






Looking across the landscape of what passes today as the definition of a modern data stack, we at SnapLogic ask the question, are current definitions modern enough?
This is an important question to ask because, when dreaming up a data architecture, companies want to be forward-looking and think ahead to their data needs of the future and not just for their data needs of today.
Therefore, if not modern enough, companies run the risk of deploying a solution that may come up short for their data needs across the entire enterprise, stall as time goes by (i.e., not future proofed), increase complexity with more tools to compensate, increase costs, and slow down time-to-value from data products.
What Makes a Data Architecture Modern?
The following is a quick summary of what is typically found when researching the definition of a modern data stack or modern data architecture. Modern data architectures are:
- Cloud-native – hosted in cloud for fast deployment and easy scalability
- Easily accessible – for a broad set of users, beyond IT or engineering, to access data
- Data integration focused – all integrated data is directed to a cloud data warehouse, cloud data platform, or data lake destination
- Centralized deployment oriented – with the dominant use cases referenced being related to analytics and business intelligence
While this is a solid list, with a representative architecture block diagram shown in Figure 1, it has its limitations and risks. Read on.
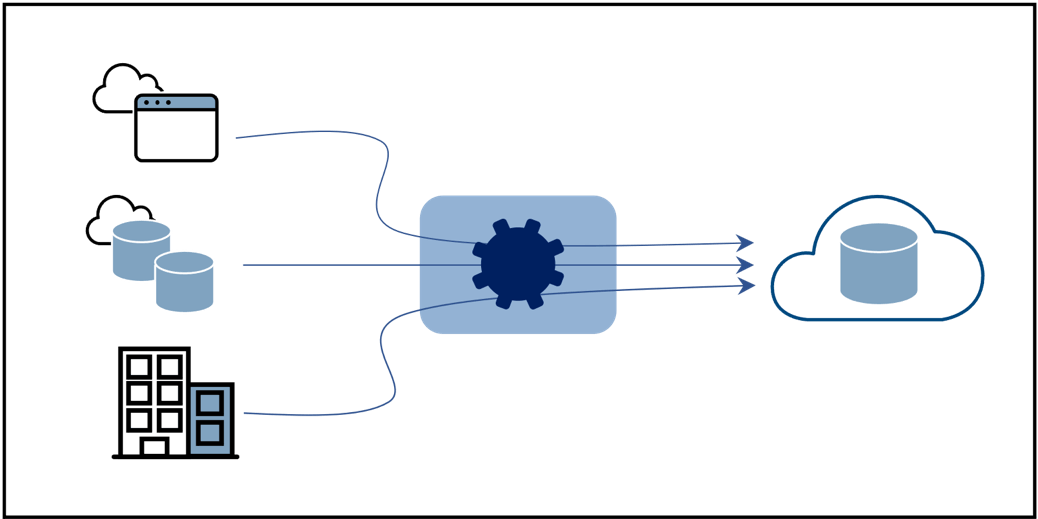
Data Integration by Itself is not Modern Enough – Combine App-to-App Integration
Pushing data to a cloud data warehouse (CDW) or cloud data platform, like BigQuery, Redshift, Snowflake, et al., or to a data lake certainly increases agility, nimbleness, and the ability to scale quickly for data analytics workloads. The challenge is while data analytics is a dominant workload, it is not the only workload. Not all use cases are centralized, especially considering data mesh/data fabric continues to be a hot topic of discussion amongst enterprise architects.
Additionally, analytics workloads, by their very nature, are post production and not operational. Operational data systems involve applications that act on or share record-level data (as opposed to analyzing data sets) closer to real time. Columnar data integration is good for analytics, but not as good for real time operational, app-to-app, data sharing. Row-based integration, bypassing the CDW, tends to be faster.
Consider this sentiment from Carrie Craig, director of enterprise business applications at the WD-40 Company, “we push our CRM data directly to our ERP system via SnapLogic application-to-application integration because it’s faster and simpler for our business data scientists to access the data they need. For us, it is a competitive advantage to have just in time data for decision making purposes.”
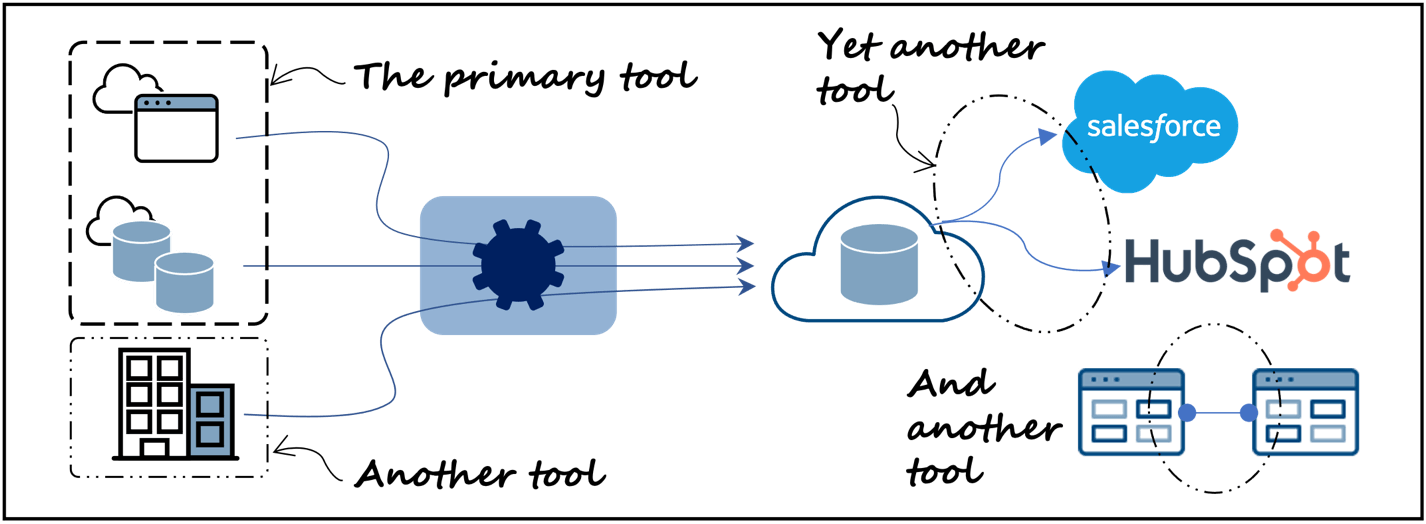
To achieve this, you’d have to add another app-to-app type of integration tool (Figure 2, lower right) to your stack if you’re using data integration tools like Fivetran, Matillion, Informatica, or similar. This will result in increased complexity and potentially more costs.
Modern Data Products with Bidirectional Syncs – Uncomplicated
In the same vein, if you’re an organization that produces data products, or an analytics group that enriches data, once you’ve done your thing from within the data warehouse or data lake, you may want to feed the data product or enriched data back into an operational system or application. Take for example a use case that calculates the risk of a customer churning. Customer data is pulled from a CRM system, like Hubspot or Salesforce, and then loaded into the data warehouse to perform the churn analytics or other enrichment. It’s cool to then have the customer churn risk data returned back to the CRM system to provide a consistent access and viewing experience for executives and sales reps that want the additional insights on customers. This a superior, and more business-user friendly, experience compared to accessing the CRM system for one set of needs and then having to make a separate request to IT or the data analytics team for access to the customer churn risk information.
Completing such a task for this use case will require unloading data from the data warehouse and then loading the data back into the CRM system, that is, a bidirectional sync or reverse-ETL (extract, transform, load) job in other words. The modern data architecture as shown in Figure 1 would require yet another tool, such as Hightouch, Census, or Hevo, to perform this (Figure 2, upper right). This means, same as before, add a tool, increase complexity.
To be fair, some data-integration-only tools have evolved to accommodate bidirectional/reverse-ETL use cases. However, you’ll have to look under the hood to understand to what degree bidirectional syncing is supported.
Handle Both On-Premises and Cloud Resident Data Without Extra Tooling
It’s one thing to say a modern data stack or architecture is cloud-hosted, but it doesn’t (or in our view, shouldn’t) mean data that is operated on must be in the cloud. Modern financial companies, insurance companies, and government agencies, for example, have a variety of needs and may have security policies requiring sensitive data to stay on premises. Sending sensitive data to the cloud for manipulation and then returning to an on-premises repository creates a security risk.
If a cloud-hosted data integration tool or data platform has difficulty reaching into on-premises environments, operating behind a firewall, and executing data operations that need to stay on-premises another tool will be required (Figure 2, lower left). This again adds complexity and may change the operating experience.
A better solution is to separate cloud control from on-premises execution within the same integration tool.
Become More Modern, Execute Faster With Less Technical Debt and Complexity
In this blog, I revealed three areas where a data integration-oriented modern stack falls short and requires extra tooling, which leads to more technical debt and added complexity.
Often when a modern data stack or architecture is discussed, it’s from a data integration perspective. This is inherently limiting considering the reach a modern data stack or architecture must have to accommodate the broader needs of modern companies across their enterprises.
To make your modern architecture more modern, combine app-to-app integration, bidirectional data syncing/reverse ETL, and on-premises data execution capabilities within the same integration platform, rather than as individual tools in your data architecture. The benefits are reduced technical debt, reduced complexity, i.e., simplicity, and accelerated time-to-value from integrations.
Consider comments from Geoff Shakespeare, chief operating officer at National Broadband Ireland (NBI), a company with an ambitious initiative to connect broadband to large portions of rural Ireland: “After looking at a range of integration solutions, we organised an eligibility test asking vendors to build a functionality in front of us in one morning which could look up a postcode and return a negative or positive value on whether we could deploy broadband to that postcode. SnapLogic impressively completed the task in two and a half hours. Time to market is of paramount importance for this project and SnapLogic has helped us deliver on key objectives.”
Part two of this blog series is now out! We cover two additional areas of importance to make your modern data more modern.






