






Snaplogic is a visionary integration platform that serves enterprises of all sizes. With a growing number of monthly executions, SnapLogic remains committed to introducing innovative solutions that help customers manage and perform at scale. As our customers increase their reliance on SnapLogic systems, they demand improved data governance.
In response, we are investing in a data lineage solution based on the popular open standard, OpenLineage. OpenLineage will bring transparency to the transactions automated by SnapLogic’s no-code pipelines, enabling enterprises to understand connections within their datasets.
Why is data lineage important?
Enterprises typically have a considerable understanding of their data assets. However, when it comes to pipelines created in SnapLogic, sometimes, there is limited visibility into the data flow. SnapLogic’s innovative streaming architecture empowers users to extensively parameterize their pipelines, allowing for a high degree of customization and flexibility in data integration processes. By abstracting away the complexities of underlying infrastructure and execution, SnapLogic greatly simplifies user workflows. On the flip side, it can make data flows somewhat opaque.
Often, these pipelines dynamically route data based on the data being processed. Consequently, users lack real-time visibility into the dependencies, transformations (e.g., joins, filters, aggregations), and other processes occurring within their complex data landscape.
For example, if a report relies on the output of multiple data pipelines, assessing its accuracy or freshness can be challenging without clear information on data sources, origins, and transformation history. Data lineage helps bridge these gaps and provides greater clarity and understanding of the data flow.
The transparency it offers in SnapLogic’s data processes can assist with:
- Impact analysis: Identifying downstream dependencies of a data source down to the column level
- Root cause analysis: Pinpointing the origin of an issue by tracing the data flow and transformations along the way
- Data quality and integrity: Ensuring data accuracy and consistency across systems
- Data migration/integration: Mapping data paths to simplify migrations and data integrations across environments with minimal disruption
- Data lifecycle management: Tracking column-level data from creation to disposal, supporting efficient retention and archiving
- Governance and compliance: Establishing a column-level audit trail for data assets
Data lineage is invaluable in any organization handling large volumes of data, but it is especially crucial in industries with specific legal requirements. Two key regulations that have heightened interest in data lineage solutions are the Basel Committee on Banking Supervision’s BCBS 239 and the EU’s General Data Protection Regulation (GDPR).
BCBS 239 mandates that banks provide transparency into the data flow feeding their risk reporting, requiring robust data governance and detailed data lineage. GDPR requires companies to disclose consumer data management practices (the “Right to Know”) and to honor user requests for data deletion (the “Right to be Forgotten”). Consequently, for regulatory compliance, organizations must track data sources in reports.
Why OpenLineage?
OpenLineage is a community project maintained by contributors from popular open-source projects such as Amundsen, DataHub, Pandas, and Spark. Following similar efforts such as OpenTelemetry and OpenTracing, OpenLineage has garnered popularity and active adoption by numerous vendors across the industry.
As Julien Le Dem, one of the co-founders of OpenLineage, emphasizes: “Data lineage is the backbone of DataOps. Lineage can help reduce fragmentation and duplication of efforts across industry players, and enable the development of various tools and solutions in terms of data operations, governance, and compliance.”
In collaborating with industry vendors, SnapLogic encountered numerous formats, each requiring unique adapters for communication. This is precisely the challenge OpenLineage addresses, with a standardized format already widely adopted and growing in usage across vendors.
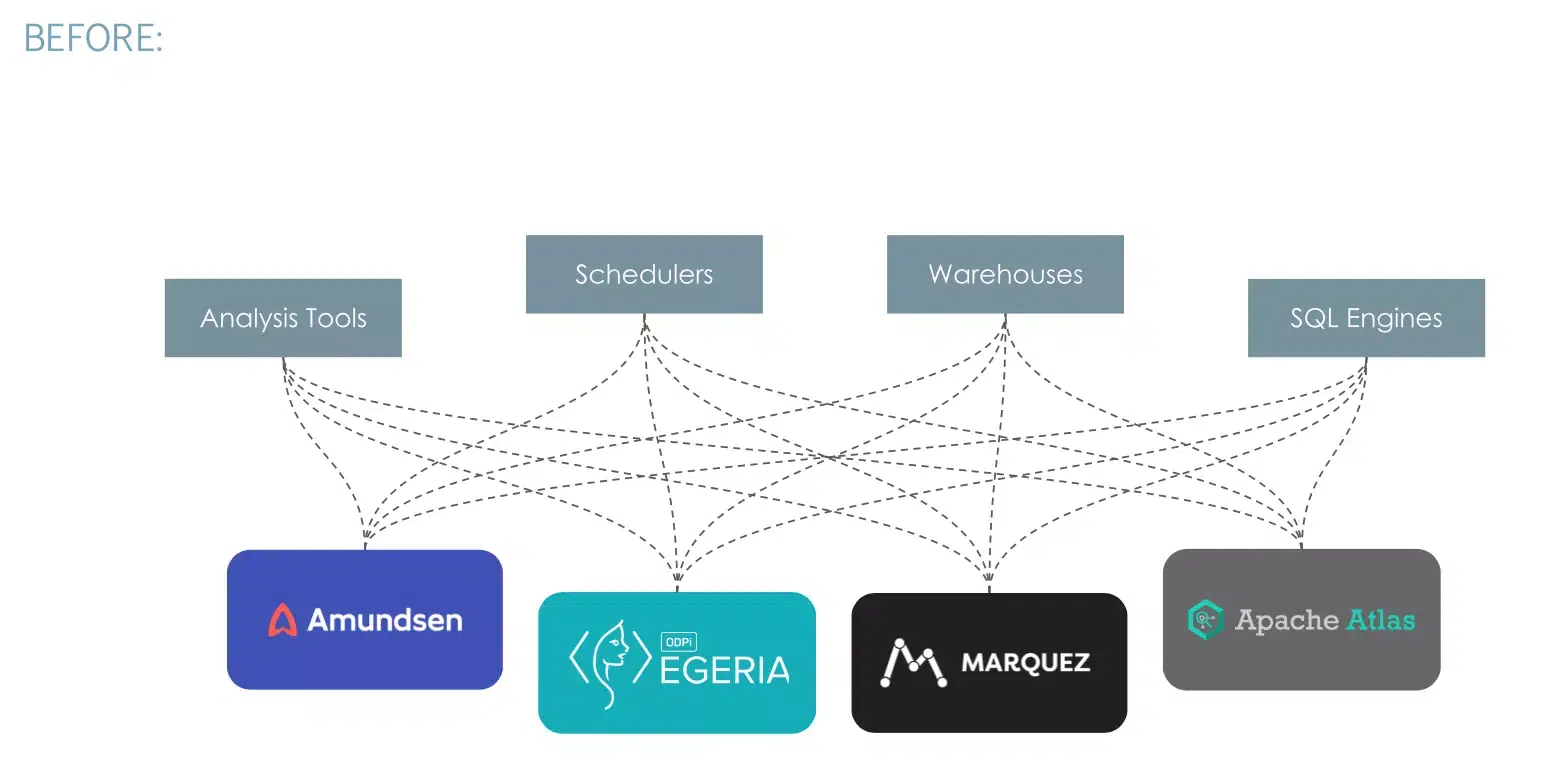
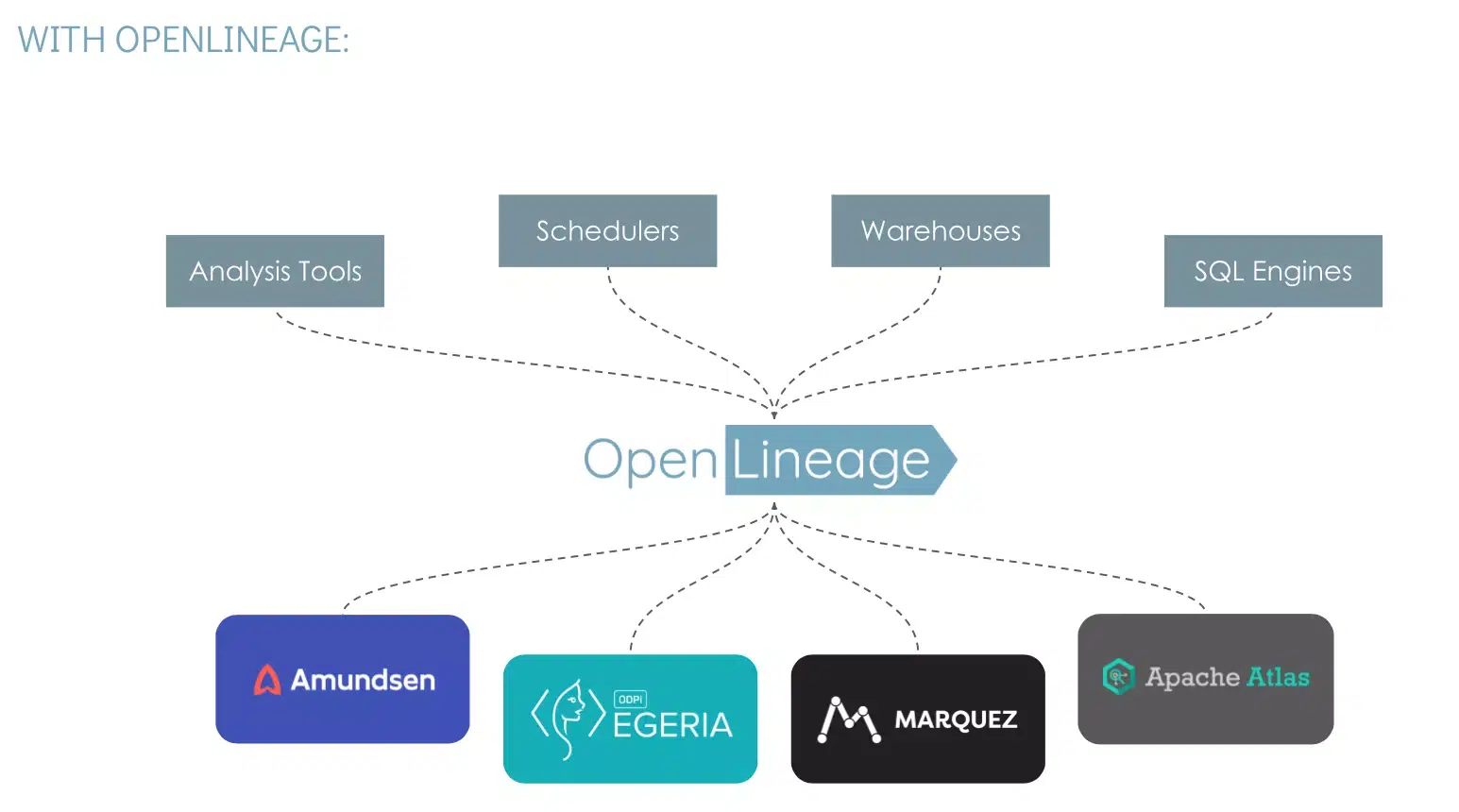
In today’s intricate data ecosystems, comprehending data lineage is paramount. Organizations seeking to enhance data governance, ensure data quality and compliance, or optimize operational efficiency and impact analysis require a standardized method to track data’s journey and transformations across their systems. Snaplogic’s adoption of OpenLineage delivers a consistent column-level perspective on data movement across the organization, fostering transparency and integration while maintaining vendor neutrality.
Want to get started? Data lineage is available as a subscription feature in SnapLabs. Contact your CSM to try it out.








