





Nel whitepaper " Come costruire un Data Lake aziendale: Important Considerations Before You Jump In, l'esperto del settore Mark Madsen ha delineato i principi che devono guidare la progettazione della nuova architettura di riferimento e alcune delle differenze rispetto al data warehouse tradizionale. Nel suo documento successivo, "Will the Data Lake Drown the Data Warehouse" (Illago di dati affogherà il magazzino di dati), pone la domanda: "Che cosa significa questo per gli strumenti che abbiamo usato negli ultimi dieci anni?".
In questo ultimo della serie di post tratti da questo articolo (vedi il primo post qui e il secondo qui) Mark scrive di come affrontare l'integrazione dei big data utilizzando un esempio:
"Il modo migliore per vedere la sfida che si presenta quando si costruisce un data lake è concentrarsi sull'integrazione nell'ambiente Hadoop. Un punto di partenza comune è l'idea di spostare l'ETL e l'elaborazione dei dati dagli strumenti tradizionali ad Hadoop, per poi trasferire i dati da Hadoop a un data warehouse o a un database come Amazon Redshift, in modo che gli utenti possano continuare a lavorare con i dati in modo familiare. Se analizziamo alcuni aspetti specifici di questo scenario, il problema dell'utilizzo di una distinta base come guida tecnologica diventa evidente. Ad esempio, l'elaborazione dei log degli eventi web è ingombrante e costosa in un database, quindi molte aziende spostano questo carico di lavoro su Hadoop".
La tabella seguente riassume i requisiti di elaborazione dei log in uno scenario di offload ETL e i componenti che possono essere utilizzati per implementarli in Hadoop:
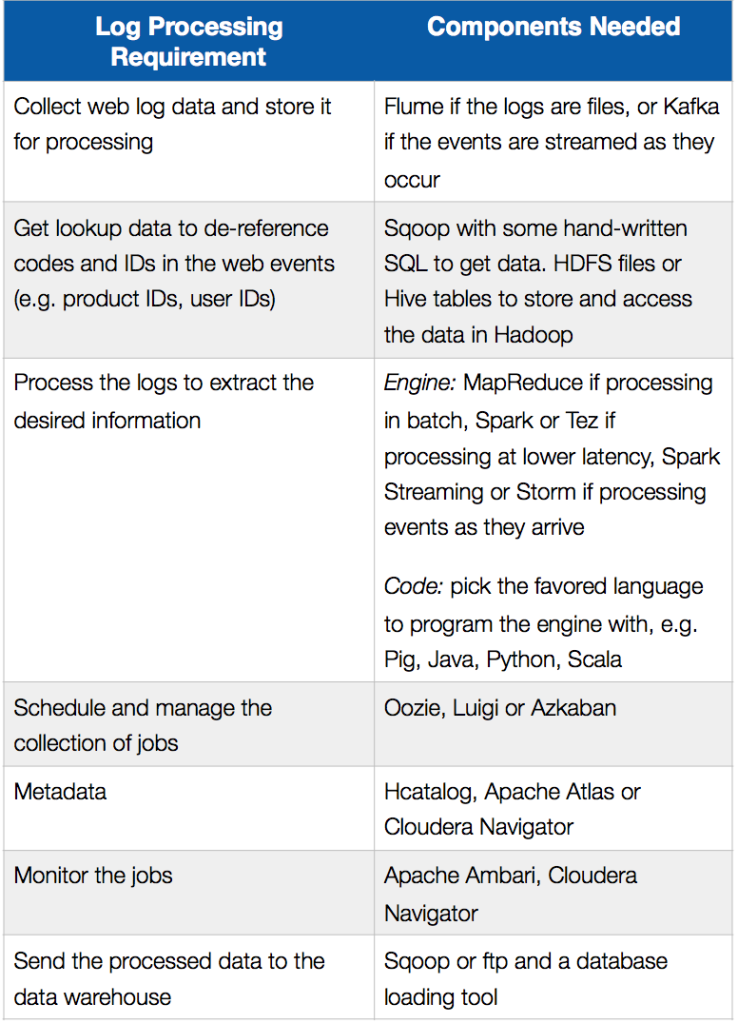
L'autore passa poi in rassegna le sfide di sviluppo e i compromessi che comporta seguire questo tipo di approccio e conclude:
"La costruzione di un data lake richiede una riflessione sulle capacità necessarie al sistema. Si tratta di un problema più grande della semplice installazione e utilizzo di progetti open source su Hadoop. Così come l'integrazione dei dati è alla base del data warehouse, una capacità di elaborazione dei dati end-to-end è il cuore del data lake. Il nuovo ambiente ha bisogno di un nuovo cavallo di battaglia".
Le prossime tappe:
- Scarica il whitepaper: Come costruire un Data Lake aziendale: Considerazioni importanti prima di iniziare. È inoltre possibile guardare la registrazione del webinar e consultare le diapositive sul blog di SnapLogic.
- Scaricate il whitepaper: Il Data Lake affogherà il Data Warehouse?
- Guardate questa dimostrazione di SnapReduce e SnapLogic Hadooplex per conoscere il nostro approccio "Hadoop for Humans" all'integrazione dei big data.




