






Oggi le organizzazioni sono alla ricerca di analisi predittive che le guidino verso il futuro. Ogni organizzazione ha bisogno di modelli di apprendimento automatico personalizzati, costruiti per le proprie esigenze aziendali specifiche. Nei servizi finanziari, un modello valido prevede quale mutuatario ha maggiori probabilità di non pagare il prestito, quale prodotto mutualistico è adatto a un cliente, ecc. Ma gli ingegneri dei dati e i data scientist devono affrontare una serie di sfide quando costruiscono modelli di apprendimento automatico efficaci, come la scarsa qualità del set di dati di addestramento, i lunghi tempi di preparazione dei dati per l'addestramento e le grandi quantità di dati necessari per addestrare i modelli.
In questo post esploreremo il caso d'uso di un servizio finanziario che valuta le informazioni sui prestiti per prevedere se un mutuatario sarà inadempiente. Il set di dati di base è stato ricavato dai dati sui prestiti di LendingClub. Questo set di dati contiene i dati dei prestatori sui prestiti concessi agli individui. I dati saranno poi arricchiti con i dati sulla disoccupazione di Knoema sullo Snowflake Data Marketplace. Utilizziamo SnapLogic per trasformare e preparare i dati che potrebbero poi essere utilizzati per costruire modelli ML.
Prerequisiti
Questo post presuppone che abbiate i seguenti requisiti:
- Il conto di un fiocco di neve
- Dati in una tabella in Snowflake
- Un bucket Amazon Simple Storage Service (Amazon S3) dove SnapLogic può caricare il modello ML creato.
Impostare l'origine dati in SnapLogic
In questa sezione si illustra l'impostazione di Snowflake come origine dati in SnapLogic. Questo post presuppone che abbiate accesso a SnapLogic. Per ulteriori informazioni sui prerequisiti, vedere Guida introduttiva a SnapLogic.
Creare una nuova pipeline
Per creare una pipeline, completare i seguenti passaggi:
- In Designer, fare clic sull'icona [+] a sinistra delle schede. Si apre la finestra di dialogo Configura nuova pipeline.
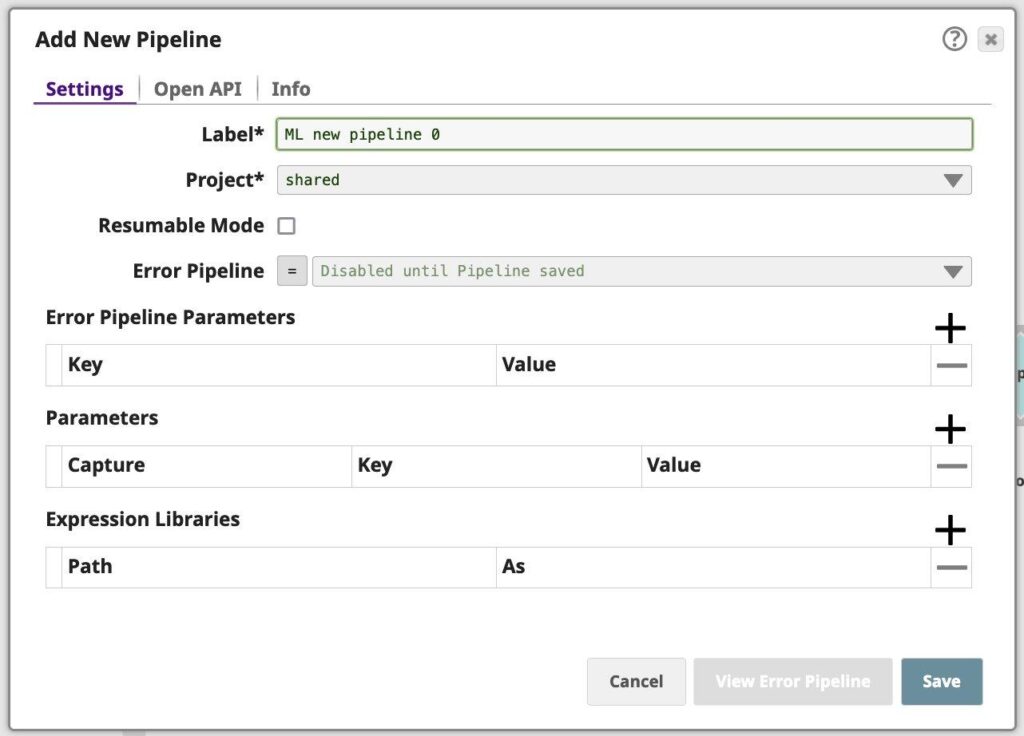
Figura 1: Scheda delle proprietà del gasdotto - Modify the Label (pipeline name) and project for the pipeline if necessary. Unless otherwise noted, the names of any asset or project is limited to UTF-8 alphanumeric characters and these punctuation characters !”#$%&'()*+,-.:;<=>?@[\]^_`{|}~.
- Se si conoscono dei parametri da definire per questa pipeline, è possibile farlo ora o in seguito attraverso la finestra di dialogo Proprietà della pipeline.
- Se si utilizza una libreria di espressioni, è possibile aggiungerla ora o in seguito attraverso la finestra di dialogo Proprietà della pipeline.
- Fare clic su Salva.
Aggiungere Snowflake come origine dati in SnapLogic
Quindi, aggiungiamo Snowflake come origine dati.
- Trascinare un fiocco di neve - Selezionare Snap sulla tela e fare clic su Snap per aprire le sue impostazioni. Fare clic sulla scheda Account. È ora possibile crearne uno nuovo.
- Fare clic su Aggiungi conto nella finestra di dialogo Riferimento conto.
- Selezionare la località in cui si desidera creare l'account, selezionare Account del database Snowflake S3 come tipo di conto e fare clic su Continua. Viene visualizzata la finestra di dialogo Aggiungi conto associata al tipo di conto.
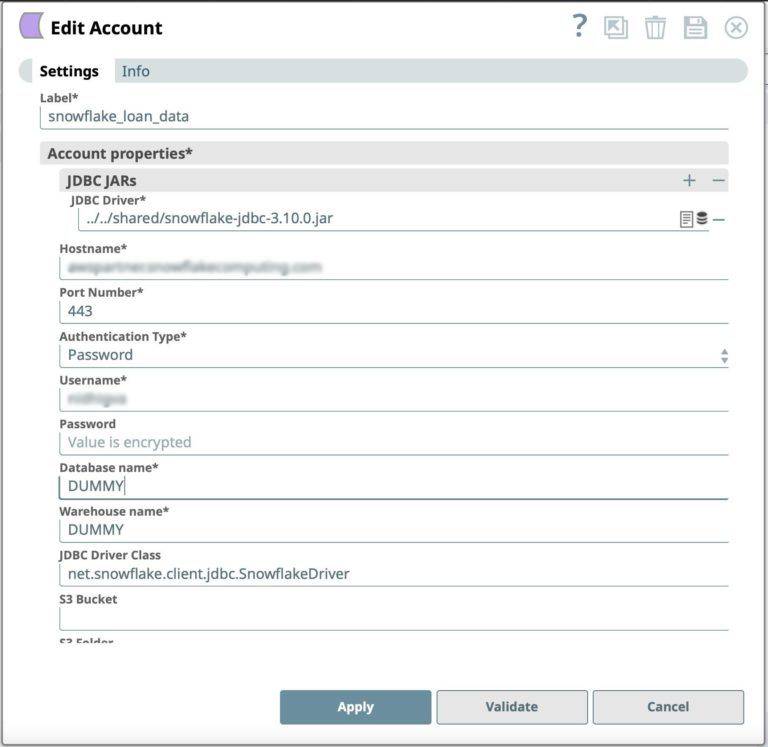
Figura 2: Definizione dell'account Snowflake Snap - Fare clic su Convalida per verificare il conto, se il tipo di conto supporta la convalida.
- Fare clic su Applica per completare la configurazione dell'account Snowflake.
- Andare alla scheda Impostazioni
- Selezioniamo la tabella in cui abbiamo già caricato i dati dei prestiti da Lending Club.
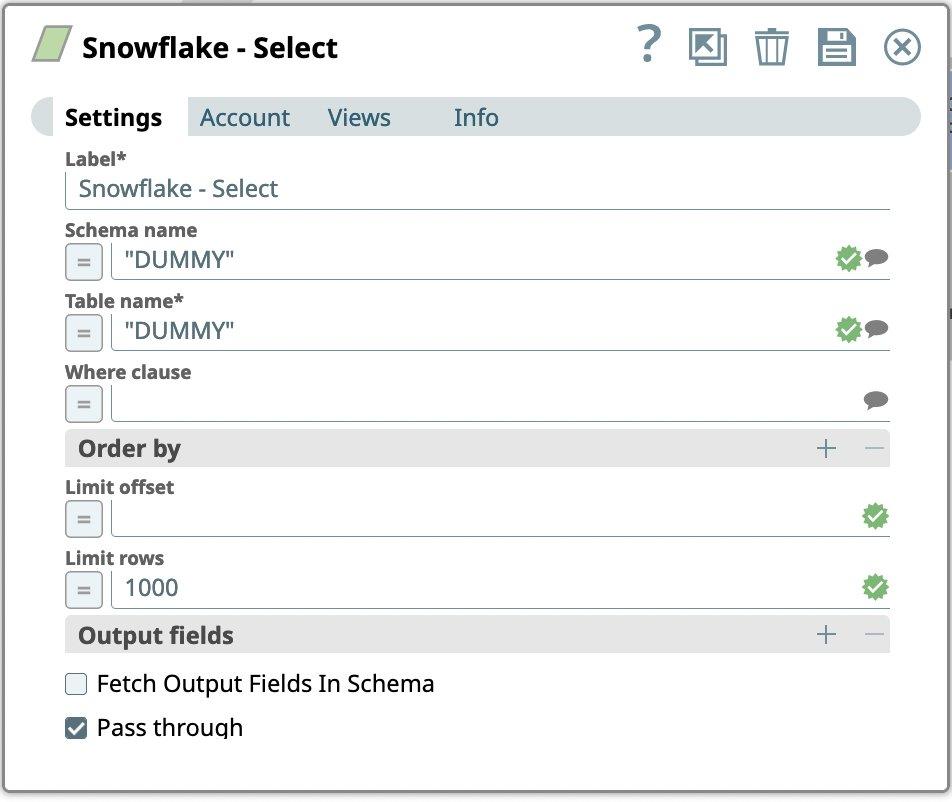
- Per l'account Snowflake inserire:
- Nome dello schema
- Nome della tabella
- Impostare Limite righe a 1000
- Premere l'icona Salva
Aggiungere gli snap ML alla pipeline per l'apprendimento automatico utilizzando SnapLogic
SnapLogic Data Science include i seguenti Snap Pack ML per accelerare i progetti di ML.
- ML Data Preparation Snap Pack - ML Data Preparation Snap Pack automatizza diverse attività di preparazione dei dati per un modello di apprendimento automatico. SnapLogic Data Science semplifica il processo di preparazione dei dati e di ingegnerizzazione delle caratteristiche mediante un'interfaccia visiva.
- ML Core Snap Pack - ML Core Snap Pack accelera la costruzione, l'addestramento e il test del modello di apprendimento automatico. Sfruttate ML Core Snap Pack per semplificare la fase di formazione e valutazione del modello nel ciclo di vita dell'apprendimento automatico.
- ML Analytics Snap Pack - ML Analytics Snap Pack crea più rapidamente dataset di formazione migliori per i vostri modelli di apprendimento automatico. Con ML Analytics Snap Pack potete ottenere rapidamente informazioni dai vostri dati.
- Natural Language Processing Snap Pack - Il Natural Language Processing Snap Pack esegue operazioni di elaborazione del linguaggio naturale.
Eliminare le righe con valori mancanti
Il primo passo che vogliamo eseguire è quello di elaborare i valori mancanti in un set di dati eliminando o imputando (sostituendo) i valori.
- Trascinare lo snap Clean Missing Values sulla Tela e fare clic sullo snap per aprire le impostazioni.
- Aggiungere le colonne REVOL_UTIL per eliminare le righe dal dataset in entrata se il valore è mancante
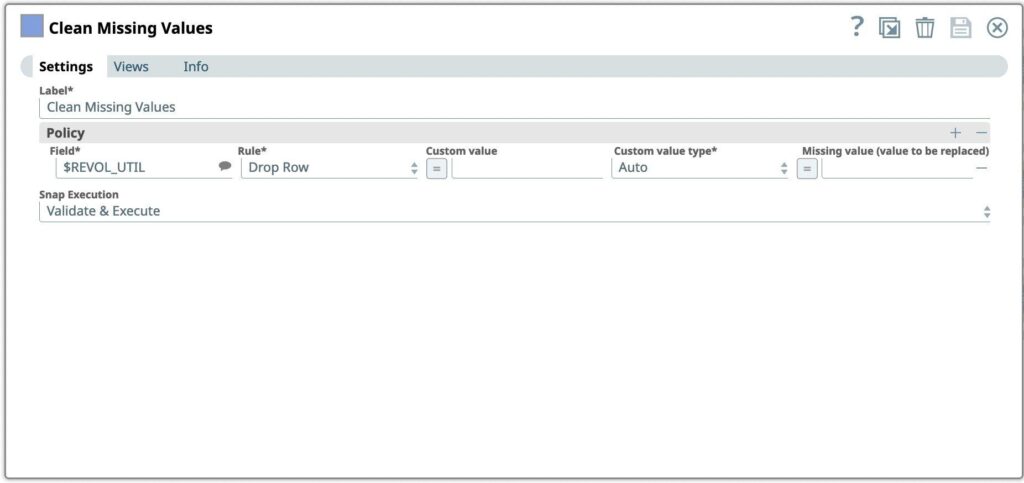
Figura 4: Pulizia dei valori mancanti Impostazioni di Snap
Trasformare i dati
Poi vogliamo trasformare i dati in arrivo utilizzando le mappature date e produrre nuovi dati in uscita. Questo Snap valuta un'espressione e scrive il risultato nel percorso di destinazione specificato.
- Trascinare lo snap Mapper sulla Tela e fare clic sullo snap per aprire le impostazioni.
- Esaminando le colonne, si nota che MNTHS_SINCE_LAST_DELINQ e MNTHS_SINCE_LAST_RECORD dovrebbero essere rappresentate come un tipo di numero, piuttosto che come una stringa.
- Esaminando i dati, possiamo vedere che i campi EMP_TITLE, URL, DESCRIPTION e TITLE probabilmente non forniranno valore al nostro modello nel nostro caso d'uso, quindi li eliminiamo.
- Successivamente, cerchiamo le colonne che sono dati stringa che possono essere formattati per essere più utili in seguito. Esaminando il nostro set di dati, possiamo vedere che INT_RATE potrebbe essere utile in un modello futuro come float, ma ha un carattere di separazione %. Prima di poter usare un'altra trasformazione integrata (parse as type) per convertire questo dato in un float, dobbiamo eliminare il carattere di separazione.
- Si aggiorna quindi il valore della stringa nella colonna TERM, per sostituire lo spazio con '_'.
- Creiamo una nuova colonna booleana LOAN_STATUS basata su LOAN_DEFAULT.
- Fare clic sul segno [+] accanto alla tabella di mappatura per aggiungere una nuova espressione. Trasformazione da applicare per convertire i dati nelle colonne:
Espressione* Percorso di destinazione parseFloat(+$MNTHS_SINCE_LAST_DELINQ) MESI_DALL'ULTIMO_DELINQ parseFloat(+$MNTHS_SINCE_LAST_RECORD) MESI_DALL'ULTIMA_REGISTRAZIONE parseFloat(+$INT_RATE.replace("%", "")) $INT_RATE_PERCENTUALE $TERM.replace(" mesi", "_mesi") $TERM $EMP_TITLE $URL $DESCRIZIONE $TITOLO $MESI_DALL'ULTIMO_MAGGIORE_DEROGA $LOAN_DEFAULT == 1 ? true:false $STATO_DI_PREDEFINITO_DEL_PRESTITO - Premere l'icona Salva
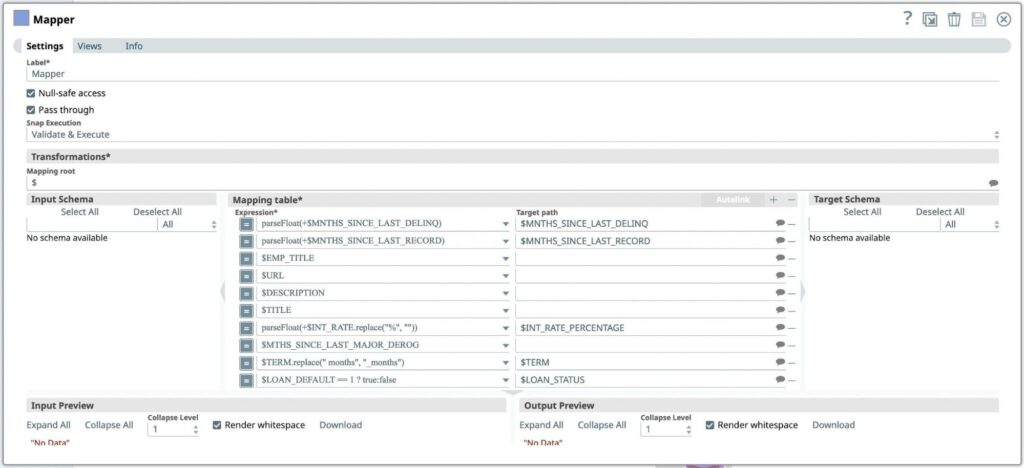
Figura 5: Impostazioni di Mapper Snap
Ottenere i dati sulla manodopera da Snowflake Marketplace
Ora aggiungeremo dati sul lavoro da Snowflake Marketplace che possono essere utili per migliorare i modelli ML. Potrebbe essere utile esaminare i dati sull'occupazione nella regione quando si analizzano le insolvenze dei prestiti. Si inserisce Knoema - Atlante dei dati sul lavoro da Snowflake Marketplace nel database Snowflake, dove i dati di carico sono già presenti.
Quindi, aggiungiamo Snowflake come origine dati.
- Trascinare un fiocco di neve - Esegui snap sulla tela e fare clic sullo snap per aprire le impostazioni. Fare clic sulla scheda Account.
- Selezionate il conto creato nel passaggio precedente dalla finestra Riferimento del conto dialogo.
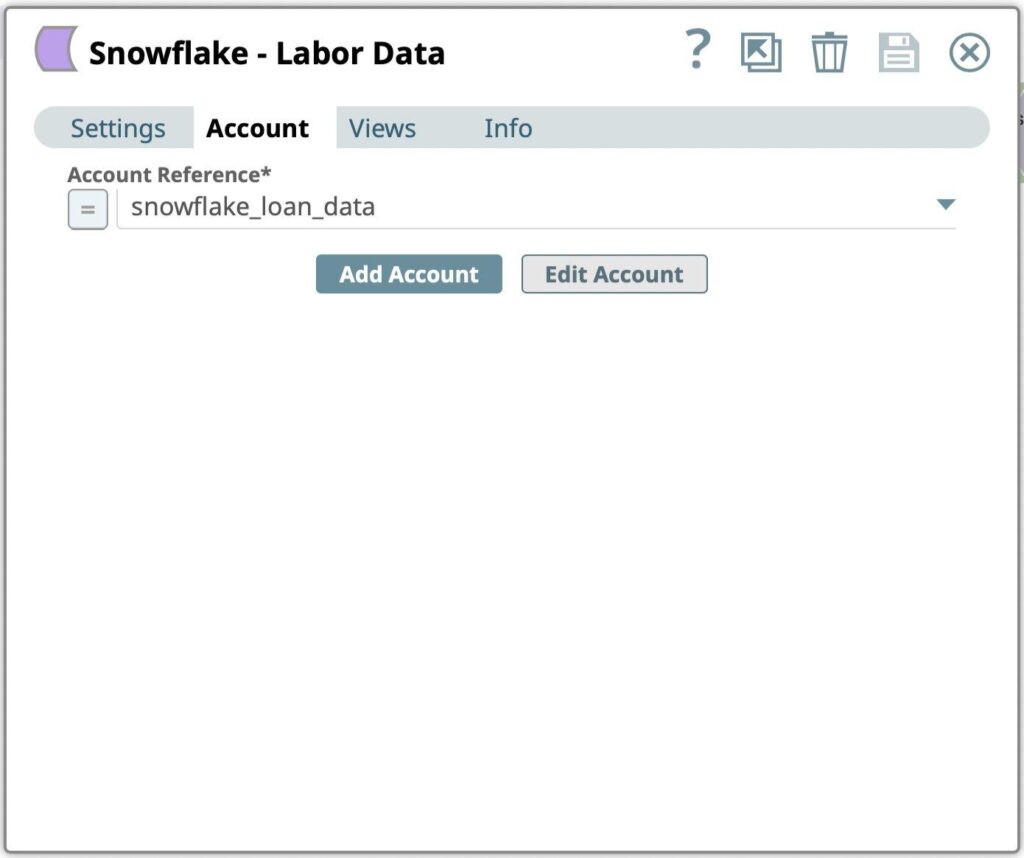
Figura 6: Selezione dell'account Snowflake Select Snap - Andare alla scheda Impostazioni
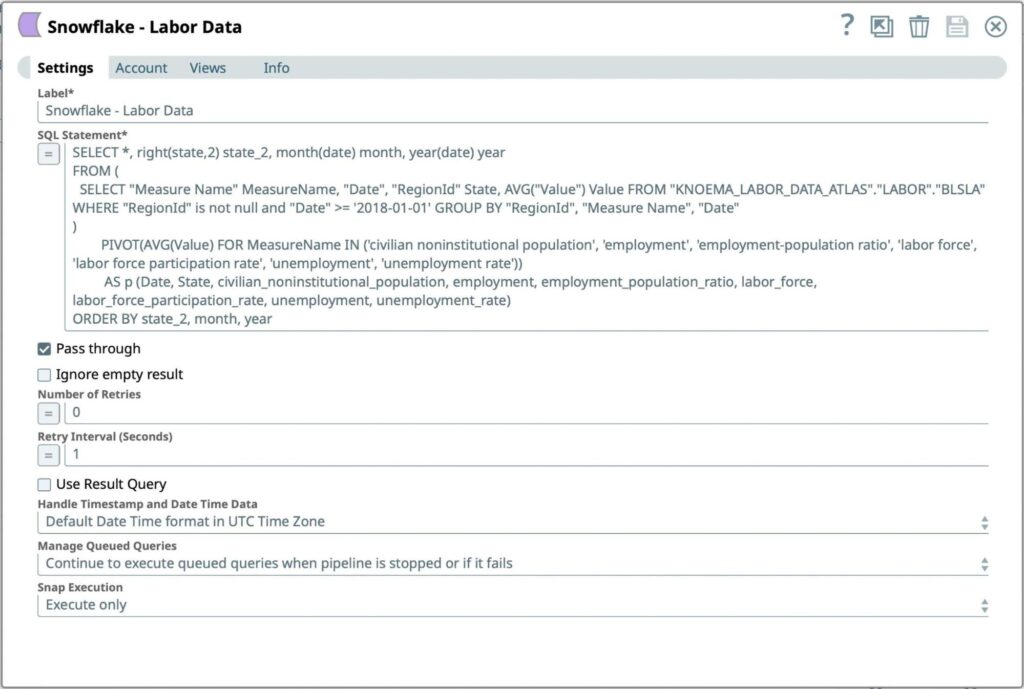
Figura 7: Impostazioni di Snowflake Select Snap - Inserire la query SQL da eseguire per recuperare i dati del lavoro formattati dal conto Snowflake:
- Dichiarazione SQL
- Premere l'icona Salva
Dati del profilo
- Trascinare lo snap Copia sulla Tela. Lasciare le impostazioni predefinite.
- Trascinare lo snap Profilo sulla Tela. Questo è utile per ricavare un'analisi statistica dei dati nei set di dati.
Eseguire una codifica a caldo
Successivamente, vogliamo cercare i dati categorici nel nostro set di dati. SnapLogic ha gli snap per codificare i dati categorici utilizzando sia la codifica a un punto che la codifica integrale. Osservando il nostro set di dati, possiamo notare che le colonne TERMINE, PROPRIETÀ DELLA CASA e SCOPO sembrano essere di natura categorica.
- Trascinate lo snap da Categorico a Numerico sulla Tela e fate clic sullo snap per aprire le impostazioni.
- Nelle impostazioni, in Criteri, inserire i nomi delle colonne come Campo e selezionare Codifica a caldo come Regola.
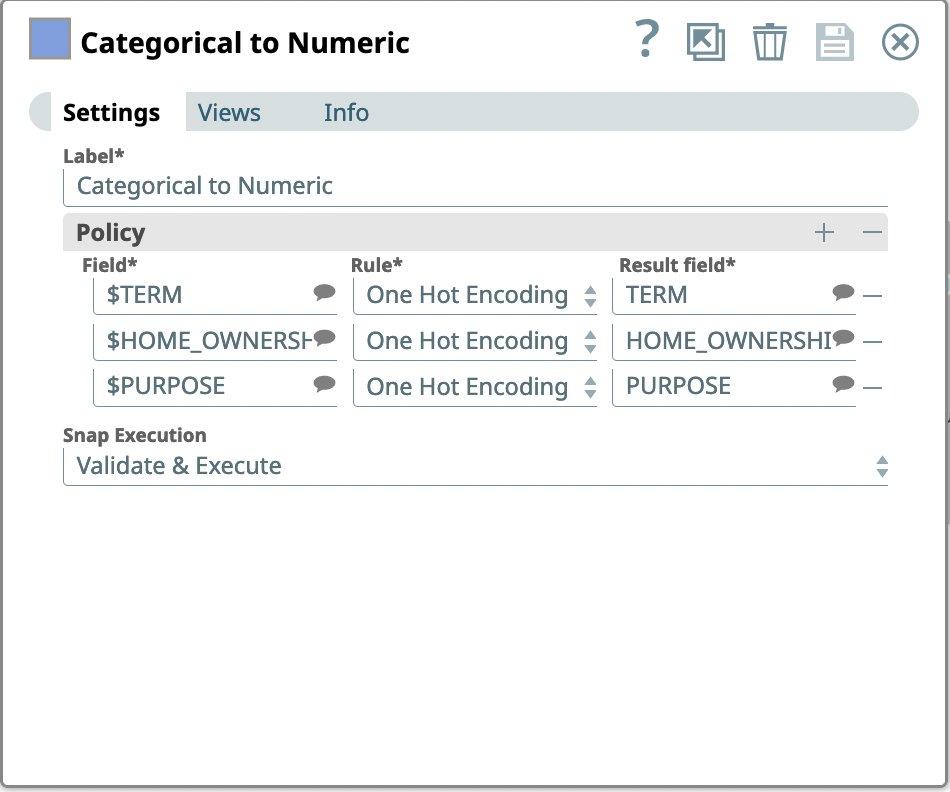
Figura 8: Impostazioni dello snap da categorico a numerico
Caricare i dati preparati in Snowflake
Quindi, aggiungiamo Snowflake come origine dati.
- Trascinare un fiocco di neve - snap di caricamento massivo sulla tela e fare clic sullo snap per aprirne le impostazioni. Fare clic sulla scheda Account.
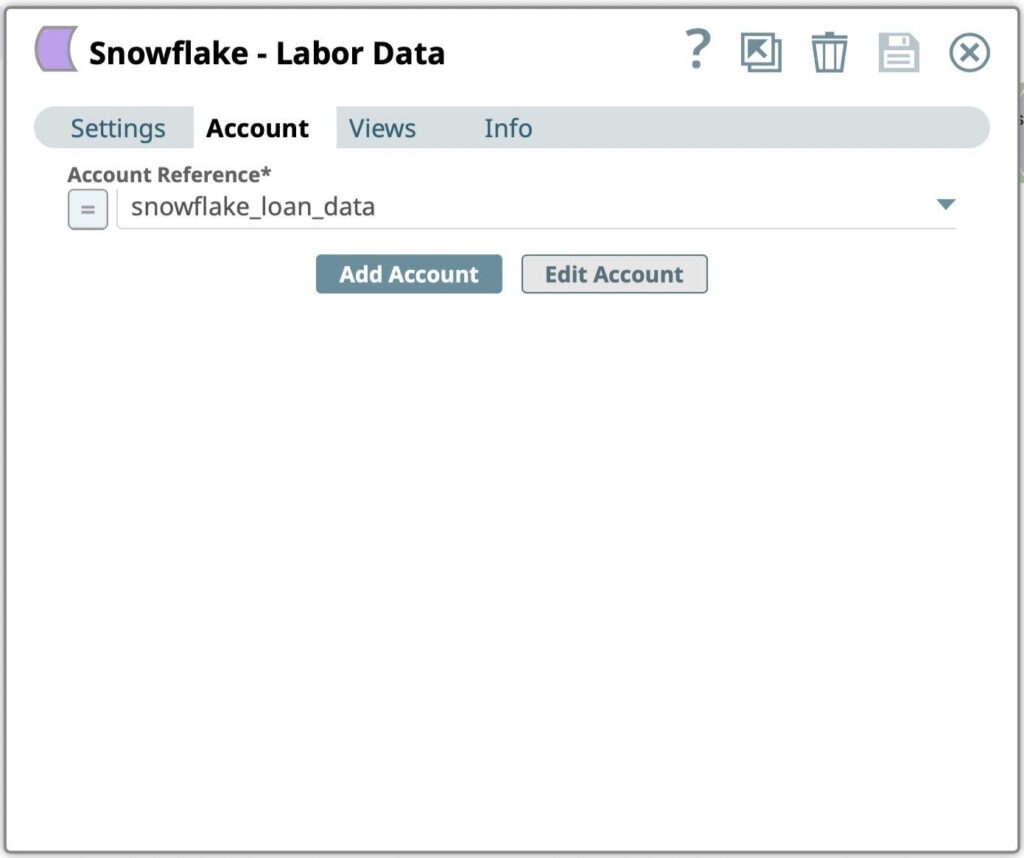
Figura 9: Impostazioni dell'account Snowflake Bulk Load Snap - Selezionare il conto creato nel passaggio precedente dalla finestra di dialogo Riferimento conto. Si può anche creare un nuovo account se si vuole archiviare il risultato in un database e in un magazzino Snowflake diversi.
- Andare alla scheda Impostazioni
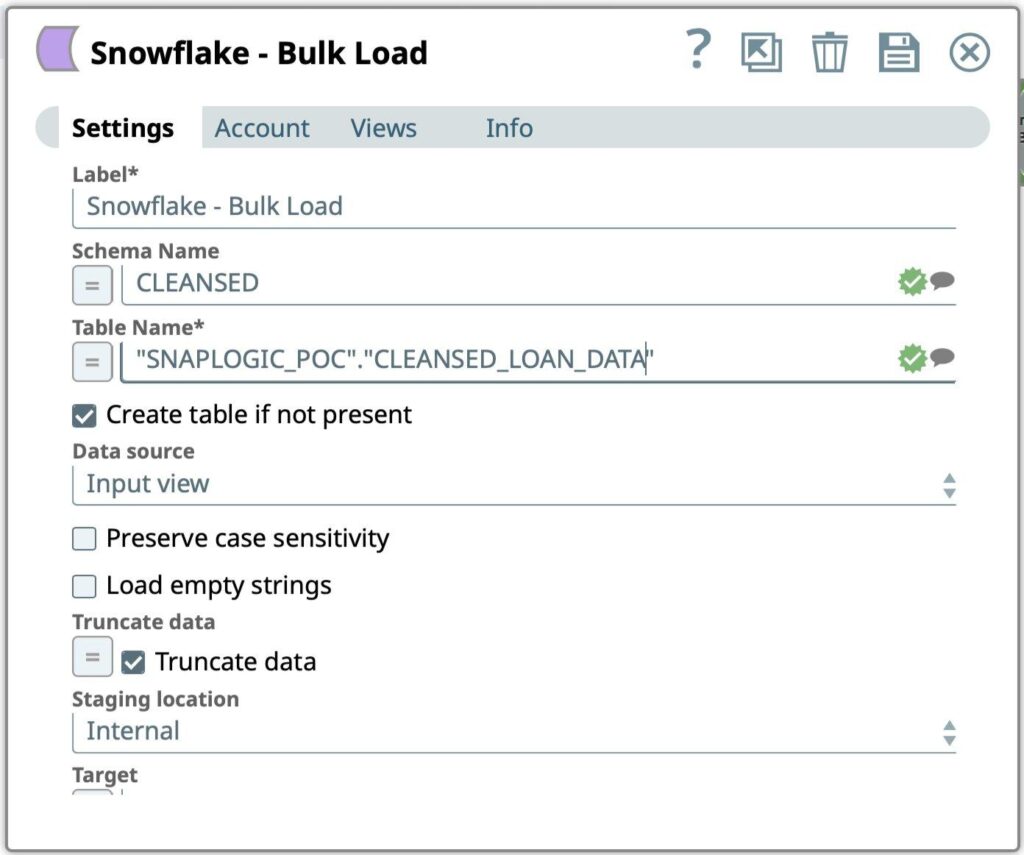
Figura 10: Impostazioni di Snowflake Bulk Load Snap - Inserire la query SQL da eseguire per recuperare i dati del lavoro formattati dal conto Snowflake:
- Nome dello schema
- Nome della tabella
- Premere l'icona Salva
Di seguito è riportata la schermata della pipeline di preparazione dei dati end-to-end creata in SnapLogic.
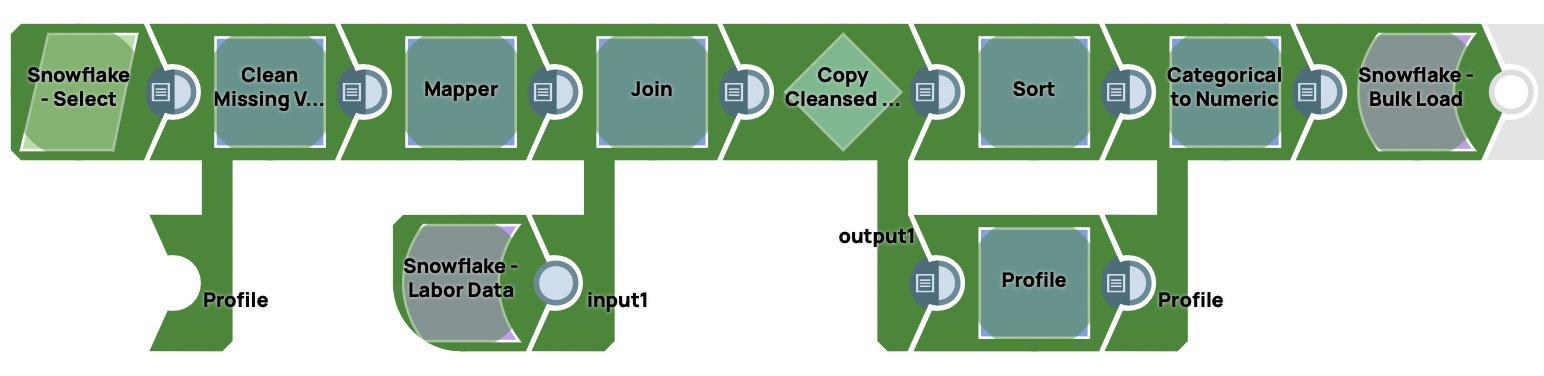
Quando la pipeline viene eseguita, carica i dati in Snowflake. Può essere attivata o programmata.
Conclusione
In questo post abbiamo trattato l'impostazione di Snowflake come fonte di dati per SnapLogic per costruire una pipeline di modelli per la previsione dei prestiti, compresa la configurazione dell'endpoint di Snowflake in SnapLogic, la costruzione di una pipeline con snap di apprendimento automatico, il recupero dei dati da Snowflake Marketplace e infine il caricamento dei dati preparati in Snowflake. Spero che abbiate seguito questa guida e che abbiate costruito un modello di apprendimento automatico per le vostre specifiche esigenze aziendali utilizzando questo processo facile da usare in SnapLogic.







