 Legacy data and application integration technologies were designed to scale up and not scale out. As we discussed on our recent webinar with iRobot, elasticity is a key characteristic of cloud computing and at SnapLogic, we believe it’s a key requirement for an enterprise integration platform as a service (iPaaS). So far in this series of posts about what to look for in a modern integration platform, we’ve covered the need for a fully-functional set of cloud-based capabilities (and a software-defined architecture) and a single platform for application, data and API integration use cases. In this post we’ll review the benefits of the iPaaS requirement for elastic scale. The opposite of elastic is “rigid” and that’s one of the main challenges faced by legacy integration technologies when it comes to dealing with today’s social, mobile, analytics, cloud and the Internet of Things (SMACT) requirements. When we announced the SnapLogic Elastic Integration Platform in 2013, we introduced the concept of Three-Way Elasticity:
Legacy data and application integration technologies were designed to scale up and not scale out. As we discussed on our recent webinar with iRobot, elasticity is a key characteristic of cloud computing and at SnapLogic, we believe it’s a key requirement for an enterprise integration platform as a service (iPaaS). So far in this series of posts about what to look for in a modern integration platform, we’ve covered the need for a fully-functional set of cloud-based capabilities (and a software-defined architecture) and a single platform for application, data and API integration use cases. In this post we’ll review the benefits of the iPaaS requirement for elastic scale. The opposite of elastic is “rigid” and that’s one of the main challenges faced by legacy integration technologies when it comes to dealing with today’s social, mobile, analytics, cloud and the Internet of Things (SMACT) requirements. When we announced the SnapLogic Elastic Integration Platform in 2013, we introduced the concept of Three-Way Elasticity:
- Scaling out on-premises to address enterprise applications that sit behind the customer firewall;
- Scaling in the cloud to integrate data from cloud/SaaS apps; and,
- Shipping functions elastically between on-premises and the cloud, thereby optimizing the speed of the integration execution by bringing compute to data rather than shipping data to compute.
In a Wired article, SnapLogic co-founder and CEO Gaurav Dhillon described the benefit of elastic integration this way:
“Enterprises will always have data that sits both on-premises and in the cloud. The trick is to integrate data across these two planes in a way that is fast, flexible, and scalable, so that a variety of data types can be processed ? big, relational, semi-structured, or unstructured ? and delivered in a variety of ways including batch, event-based or streaming, by intelligently shipping functions or data of any volume ? no matter where the data resides, in a flexibly controlled and distributed manner.”
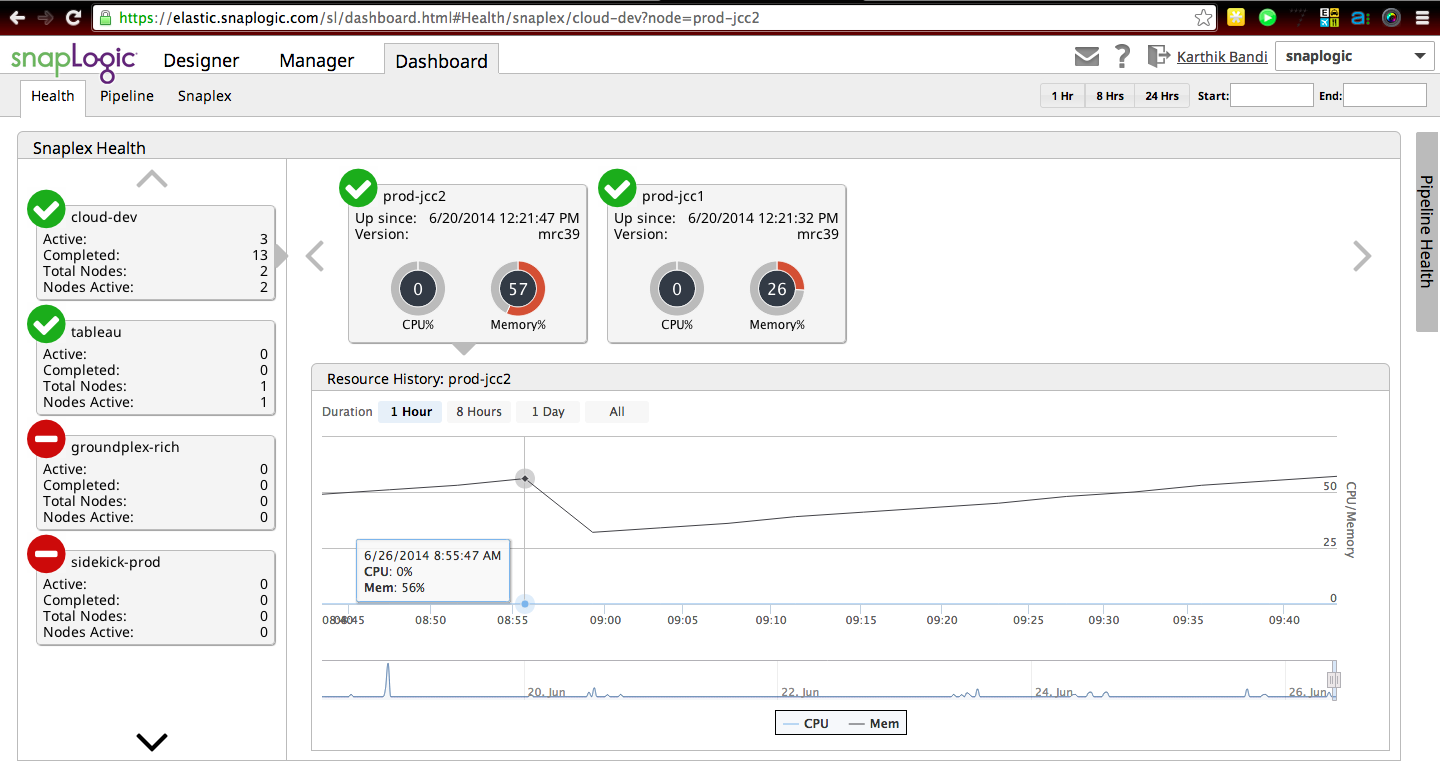
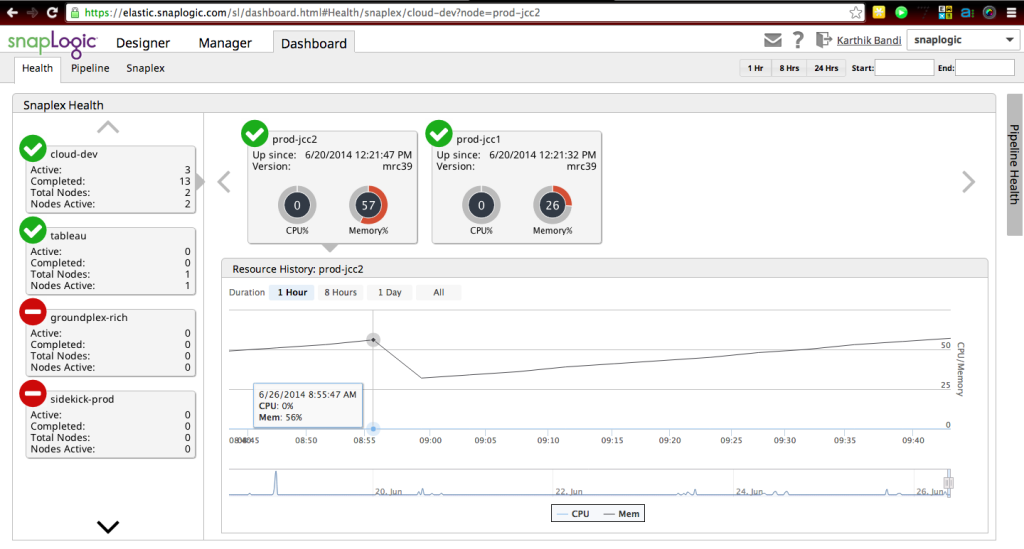
In a recent SnapReduce 2.0 TechTalk, SnapLogic Chief Scientist Greg Benson discussed how more and more of data management tasks will run on Hadoop, including migrating their existing data integrations and ETL tasks into Hadoop to run them at Hadoop scale. Here’s a screenshot of a SnapLogic dashboard monitoring the health of the cloud integration service, showing the elastic integration network, called a Snaplex, scaling out as more capacity / nodes are required. As we discussed in this post:
“Each Snaplex can elastically expand and contract based on data traffic flowing through it. The unit of scalability inside Snaplex is a JVM. The SnapLogic Integration Cloud has built-in smarts to automatically scale the Snaplex out and in to handle variable traffic loads. For instance, each Snaplex is initialized with a preconfigured number of JVMs (say one, for example). Once the utilization of that one JVM reaches a certain threshold (say 80%), a new JVM is automatically spun up to handle any additional workload. Once this excess data traffic has been processed and the second JVM is sitting idle, it gets torn down to scale back in to its original size.”
 In the next post in this iPaaS requirements series, we’ll talk about modern web standards: REST and JSON.
In the next post in this iPaaS requirements series, we’ll talk about modern web standards: REST and JSON.