






With the first article of this two-part series, I highlighted three of five capabilities to make your modern data architecture more modern. But not just more modern, less complex as well.
Recapping the three capabilities (as summarized in part 1) to look for:
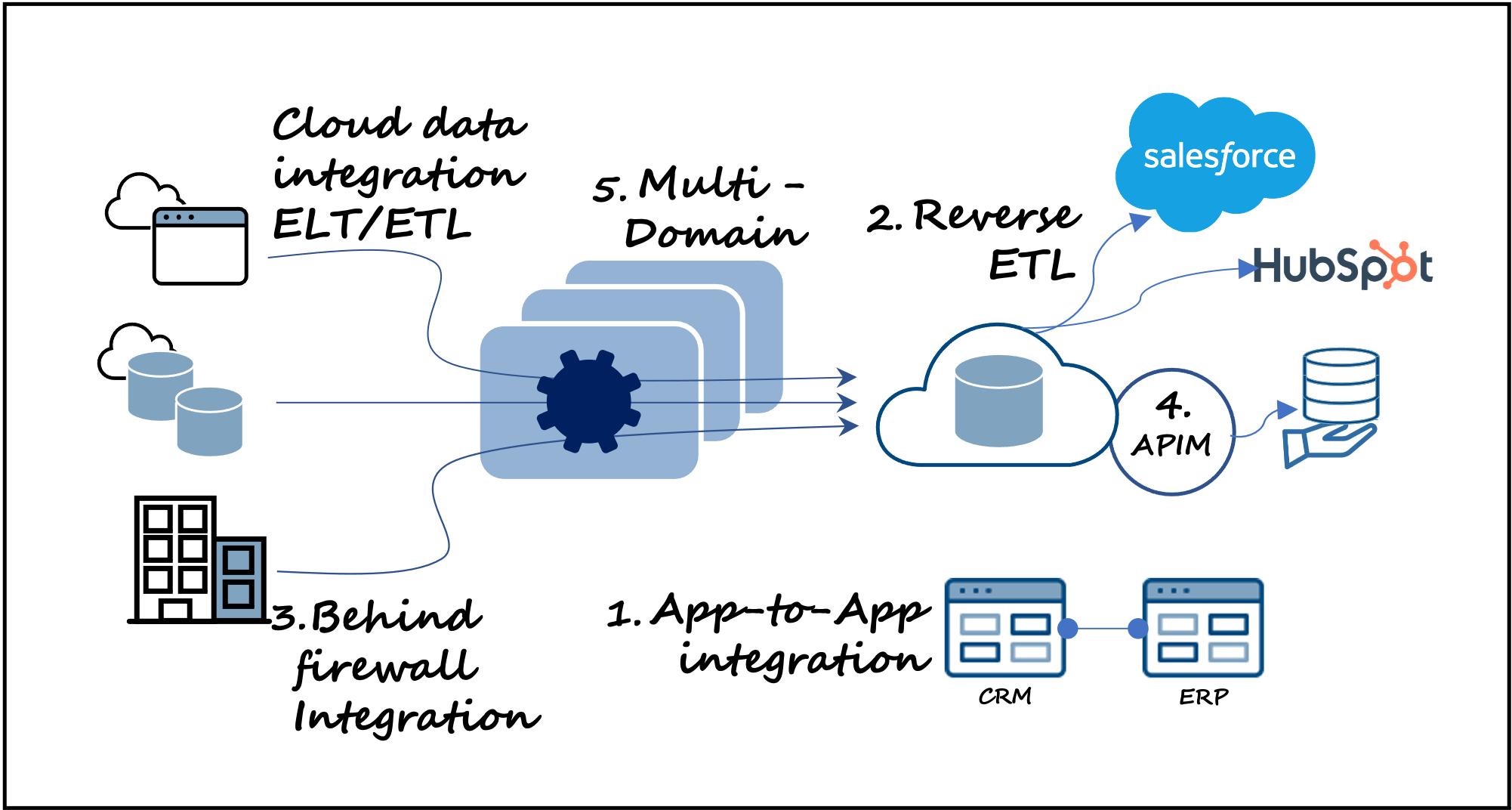
1. Data Integrations and App-to-App Integrations Combined
Pushing cloud data (ELT or ETL) to a cloud data warehouse such as BigQuery, Redshift, Snowflake, or other (with tools such as Fivetran, Matillion, Informatica, etc.) is great for post-production analytics and insights and is a dominant use case. However, data integration by itself is potentially limiting. A more modern capability is to have, within the same tool, the flexibility to integrate data between applications for operational workloads, especially when real-time performance is necessary. In addition, compared to accessing data via a data warehouse, in-app data experiences may be faster and simpler for a broader base of users.
2. Bidirectional Loading Patterns (ETL, ELT, and Reverse ETL) – Uncomplicated
Along with extending to app-to-app integrations, combining ETL and ELT with reverse ETL patterns, again in one solution, is a more modern approach that delivers flexibility (compared to tools like Census, Hightouch, Hevo, etc.) to select a loading pattern that is best for your specific use case. The added benefit is tool consolidation, thereby simplifying your data architecture.
3. Handle Both On-Premises and Cloud-Resident Data Without Sacrificing Security
Cloud-resident data is the ongoing trend, but for some security- or privacy-sensitive companies, on-premises data will not go anywhere near a cloud (for whatever the reason). A more modern solution separates data execution from data control, enabling your data or app-to-app integrations to run on any infrastructure, located anywhere, including behind an on-premises firewall, while you maintain nimble and agile cloud control.
Now for the remaining two, more modern capabilities:
4. Data + App-to-App Integrations + APIs for a More Modern Data Services Dev/Ops Experience
Data products and data services are all the rage these days. But considering once again (as stated in part 1) the attention data mesh and data mesh principles (domain-owned data, data as a product, self-service data architecture, and federated computational governance) has garnered, there is an intersection of many technologies, with integration and API management among them, to make data mesh happen. Then there’s delivering data services, which generally requires development, deployment, and management of APIs.
API-driven culture (with solutions like Apigee, Kong, et al.) has been a thing for some time – from an application, software development perspective. Through the lens of a data architecture point of view, however – whether data stays in place or whether pipelines are built to flow data – data products, services, and pipelines have development processes of their own. Because of this, data products, services, and pipeline development would benefit from application development, specifically continuous-integration and continuous-delivery (CI/CD), dev-ops best practices.
So, if integration, domain ownership, data products dev/ops, data services delivery, and APIs comprise an important intersection, then combining as much of these capabilities into a single platform solution – that is also self-service oriented – will yield consolidation and simplification benefits. Plus, techie and non-techie users alike will experience a more modern, integrated development experience.
“Leveraging SnapLogic to build our AI-embedded platform, we can enable our enterprise and give employees access to the data they need at their fingertips. Over 95% of all our APIs are orchestrated by SnapLogic, empowering our employees to build applications on top of our Marko data platform with ease,” Brian Murphy, VP of data at food services company, Aramark.
5. An A-to-Z Scalable Integration Architecture
Related, if you have an environment that must support more than one domain – for example, multiple branch office locations, different business units, multiple functional teams, etc., then the integration backbone that brings it all together must scale to accommodate new domains.
Technically, of course, you can deploy a new data architecture for each new domain, but that would create hard boundaries and additional complexity. Although there may be times when this is necessary, if there is a choice, a better alternative is to avoid adding complexity. Therefore, a more modern approach is to build flexibility and choice into your architecture with an integration backbone that can scale horizontally (X-axis) by adding more nodes of compute power, scale vertically (Y-axis) by increasing the size of a compute node, or scale wide (Z-axis) by adding more domains (Figure 1). All domains would be loosely coupled together within the same integration environment.
Further, each domain would have its own resources, while control and management for the entire integrated environment could be business group owned and managed, or IT owned and managed. Flexibility is the key as companies increasingly place IT-like technologists within business groups. For such a distributed environment, it would also be ideal to collect activity metadata across the entire environment to foster governance and enforce security policies. Metadata and governance are a topic on their own for a future article. Stay tuned.
More Modern + Less Complex = Simpler Life with Data
With this two-part article series, I’ve summarized how data integration (data sources consolidated to a cloud data warehouse) tends to be at the center of most modern data architecture and modern data stack discussions. Yet, when I have the privilege to engage with IT and business group technology managers, enterprise architects, and data platform managers, a common point of concern often voiced is data architectures are too complex and are too techie to empower individuals outside of IT to onboard and work with data.
A major contributing factor is the presence of multiple, overlapping tools to accomplish broader data tasks, compensating for tools that are just ELT or ETL focused, or just reverse ETL focused.
Data integration (ELT, ETL, and reverse ETL), app-to-app integration, and full lifecycle API management, when consolidated within a single integration platform, will make your overall data architecture more modern (and more functional), but less complex and simpler for a broader range of data owners and users. This includes users outside of IT. A bonus is when such a consolidated, unified solution also allows you to separate cloud control from on-premises (behind a firewall) execution, and allows you to scale vertically, horizontally, or wide to meet performance demands and to add domains.






