Che cos'è l'ETL?
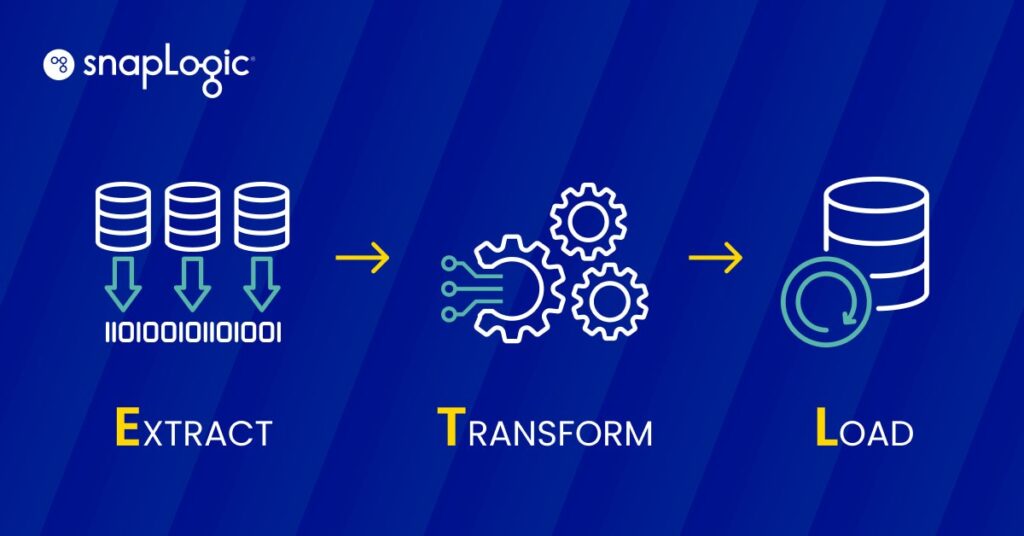
L'ETL (Extract, Transform, Load) è un processo di integrazione dei dati che prevede tre fasi fondamentali: l'estrazione dei dati da fonti diverse, la loro trasformazione per adattarli alle esigenze operative e il caricamento in un sistema di destinazione per l'analisi e il reporting. Questo processo è fondamentale per il data warehousing, in quanto consente di consolidare, gestire e utilizzare efficacemente i dati per la business intelligence.
Come funziona l'ETL?
L'ETL opera attraverso un processo in tre fasi progettato per gestire efficacemente l'estrazione, la trasformazione e il caricamento dei dati in un repository centrale.
- Estrazione: Questa prima fase prevede l'estrazione dei dati da diverse fonti, che possono essere database, fogli di calcolo o altri formati. L'obiettivo è raccogliere i dati necessari nel loro formato originale, indipendentemente dalla struttura o dal tipo di fonte.
- Trasformazione: Una volta estratti, i dati vengono sottoposti a una fase di trasformazione in cui vengono puliti e convertiti per soddisfare i requisiti del sistema di destinazione. Questa fase può comportare il filtraggio, l'ordinamento, la convalida e l'aggregazione dei dati per garantire che soddisfino gli standard di qualità e di formato per scopi analitici.
- Caricamento: La fase finale consiste nel caricare i dati trasformati in un sistema di destinazione, come un data warehouse o un database. Questa fase è fondamentale perché rende i dati accessibili per l'analisi aziendale e i processi decisionali.
Ogni fase è fondamentale per garantire che i dati siano utilizzabili, sicuri e archiviati in modo efficiente, rendendo l'ETL un processo essenziale per le iniziative di data warehousing e business intelligence.
Che cos'è una pipeline ETL?
Una pipeline ETL formalizza il processo di spostamento e trasformazione dei dati descritto in precedenza in questo articolo. Si tratta di una sequenza di operazioni implementate all'interno di uno strumento ETL per garantire che i dati vengano estratti dai sistemi di origine, trasformati correttamente e caricati in un data warehouse o in altri sistemi per l'analisi.
Flusso di lavoro strutturato: La pipeline ETL racchiude le tre fasi principali dell'ETL - estrazione, trasformazione e caricamento - in un flusso di lavoro strutturato. Questo approccio strutturato aiuta a gestire il flusso di dati e garantisce che ogni fase sia completata prima dell'inizio della successiva.
Automazione: Le pipeline ETL automatizzano le attività ripetitive e di routine della gestione dei dati. Questa automazione supporta l'acquisizione continua dei dati, la loro trasformazione in base alle regole e ai requisiti aziendali e il successivo caricamento dei dati elaborati nei sistemi analitici o operativi per la business intelligence, il reporting e il processo decisionale.
Integrazione e pianificazione: In una pipeline ETL, le attività sono tipicamente pianificate e gestite da uno strumento di orchestrazione, che coordina l'esecuzione di diversi lavori in base alla disponibilità dei dati, alle dipendenze e al completamento positivo delle attività precedenti. Questa pianificazione è fondamentale per mantenere la freschezza e la rilevanza dei dati, soprattutto in ambienti aziendali dinamici in cui le esigenze di dati sono in continua evoluzione.
Monitoraggio e manutenzione: Una pipeline ETL efficace comprende anche funzionalità di monitoraggio per tracciare i flussi di dati, gestire gli errori e garantire la qualità dei dati. La manutenzione comporta l'aggiornamento delle trasformazioni e dei processi in risposta alle modifiche dei sistemi di origine o dei requisiti aziendali.
Qual è la differenza tra ETL e ELT?
La differenza tra ETL (Extract, Transform, Load) ed ELT (Extract, Load, Transform) risiede principalmente nell'ordine e nella posizione in cui avviene la trasformazione dei dati, che ha un impatto sui flussi di lavoro di elaborazione dei dati, in particolare nella gestione di grandi volumi di dati provenienti da varie fonti.
Processo ETL: Nel processo ETL tradizionale, i dati vengono prima estratti dai sistemi di origine, che possono includere database relazionali, file piatti, API e altro. I dati estratti vengono poi trasformati in un'area di staging, dove avvengono la pulizia dei dati, la deduplicazione e altri processi di trasformazione per garantire la qualità e la coerenza dei dati. Il processo di trasformazione può comportare complesse query SQL, la gestione di diversi tipi di dati e attività di data engineering come la mappatura dello schema e la gestione dei metadati. Solo dopo queste trasformazioni i dati vengono caricati nel database o nel data warehouse di destinazione, come Snowflake o Microsoft SQL Server, per essere utilizzati per l'analisi dei dati, la business intelligence e la visualizzazione.
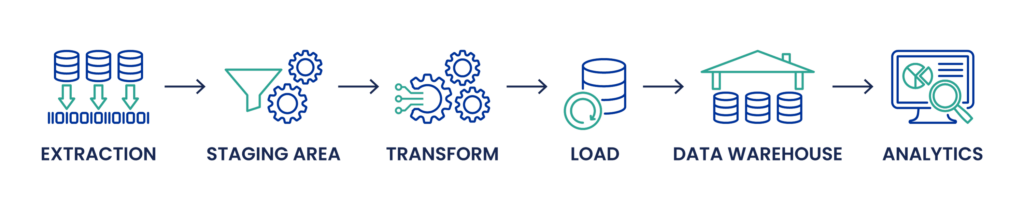
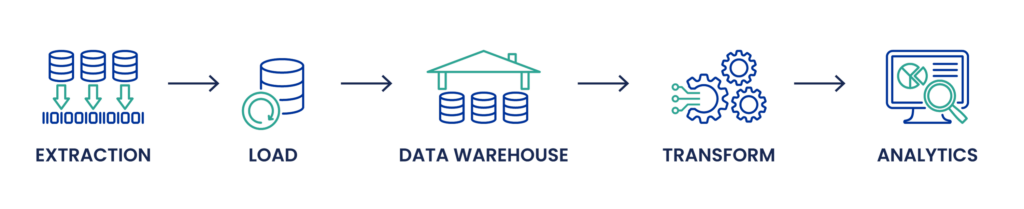
Processo ELT: L'ELT, invece, inverte le ultime due fasi dell'ETL. I dati vengono prima estratti e caricati in un data lake o in un moderno data store come Google BigQuery o Amazon Redshift, spesso nella loro forma grezza. Questo approccio è particolarmente vantaggioso quando si tratta di enormi quantità di dati, compresi quelli non strutturati provenienti da dispositivi IoT, database NoSQL o file JSON e XML. La trasformazione avviene dopo il caricamento, sfruttando i potenti motori di elaborazione dati di queste piattaforme. Questo metodo consente una maggiore flessibilità nella gestione degli schemi di dati e può gestire le esigenze di elaborazione dei dati in tempo reale, consentendo aggiustamenti più agili della pipeline di dati e facilitando le applicazioni di apprendimento automatico e intelligenza artificiale.
Differenze chiave:
- Volume e varietà dei dati: L'ELT è generalmente più adatto a scenari di big data in cui vengono ingerite grandi serie di dati da fonti diverse. Gestisce in modo efficiente i dati non strutturati e automatizza le trasformazioni dei dati all'interno del sistema di archiviazione.
- Prestazioni e scalabilità: L'ELT è in grado di offrire prestazioni migliori per grandi volumi di dati ed è altamente scalabile grazie alle potenti capacità di elaborazione dei moderni data store basati su cloud.
- Flessibilità: L'ELT offre una maggiore flessibilità nell'interrogazione e nella gestione dei dati, in quanto le trasformazioni vengono applicate in base alle necessità all'interno del data lake o del warehouse.
In sintesi, la scelta tra ETL e ELT dipende dalle specifiche esigenze di gestione dei dati, dalla natura delle fonti di dati, dai casi d'uso previsti per i dati e dall'infrastruttura dati esistente. L'ELT sta guadagnando popolarità negli ambienti che privilegiano la flessibilità, la scalabilità e l'elaborazione dei dati in tempo reale, mentre l'ETL rimane importante per gli scenari che richiedono un'intensa pulizia e trasformazione dei dati prima che questi possano essere archiviati o analizzati.
eBook gratuito: ETL vs. ELT: qual è la soluzione giusta per la vostra organizzazione?
Che cos'è l'ETL tradizionale rispetto all'ETL Cloud ?
L'ETL tradizionale e l'ETL Cloud rappresentano due metodologie di gestione dei processi di estrazione, trasformazione e caricamento dei dati, ciascuna adatta a diversi ambienti tecnologici ed esigenze aziendali.
ETL tradizionale: i processi ETL tradizionali sono progettati per operare all'interno di un'infrastruttura on-premises. Si tratta di server fisici e di storage di cui l'azienda è proprietaria e che gestisce. Gli strumenti ETL in questo ambiente fanno tipicamente parte di una rete chiusa e sicura. Le caratteristiche principali includono:
- Controllo e sicurezza: Poiché l'infrastruttura è on-premise, le aziende hanno il controllo completo dei loro sistemi e dei loro dati, il che può essere fondamentale per i settori con requisiti rigorosi di sicurezza e conformità dei dati.
- Investimento iniziale: L'ETL tradizionale richiede un significativo investimento iniziale in hardware e infrastrutture.
- Manutenzione: Richiede una manutenzione continua dell'hardware e del software, compresi gli aggiornamenti e la risoluzione dei problemi, che può richiedere molte risorse.
- Sfide di scalabilità: La scalabilità richiede hardware fisico aggiuntivo, che può essere lento e costoso.
Cloud ETL: Cloud ETL, invece, sfrutta gli ambienti informatici cloud , dove le risorse sono virtualmente scalabili e gestite da fornitori terzi. Questo approccio ha guadagnato popolarità grazie alla sua flessibilità, scalabilità ed efficienza economica. Le caratteristiche includono:
- Scalabilità e flessibilità: Cloud L'ETL può facilmente scalare le risorse in base alle esigenze di elaborazione, spesso in modo automatico. Questa flessibilità è preziosa per gestire carichi di lavoro variabili e l'elaborazione di grandi dati.
- Riduzione delle spese in conto capitale: Con l'ETL di cloud , le aziende evitano gli ingenti costi iniziali associati all'ETL tradizionale, pagando invece per l'uso che ne fanno, spesso in abbonamento.
- Collaborazione e accessibilità migliorate: le soluzioni di Cloud offrono una migliore accessibilità ai team distribuiti, consentendo la collaborazione in diverse località geografiche.
- Integrazione con i moderni servizi dati: Cloud Gli strumenti ETL sono progettati per integrarsi perfettamente con altri servizi di cloud , tra cui analisi avanzate, modelli di apprendimento automatico e altro ancora, fornendo una pipeline di elaborazione dei dati completa.
La scelta tra ETL tradizionale e cloud dipende da diversi fattori, tra cui la strategia aziendale per i dati, le esigenze di sicurezza, i vincoli di budget e i casi d'uso specifici. Cloud L'ETL offre un approccio moderno che si allinea alle iniziative di trasformazione digitale e supporta ambienti decisionali più dinamici e basati sui dati. L'ETL tradizionale, anche se a volte limitato dalla sua natura fisica, rimane una scelta solida per le organizzazioni che necessitano di uno stretto controllo sull'infrastruttura dei dati e sulle operazioni.