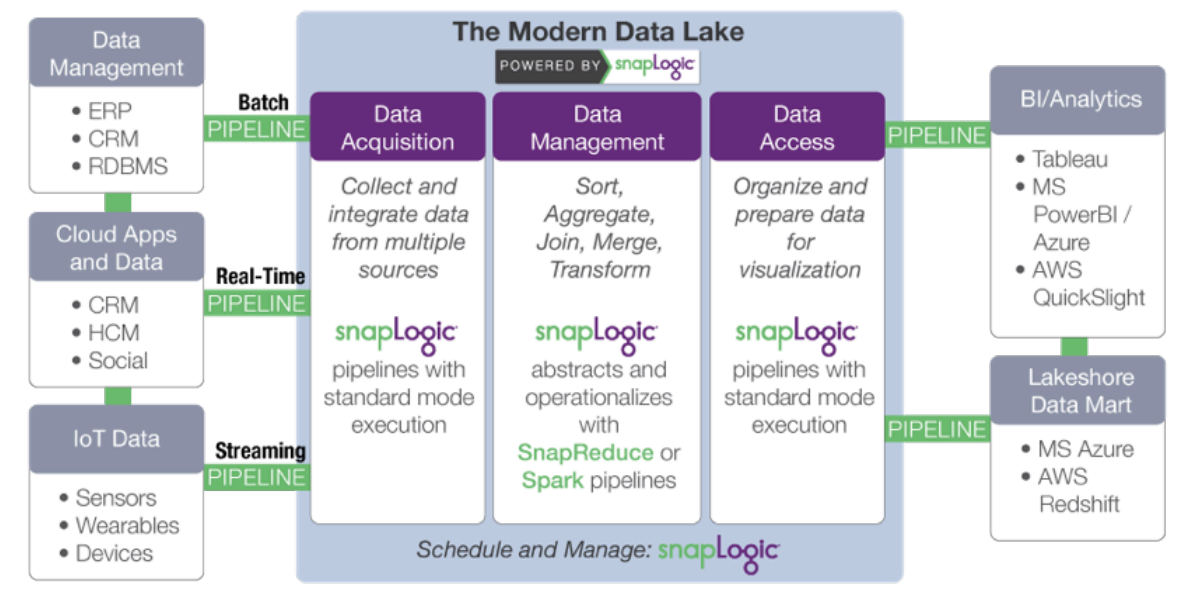
In particolare, SnapLogic accelera lo sviluppo di un moderno data lake attraverso:
- Acquisizione di dati: raccolta e integrazione di dati da più fonti. SnapLogic va oltre gli strumenti per sviluppatori come Sqoop e Flume, grazie a un designer di pipeline visuale basato su cloud e a connettori precostituiti per oltre 350 fonti di dati strutturati e non strutturati, applicazioni aziendali e API.
- Trasformazione dei dati: aggiunta di informazioni e trasformazione dei dati. Ridurre al minimo le attività manuali associate alla
trasformazione dei dati e rendere più efficienti i data scientist e gli analisti. SnapLogic include Snaps per attività quali trasformazioni, join e unioni senza scripting. - Accesso ai dati: organizzare e preparare i dati per la consegna e la visualizzazione. Rendere i dati elaborati su Hadoop
o Spark facilmente disponibili per applicazioni e archivi di dati esterni al cluster, come pacchetti statistici e strumenti di business intelligence.
L'approccio "platform-agnostic" di SnapLogic disaccoppia le specifiche di elaborazione dei dati dall'esecuzione. Quando il volume dei dati o i requisiti di latenza cambiano, è possibile utilizzare la stessa pipeline semplicemente cambiando la piattaforma dati di destinazione. SnapReduce di SnapLogic consente di eseguire SnapLogic in modo nativo su Hadoop come risorsa gestita da YARN che si espande in modo elastico per alimentare l'analisi dei big data, mentre Spark Snap aiuta gli utenti a creare pipeline di dati basate su Spark, ideali per processi iterativi ad alta intensità di memoria. Che si tratti di MapReduce, Spark o di un altro framework di elaborazione dei big data, SnapLogic consente ai clienti di adattarsi all'evoluzione dei requisiti dei data lake senza vincolarsi a un framework specifico.
Lo chiamiamo "Hadoop per umani " .
Prossimi passi:
- Scarica il whitepaper: Come costruire un Data Lake aziendale: Considerazioni importanti prima di iniziare. È inoltre possibile guardare la registrazione del webinar e consultare le diapositive sul blog di SnapLogic.
- Scaricate il whitepaper: Il Data Lake affogherà il Data Warehouse?
- Guardate questa dimostrazione di SnapReduce e SnapLogic Hadooplex per conoscere il nostro approccio "Hadoop for Humans" all'integrazione dei big data.