





Ho la fortuna di lavorare sia in ambito accademico che industriale. Oltre al mio lavoro presso SnapLogic, sono professore di informatica presso l'Università di San Francisco e negli ultimi 20 anni ho lavorato alla ricerca sui sistemi distribuiti, sulla programmazione parallela, sui kernel dei sistemi operativi e sui linguaggi di programmazione. Questi due ruoli sono stati reciprocamente vantaggiosi. Sono in grado di applicare la mia ricerca ai sistemi del mondo reale e di portare questa esperienza in classe. In SnapLogic ho lavorato per far progredire la tecnologia dei nostri prodotti e recentemente ho fatto parte del team di architettura originale del nostro nuovo prodotto di integrazione basato su cloud, che è un sofisticato sistema distribuito. Ora che abbiamo rilasciato il prodotto, possiamo discutere molti degli aspetti tecnici e delle decisioni di progettazione del sistema.
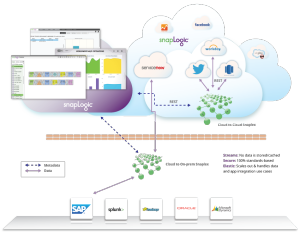
Nello sviluppo della nostra Integration Platform as a Service (iPaaS) di SnapLogic, abbiamo rivalutato alcuni dei principi di progettazione fondamentali presenti nei prodotti di integrazione tradizionali, retaggio dei primi tempi dell'ETL. Una delle nostre innovazioni più profonde nell'architettura è l'impiego di documenti simili a JSON come mezzo principale per il trasporto dei dati da Snap a Snap in una pipeline. Le vecchie tecnologie di integrazione erano orientate ai record, che si adattavano bene al mondo dei database relazionali dell'epoca. Tuttavia, oggi vediamo che formati gerarchici come JSON e XML sono utilizzati sia a livello di interfaccia di servizio, come REST e SOAP, sia a livello di datastore, come in MongoDB.
L'uso di Documents come tipo di dati nativo comporta diversi vantaggi sia per l'elaborazione dei dati che per gli utenti finali:
-
I documenti si adattano meglio ai moderni servizi web.
-
I documenti si traducono in pipeline più sintetiche.
-
Un modello di documento permette alle pipeline di essere accoppiate in modo lasco.
-
Un modello di documento consente un maggiore riutilizzo della pipeline.
- I documenti sono un sottoinsieme dei record.
Servizi Web moderni
Mentre alcuni servizi web utilizzano ancora SOAP, un numero crescente di interfacce RESTful utilizza JSON come formato di dati per le richieste e le risposte. In entrambi i casi, i dati sono gerarchici. Il supporto per i documenti consente agli endpoint di Snap di consumare direttamente i dati gerarchici in formato nativo e di inviarli agli Snap a valle in una pipeline. Ciò significa che non è necessario appiattire i dati in record o trasformare un documento JSON in una stringa o in un BLOB. Questo supporto nativo consente a tutti gli snap, come Filter, Join, Sort, ecc. di prendere decisioni basate su qualsiasi campo, eventualmente annidato, all'interno di un documento. I dati del documento risultante possono essere inviati direttamente a uno Snap di output che eventualmente si connette a un altro servizio web che consuma JSON. Il nostro modello di documento nativo semplifica l'elaborazione dei moderni dati web nel loro formato nativo.
Sebbene XML e JSON siano entrambi gerarchici, stiamo notando che un numero crescente di servizi web e API espone i dati in formato JSON, grazie alla sua leggerezza e alla rappresentazione più compatta. XML tende a gonfiare i dati in modo significativo con i suoi incapsulamenti di meta-tag.
Condotte succinte
Il nostro modello di documento porta a Pipeline più sintetiche, perché non è necessario tradurre JSON o XML in record piatti, quindi eseguire l'elaborazione e infine riconvertire i record in JSON o XML. Questo permette agli utenti di concentrarsi sull'elaborazione dei dati e non sulla loro traduzione, rendendo il lavoro in SnapLogic più produttivo e meno soggetto a errori. Il minor numero di passaggi di traduzione dei dati migliora anche le prestazioni della pipeline in termini di throughput e latenza.
Accoppiamento allentato
La precedente generazione di prodotti di integrazione collegava i componenti del flusso di dati tramite collegamenti digitati. Ciò significa che per collegare un componente a un altro, tutti i campi e i tipi di output dovevano essere correttamente collegati ai campi e ai tipi di input del componente di destinazione. Questa mappatura è necessaria tra tutti i componenti di un grafo dataflow. Se da un lato questo accoppiamento porta a una certa sicurezza dei tipi, dall'altro è molto complicato manipolare le pipeline collegate in questo modo. In effetti, SnapLogic ha un brevetto in corso di registrazione sul Predictive Field Linking, per facilitare la costruzione di pipeline basate su un collegamento rigoroso dei campi.
Poiché il nostro tipo di dati principale è un documento, quasi tutti gli snap consumano o producono documenti. La connessione degli snap non richiede più il collegamento dei campi. Ciò consente agli utenti di mettere in funzione le pipeline più rapidamente, poiché è possibile collegare semplicemente gli snap, provarli e riorganizzarli. È ancora possibile ottenere una mappatura esplicita dei campi; ad esempio, il campo nome_nome può essere mappato su Nome_nome, ma ora viene eseguito in uno snap di mappatura separato. Questo ha l'ulteriore vantaggio di poter incapsulare le mappature dei campi, in modo da poterle riutilizzare facilmente nella stessa pipeline o in pipeline diverse.
Riutilizzo delle condutture
In relazione al loose coupling, il modello documentale supporta meglio il riutilizzo delle pipeline. Senza un rigido collegamento dei campi, le pipeline annidate sono molto più facili da assemblare attraverso il riutilizzo di altre pipeline. In un certo senso, siamo passati a un approccio tipizzato dinamicamente da un approccio tipizzato staticamente come nei linguaggi di programmazione. L'approccio dinamico porta a pipeline più compatte e più facili da interconnettere. Questa facilità di interconnessione favorisce anche il test unitario delle sottopipeline, in modo da ottenere più rapidamente un'esecuzione corretta.
Documenti come registrazioni
Noi di SnapLogic riconosciamo che, mentre i moderni servizi web e i datastore si stanno dirigendo verso JSON, le aziende utilizzano ancora i database relazionali per i dati normalizzati e transazionali. Il bello dei documenti è che sono un superset dei record relazionali. Quando si converte un record in un documento, si combinano i nomi delle colonne dello schema con i dati dei campi per creare un documento chiave/valore. Questo ci permette di consumare i record e di produrre i record secondo le necessità, ottenendo comunque tutti i vantaggi del modello documentale. Inoltre, supportiamo le operazioni ETL tradizionali come JOIN, AGGREGATE e SORT sui documenti. Questo permette di trattare senza problemi i dati principalmente relazionali, ma anche di estendere queste operazioni ETL in modo da supportare i documenti gerarchici.
Conclusione
In risposta all'evoluzione dei punti finali di integrazione e dei formati dei dati, abbiamo riprogettato molti aspetti del funzionamento dell'integrazione nella nostra nuova Integration Platform as a Service. Il nostro approccio incentrato su JSON abbraccia le moderne interfacce web e supporta perfettamente i dati relazionali. Questo supporto nativo per i documenti è una delle tante innovazioni architettoniche che abbiamo sviluppato per aiutare le aziende a collegare sia i servizi web che i datastore tradizionali.



