





Microsoft Azure HDInsight è una distribuzione Apache Hadoop alimentata da cloud. Internamente HDInsight sfrutta la piattaforma dati Hortonworks. HDInsight supporta un'ampia serie di progetti Apache per i big data come Spark, Hive, HBase, Storm, Tez, Sqoop, Oozie e molti altri. La suite di progetti HDInsight può essere amministrata tramite Apache Ambari.
 Questo post elenca i passaggi necessari per l'avvio di un cluster HDInsight, l'impostazione di SnapLogic e l'installazione di un cluster. Hadooplex su HDInsight e la costruzione ed esecuzione di una pipeline di flussi di dati Spark su HDInsight. Si inizia con l'avvio di un cluster HDInsight dal portale MS Azure.
Questo post elenca i passaggi necessari per l'avvio di un cluster HDInsight, l'impostazione di SnapLogic e l'installazione di un cluster. Hadooplex su HDInsight e la costruzione ed esecuzione di una pipeline di flussi di dati Spark su HDInsight. Si inizia con l'avvio di un cluster HDInsight dal portale MS Azure.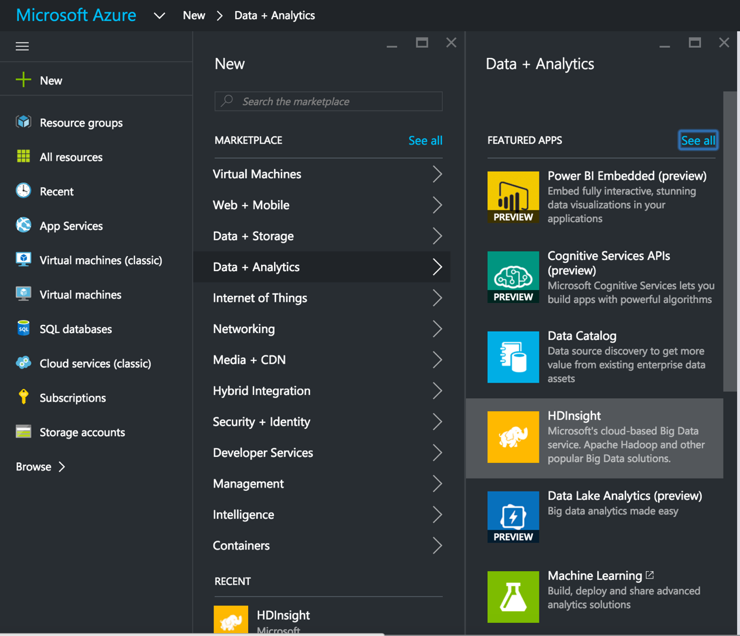
Dopo aver selezionato HDInsight, aggiungiamo il nome del cluster, il tipo di cluster e altri dettagli richiesti per avviare il cluster HDInsight. Per l'esecuzione delle pipeline Spark, selezionare Tipo di cluster come Spark, Sistema operativo come Linux e versione come Spark 1.6.1 (HDI 3.4).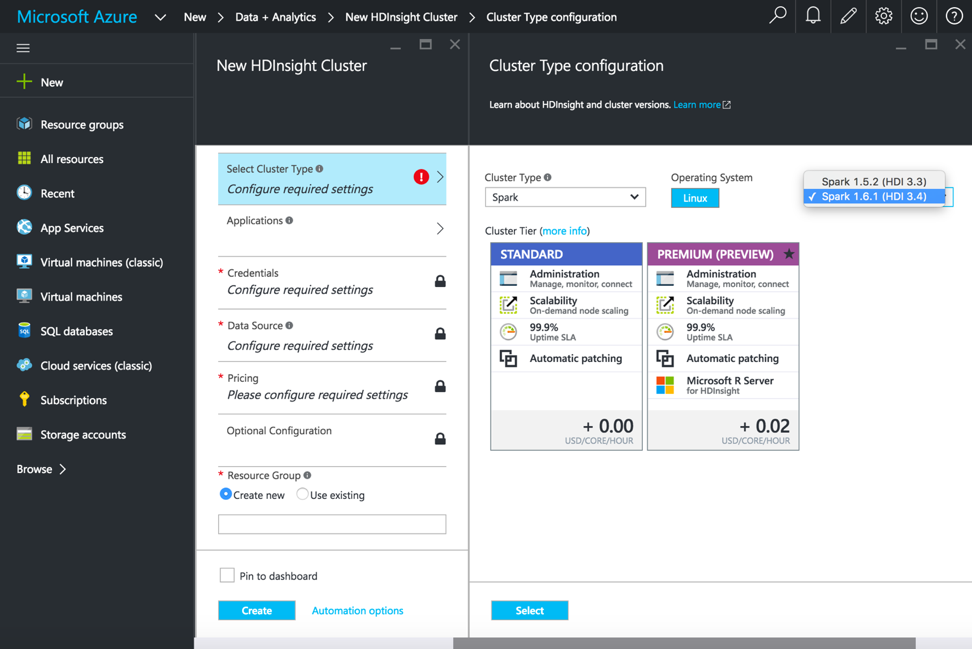
Una volta che il cluster HDInsight è attivo e funzionante, accedere alla console per creare e configurare un Hadoooplex SnapLogic.
Dalla dashboard assicurarsi che il Master Hadooplex e il nodo si siano registrati nel piano di controllo di SnapLogic.
A questo punto, siamo pronti a creare ed eseguire una pipeline Spark su HDInsight. Qui creerò una pipeline Spark molto semplice per dimostrare la lettura di un file e il suo ritorno al blob di archiviazione di Azure con alcune semplici trasformazioni.
Dal Progettista SnapLogic creo una nuova pipeline di Spark.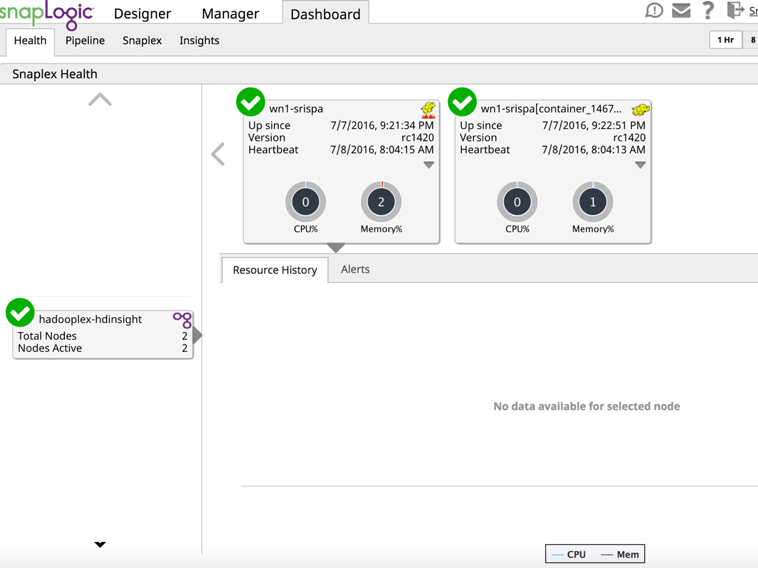
A questo punto, siamo pronti a creare ed eseguire una pipeline Spark su HDInsight. Qui creerò una pipeline Spark molto semplice per dimostrare la lettura di un file e il suo ritorno al blob di archiviazione di Azure con alcune semplici trasformazioni.
Dal pannello SnapLogic Designer creo una nuova pipeline Spark.
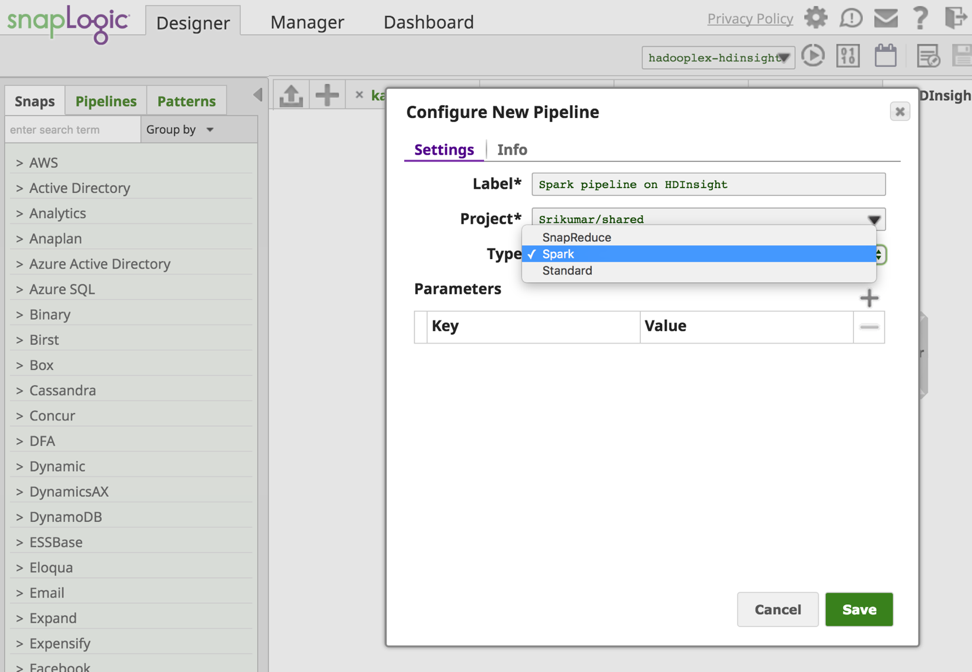
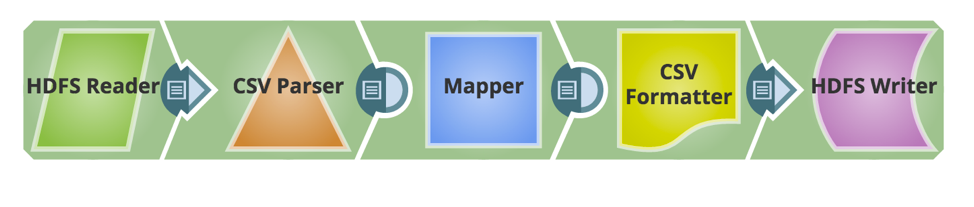
Ora vengono aggiunti gli snap necessari per costruire la pipeline. Di seguito è riportata l'istantanea della pipeline.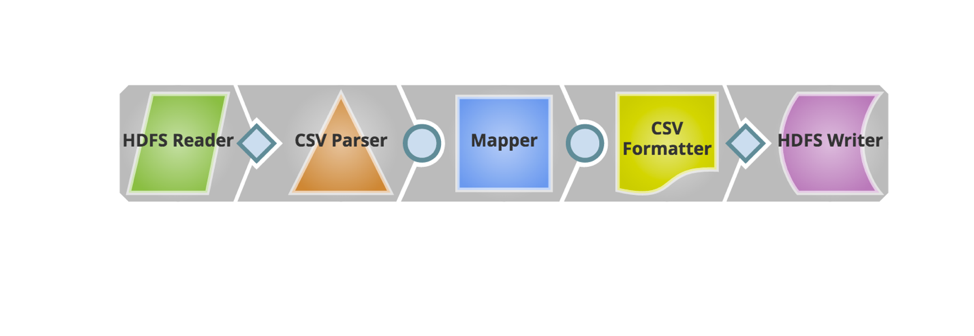
HDInsight utilizza lo storage Azure Blob come archivio di big data per HDFS. SnapLogic supporta il protocollo Windows Azure Storage Blob (WASB), che è un'estensione costruita sopra l'API di HDFS.
Il passo successivo consiste nel configurare un account Azure Storage e leggere/scrivere i dati dal blob Azure Storage utilizzando HDFS Reader & Writer.
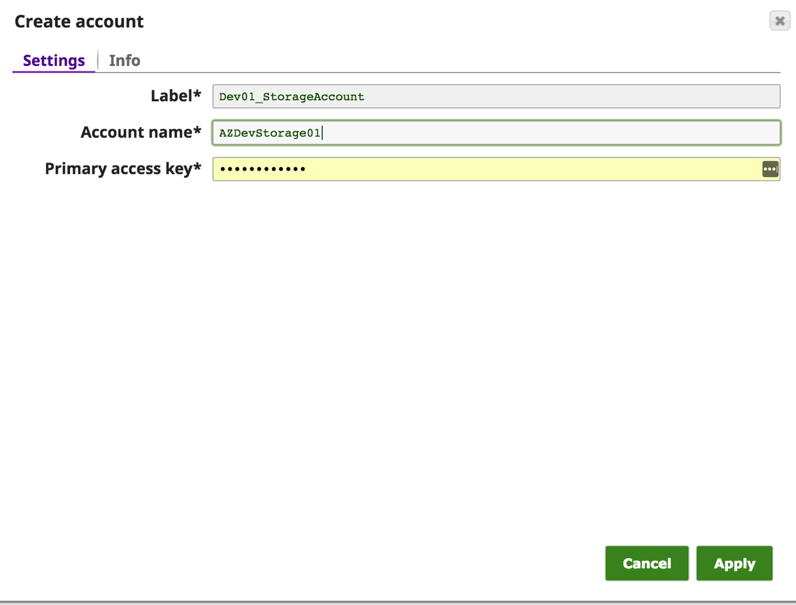
Dalla scheda "Accounts" di HDFS Reader (o HDFS Writer) faremo clic sul pulsante "Add Account" per configurare i dettagli dell'account. In "Opzioni di creazione dell'account" scegliete la posizione in cui salvare la configurazione dell'account e selezionate il tipo di account come "Azure Storage" e fate clic sul pulsante "OK". 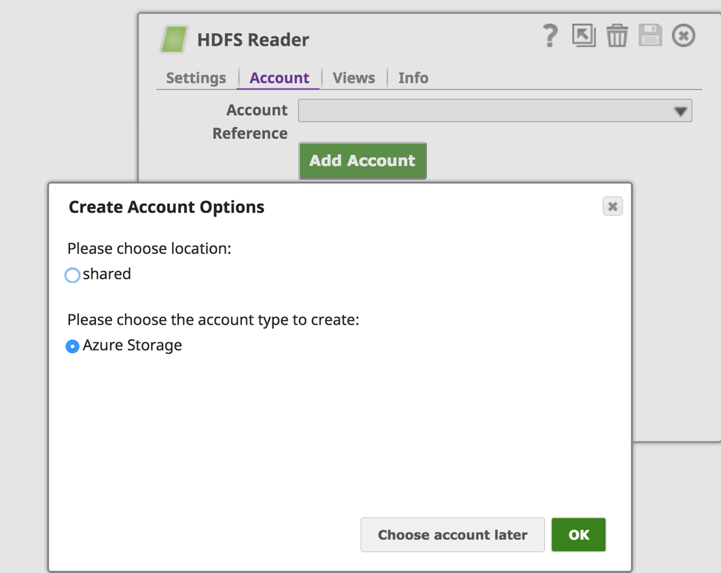
Nella finestra di dialogo "Crea account", inserire il nome dell'account Azure e la chiave di accesso primaria. Questi dettagli sono disponibili nel portale Azure -> Account di archiviazione -> Impostazioni -> Chiavi di accesso.
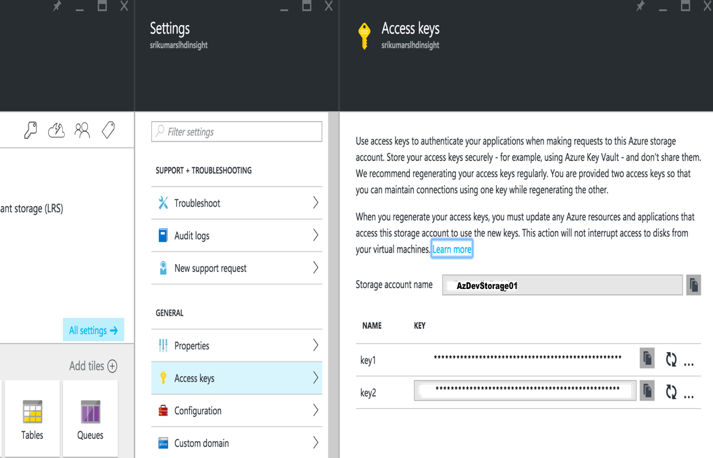
Salvare l'account e ora è possibile accedere ai dati dal blob di Azure utilizzando il file wasb:///containername/path_to_file
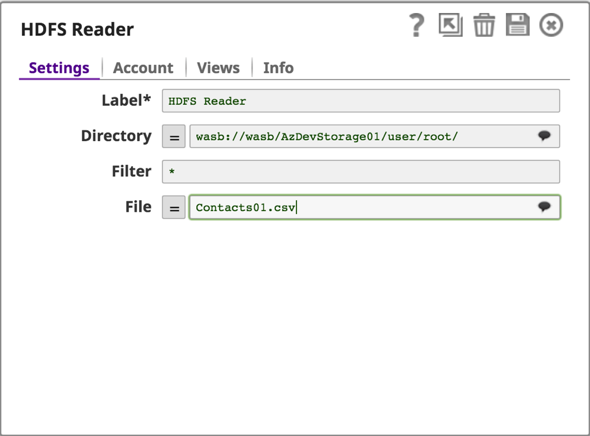
Configurare il resto della pipeline per trasformare e riportare i dati in una cartella di output su Azure Storage Blob.
Ora convalidiamo ed eseguiamo la pipeline. La schermata seguente mostra l'esito positivo della convalida e dell'esecuzione della pipeline di Spark.
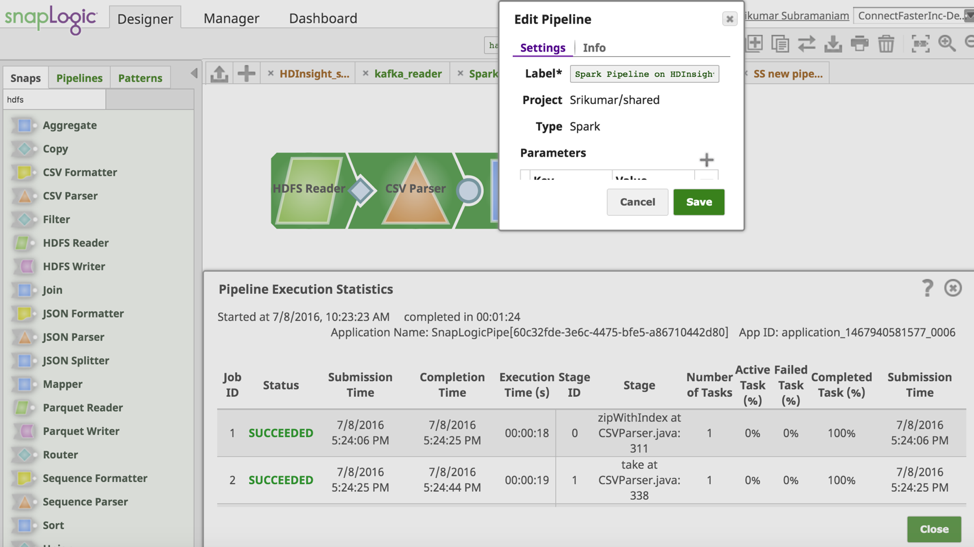
Il supporto per HDInsight consente di sfruttare la potenza di SnapLogic Elastic Integration Platform per accelerare le integrazioni sulla piattaforma Microsoft Azure. Ulteriori informazioni su SnapLogic per Microsoft Azure sono disponibili qui.






