





YARN è il prerequisito per l'Enterprise Hadoop. Fornisce la gestione delle risorse tra i cluster Hadoop ed estende la potenza di Hadoop alle nuove tecnologie, in modo che possano trarre vantaggio da uno storage e da un'elaborazione su scala lineare e a costi contenuti, di storage ed elaborazione su scala lineare e a costi contenuti. Fornisce agli ISV e agli sviluppatori un framework coerente per la scrittura di applicazioni di accesso ai dati che funzionano in Hadoop.
I clienti che costruiscono un data lake si aspettano di poter operare sui dati senza spostarli in altri sistemi, sfruttando le risorse di elaborazione del data lake. Le applicazioni che utilizzano YARN mantengono questa promessa, riducendo i costi operativi e migliorando la qualità e il time-to-insight.
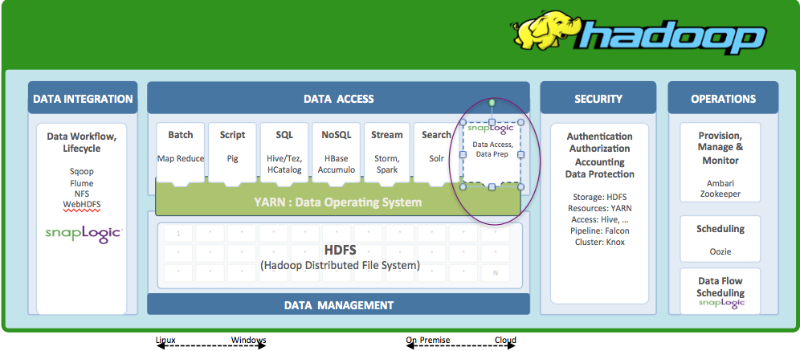
Integrazione con YARN
Per sfruttare la potenza di YARN, un'applicazione di terze parti può usare YARN in modo nativo o utilizzare un framework YARN (Apache Tez, Apache slider, ecc.) e, se non usa YARN, molto probabilmente legge direttamente da HDFS.
Esistono 3 ampie opzioni per l'integrazione in YARN.
- Controllo completo o nativo YARN: Controllo a grana fine delle risorse del cluster, che consente di scalare in modo elastico.
- Interazione attraverso un framework YARN esistente come MapReduce: Limitata a una delle opzioni batch, interattiva o in tempo reale. Nessun supporto per lo scaling elastico con YARN.
- Interazione con applicazioni già in esecuzione su un framework YARN come Hive: Limitata ad applicazioni o casi d'uso molto specifici, ad esempio con Hive. Nessun supporto per lo scaling elastico con YARN.
Ovviamente qualsiasi applicazione, che abbia il pieno controllo e sia nativa di YARN, offre un vantaggio significativo per poter fare cose molto avanzate all'interno di Hadoop utilizzando le capacità di YARN.
Questa differenza è necessaria in quanto lo spazio è diventato più interessante e confuso allo stesso tempo. I fornitori di Hadoop come Hortonworks offrono sia le certificazioni Yarn Native che Yarn Ready. Yarn Ready significa che un'applicazione può lavorare con una qualsiasi delle applicazioni abilitate a Yarn, come Hive, mentre Yarn Native significa pieno controllo e accesso a grana fine alle risorse del cluster.
SnapLogic è nativo Yarn. Ciò significa che con l'aumento dei volumi di dati o dei carichi di lavoro, la Piattaforma di integrazione elastica SnapLogic può scalare automaticamente ed elasticamente sfruttando più nodi del cluster Hadoop su richiesta e, quando i carichi di lavoro diminuiscono, scalare automaticamente. In SnapLogic questa funzione è chiamata Hadooplex. Questo post esamina esempi di Pipeline di integrazione dei big data SnapLogic.
Questo post è apparso originariamente su LinkedIn. Ravi Dharnikota è un Sr. Advisor SnapLogic, che lavora a stretto contatto con i clienti sulla loro architettura di riferimento per i big data e cloud .




