






The introduction of the Pipeline Execute Snap has brought many benefits to my customers’ integrations (I’m a technical consultant), reducing the number of overall pipelines needed to serve their departmental integrations, improving the regression testing overhead, and improving the time-to-value.
The following tries to explain some of the Pipeline Execute Snap options my customers have used to affect performance.
The Pipeline Execute Snap gives you the ability to create what is essentially a child integration which can be reused in different places. Creating modularized integrations which can be used by different departments has standardized company integrations and reduced unnecessary rework. And most importantly, it has created less work for the integration leads.
The Pipeline Execute settings dialogue is as follows:
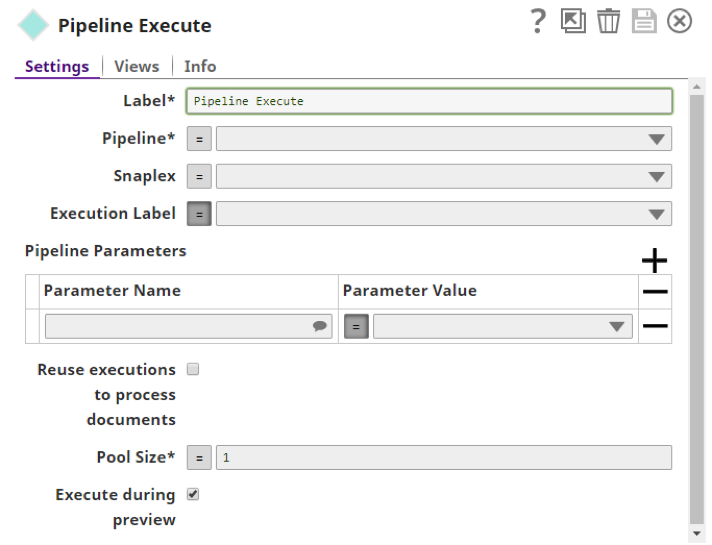
I’ll go through a brief description of the options that can make a difference to the performance. For a complete overview, refer to the help documentation here.
Snaplex:
Selecting a Snaplex means you are choosing to run the child pipeline on a particular Snaplex. Selecting this option means you are subject to an initial performance hit when moving the integration to be load balanced across all the nodes of that particular Snaplex. Leaving this option blank means you are opting to run the instance(s) of the child pipeline on the same JCC node as the parent integration.
Reuse Executions:
When enabled, the Snap will start a child execution and pass multiple input documents to the execution. Reusable executions will continue to live until all of the input documents to this Snap have been fully processed.
So, in essence, use this option whenever you can. You cannot use this option if you have different pipeline parameters for each execution, but I have found that passing those parameters as data into the child can allow reuse to take place.
If the reuse pipeline option is not enabled, then a new pipeline execution is created for each input document, this will obviously have a performance implication.
Pool Size:
Multiple input documents can be processed concurrently by specifying an execution pool size. When the pool size is greater than one, the Snap will start executions as needed up to the given pool size.
When reuse is enabled as well, the Snap will start a new execution only if all executions are busy working on documents and the total number of executions is below the pool size.
In summary
To maximize performance:
- Adjust your input JSON documents to encapsulate pipeline parameters, so you don’t need to pass any as pipeline parameters
- Always use the reuse option
- Increase the Pool Size (13 has always been a great number for me)
And most importantly, give feedback on any results to the SnapLogic team, so they can recommend better options in the future (they need feedback from the field). Also, provide feedback on the SnapLogic community site, as other SnapLogic users and I would love to know any options which can improve our times.
Happy reusing!
Elesh Mistry is a technical consultant with experience in the defense, telecoms, and finance industries. He also previously worked at SnapLogic as a Solutions Consultant in the EMEA region. You can follow him on LinkedIn and subscribe to his YouTube channel, where he has posted a number of integration videos. The views, opinions, and positions expressed within these featured contributor guest post are those of the author alone and do not necessarily represent those of SnapLogic.







