This week SnapLogic announced SnapReduce 2.0, which enables the SnapLogic Elastic Integration Platform as a Service (iPaaS) to run natively on Hadoop as a YARN-managed resource that elastically scales out and makes it easier to acquire, prepare and deliver big data. I sat down with Greg Benson, who is a Professor of Computer Science at the University of San Francisco and also works as SnapLogic’s Chief Scientist. Greg has worked on research in distributed systems, parallel programming, OS kernels, and programming languages for the last 20 years. His team is driving SnapLogic’s big data integration innovation. Here is what he has to say about SnapReduce 2.0, YARN and the opportunity for customers to benefit from SnapLogic’s software-defined integration platform:
What is SnapReduce?
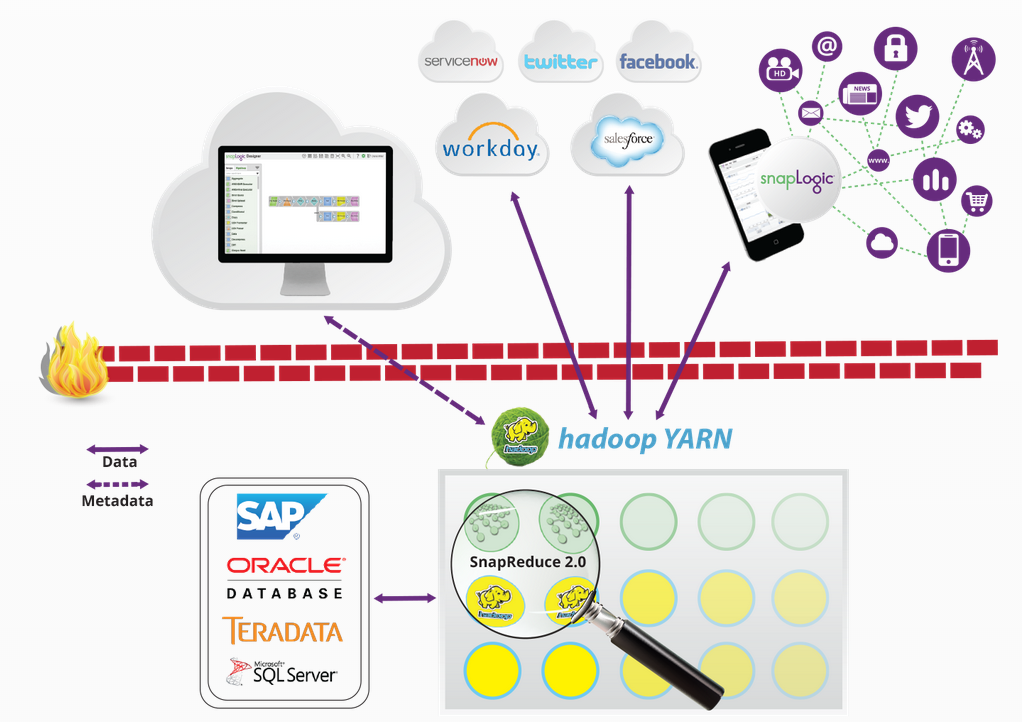
SnapReduce 1.0 harnessed Hadoop by transforming SnapLogic pipelines into Hadoop MapReduce Jobs. These transformed pipelines could work strictly on existing Hadoop data. While powerful, this technology did not open up SnapLogic?s full range of connectivity to Hadoop. Now with YARN, SnapLogic can run inside Hadoop and allow any SnapLogic pipeline to run inside a Hadoop cluster.
SnapReduce 2.0 leverages your investment in Hadoop by allowing you to multiplex your Hadoop resources for integration tasks in addition to your other Hadoop applications. Integration tasks can now scale to the capacity of your Hadoop cluster as needed. In addition, SnapReduce 2.0 makes it easier to both acquire and deliver Hadoop data using a graphical designer and Snap connectivity to a wide range of applications and data stores.
What makes SnapReduce 2.0 unique?
SnapReduce 2.0 is unique because it is both YARN compliant but also connected to the SnapLogic elastic iPaaS. You get all the resource utilization and scale benefits of Hadoop while getting the no maintenance advantage of a cloud service. In addition, fundamental to SnapLogic is native support for hierarchical documents. This native support can be used to easily create JSON data files in HDFS as well as line-oriented records as needed.
What problems does SnapReduce 2.0 solve?
We see some customers who want to begin moving their data warehouse and long-term storage into Hadoop for its cost advantage over proprietary storage products. In addition, customers are beginning to rethink analytics in terms of Hadoop and want to connect as much data as possible to their enterprise data hub. Customers see this move as an opportunity to break away from their older ETL handcuffs and move to a modern platform that embraces both the cloud and big data.
Currently mainstream approaches to bringing data into Hadoop are limited to Flume for for log data, Scoop for relational data, and custom apps for other other types of data. Now, anything SnapLogic can connect to becomes a data source for Hadoop, e.g., log files, relational data, on premise applications, and cloud applications. Similarly, these data sources easily become data destinations. We make big data elastic by providing flexible data acquisition and delivery so it is no longer siloed by difficult-to-set-up and difficult-to-use developer tools.
When will SnapReduce 2.0 be available?
As we stated in the press release, target availability is in the next few weeks. We’re currently working with the primary Hadoop distribution partners on certifications and we’ve kicked off an Early Access Program for some of our existing customers and prospects with active big data projects. You can learn more about SnapReduce 2.0 and sign up for the program on the SnapLogic website.
Good stuff. Thanks for the update Greg. We look forward to hearing much more about this and other big data integration initiatives coming soon from your team!
Next Steps:
- Learn more about SnapReduce 2.0
- Download the Elastic Data Integration Toolkit
- Find out about how we’re powering Amazon Redshift cloud-based analytics
- Watch a video on SnapTV
- Contact Us to discuss your cloud and big data integration requirements