






Key takeaways
- AI is everywhere, but with a high risk of failure
- Easy access to data is key to success with AI
- Data integration must be aligned to business goals
Setting the stage
The SnapLogic team was out in force for the Gartner Data & Analytics Summit in London. This is one of the best events of the year for high-value conversations, where the attendees tend to be people with specific goals and problems, as well as the willingness and resources to address them.
We saw this need for concrete solutions right from the opening keynote, when Adam Ronthal and Alys Woodward shared their finding that data & analytics maturity positively impacts financial performance by 30%. Governance and management, however, still tend to be undervalued relative to more technical metrics.
Successful companies, though, are overhauling their approach to data storytelling and to D&A metrics, in order to be more business oriented. This increased engagement with the business would be a recurring topic over the three days of the conference — and is of course something that we at SnapLogic have long advocated, with our low-code/no-code approach to integration.
Another topic that (unsurprisingly) was everywhere during the conference was AI — and again, the recommendation was to evaluate projects both for feasibility and for business value. Technical experimentation around the feasibility of AI is well underway in our industry.
Gartner reports that 75% of CEOs have already tried GenAI according to the “2023 CEO Survey Research Collection and Midyear Update AI Findings” — but 53% believe they would not be able to handle the risks of AI. High-profile examples of failure included Microsoft’s Tay and Air Canada’s travel-advice chatbot.

The conclusion is that the lack of AI-ready data is a top challenge to the success of GenAI implementations. This is of course the exact problem that SnapLogic addresses, with a powerful and omnivorous data integration platform to ensure the data is available, and the GenAI Builder toolkit to make it easily accessible to end users.
Data fabric
This technological underpinning falls under the umbrella of “data fabric,” which was discussed in an interesting presentation by Michele Launi. He made it clear that data fabric is not a single tool or product that can be procured and deployed in one step — but data integration is a key component, and that is where SnapLogic can help. Our low-code/no-code development model also addresses one of the key challenges to the adoption of data fabric, namely a lack of specialised talent.
Making data available as part of a data fabric approach means ensuring that the platform can support a variety of data styles, from traditional ETL to reverse ETL and ELT, as well as streaming, across structured and unstructured data types. All of these and more came up in conversations with attendees at the SnapLogic booth and throughout the show.
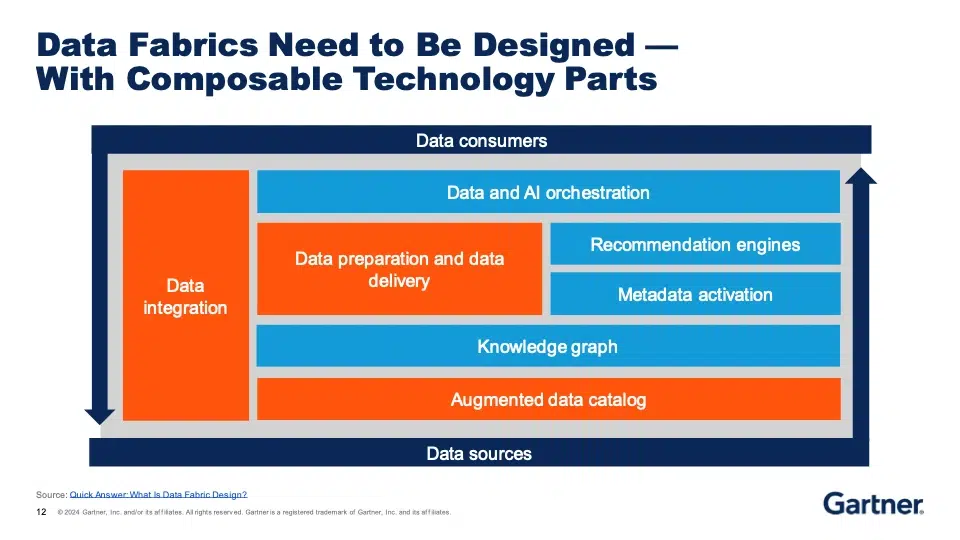
Michele also mentioned that many IT leaders in particular expect that automation will reduce the effort involved in sharing data. The savings here are real and borne out by the experience of SnapLogic customers around the world, but we also agree with Michele that real value comes when that data is placed in context — meaning the context of the business.
This self-service approach does require some attention to operationalization and governance — something that my Enterprise Architect team at SnapLogic is focused on helping our customers to implement through our Sigma Framework for Operational Excellence.
The topic of organisational maturity came up again later in the show during a conversation between Mark Beyer and Robert Thanaraj about the sometimes confusing overlaps between the related concepts of “data fabric” and “data mesh.” In particular, they shared their finding that organisations spend up to 94% of their time preparing data, and therefore only between 6% and 17% of their time actually making use of the laboriously gathered data for their business purposes.
To minimise this friction, they recommend adopting a more iterative approach to planning, enabling greater flexibility in the face of inevitable change. This flexibility means that ownership and governance must rest with the business, as IT is too far downstream; technical specialists deliver the enabling platform, but business owners are responsible for the actual result.
Gartner estimates that few organizations have the maturity to make these cultural shifts — but SnapLogic’s model enables the rapid iteration which is key to success, and puts it in the hands of domain experts directly, reducing the need for IT specialists and bringing the benefits of this approach to organisations lower down Gartner’s maturity curve.
AI — but how? And why?
I have managed not to talk about AI too much yet, but as mentioned, the topic was omnipresent during the conference, and explicitly described as the goal for much of the data-gathering and integration activity. However, the big problem is that less than half of Al projects ever go into production — and that ratio is even worse for Generative AI, where according to Gartner, fewer than 10% make it all the way.
This is why Sumit Agarwal stated bluntly that Generative AI will descend from its current Peak of Inflated Expectations into the Trough of Disillusionment.
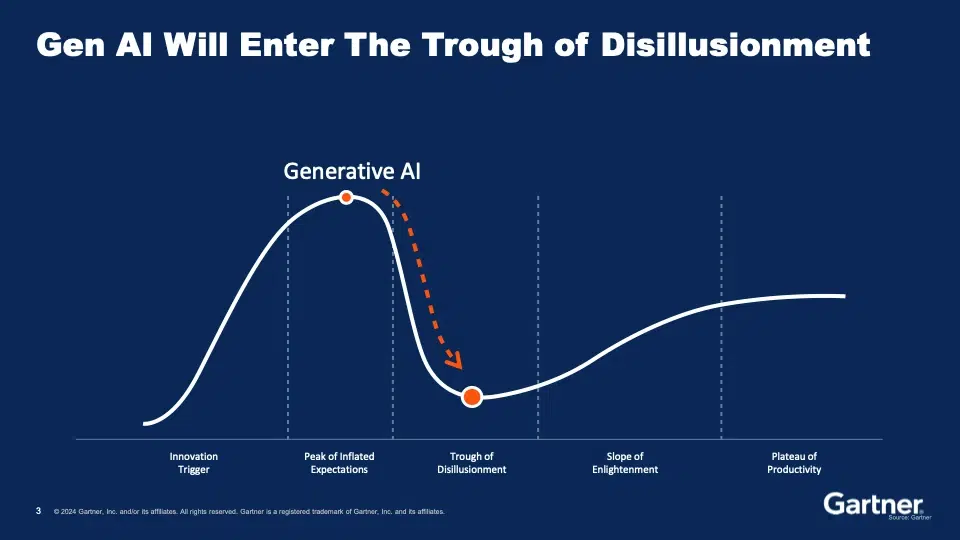
I agree with Sumit that the only way out of the Trough is to demonstrate value from AI projects and to do so at scale. This is why SnapLogic offers the GenAI Builder toolkit. By minimising the distance between the data and the business need, SnapLogic’s GenAI Builder enables users to rapidly prototype and deploy services that take advantage of the power of GenAI, using the organisation’s own valuable data, and to do so securely and at scale.
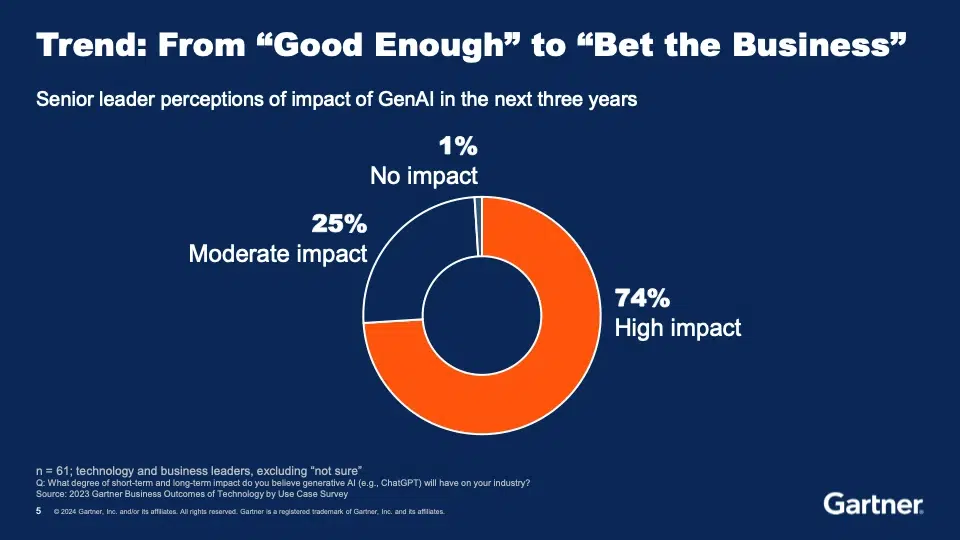
The value of this approach was reinforced by Gareth Herschel in the closing keynote of the second day: “Al is built on the bedrock of the data architecture that is already in place.” The solidity of the foundations is especially important because AI is a “bet the business” moment, where success or failure will have enormous implications for the future.
SnapLogic and Syngenta
So much for the general themes — but analyst projections and quadrants only carry so much weight. The true proof is in the real, practical customer stories. This was why I was very happy to have the opportunity to interview Maks Shah, Head of R&D Data Platforms at Syngenta, on stage in a thousand-person auditorium.
Business goals don’t get much more concrete than Syngenta’s: nothing less than safely feed the world and take care of our planet. However, they had a challenge in digital science: long times to insight, an unsustainable operating model and data quality issues. The external constraints on Syngenta Research and Development are significant. If something goes wrong with a field trial or the results are inconclusive, you have to wait a year before the next growing season and pests for that crop come around again so you can rerun the experiment.
Thanks to SnapLogic, Syngenta data scientists are starting to have faster access to 300+ internal data sources, as well as 100+ external ones. They are ingesting both structured and semi-structured data, in batch and streaming modes, depending on the precise requirements of each source. This seamless integration is already bearing fruit, with projects including:
- Legacy to modern application integration to simplify the data integration landscape
- Decoupling the existing event-driven architecture and transitioning to a more flexible and future-proof microservices architecture
- API Management to enable self-service integration
We look forward to working further with Syngenta, with our other customers in life sciences and many other industries, and with all of the new friends that we made at Gartner D&A. If you visited our booth at the show, thanks, and we’ll be in touch soon. And if you missed it, but are interested in finding out more about what you just read, we’d be happy to have a conversation about how SnapLogic can help you dismantle data silos and bring connectivity to the enterprise.






