In today’s competitive world, businesses understand the significance of innovation and modernization, and how migration to Cloud can help them achieve these to be successful. Many companies are looking for optimal ways to ingest and migrate their data from diverse sources including legacy on-premises systems to AWS.
Re-platforming projects are some of the most complicated projects, because unlike initiatives to build something new, you have to keep something operational that is already working for users and support the business, while you do pretty major work behind the scenes.
SnapLogic has worked with a number of customers to help them get these migrations right, in close collaboration with AWS. At this point, the cloud computing technology is not in question: it is proven over and over, in production and at scale. Huge businesses rely on the cloud every day. SnapLogic’s own control plane — critical to our company’s existence, not to mention the thousands of users who log into it every day — is hosted in AWS, taking advantage of its built-in resilience across different availability zones in a region, and across different regions, to let us and our customers concentrate on running our businesses.
Use case: Migrate data from legacy on-premises systems to Apache Iceberg tables in Amazon S3
Recently SnapLogic and AWS teams worked together to support a global agtech company, which set itself on a mission to help millions of farmers around the world to grow safe and nutritious food, while taking care of the planet. As part of supporting that mission, the company had an ambitious plan to move from their legacy on-premises systems to a new, more modern and less development- and maintenance-heavy approach to their enterprise-wide central data analytics capabilities.
Business challenge
The challenge was that centralizing data analysis would require access to a highly heterogeneous and complex IT landscape consisting of cloud services, on-premises applications, and databases of many different kinds, as well as legacy, custom-coded applications. This situation is common to many established enterprises, which have accumulated systems and data stores over the years for many different purposes, but now find themselves facing difficult choices.
The data ingestion process for this particular company had become complex and cost intensive due to diverse, historically developed legacy integration approaches and technologies which were requiring more and more difficult and expensive maintenance. Data engineers were spending up to 50% of their time on development and maintenance of data integrations, instead of being able to focus on more productive work.
Many cloud migration projects like this one have failed over the years due to a failure to embrace the potential of the new platforms and technologies. The company’s initial forays in this direction were disappointing, with hundreds of cloud jobs required just to maintain state. Worse, the new system was inflexible and did not support granular data operations, requiring users to overwrite data with each new period.
This integration project was not limited to simple connectivity, but also had to ensure levels of throughput and performance suitable for the global scale and business ambitions of the customer. Some of the biggest tables in the key business systems that needed to be exposed for integrated analytics were in the range of tens of billions of rows. Some of the APIs were returning tens of millions of objects to a single query, requiring the SnapLogic integration layer to chunk requests in order to ensure complete delivery and business visibility. Moreover there was sensitive data in some columns that needed encryption.
Solution overview
SnapLogic’s AI-powered, no-code iPaaS platform was able to easily integrate, transform and load data from diverse systems to Apache Iceberg tables in Amazon S3, thanks to over 750 native connectors to a wide range of applications. SnapLogic supports both ETL and ELT methodologies, which means data transformations could either be done on the SnapLogic platform, or on the destination system where data will be stored for further analysis.
A key part of the success of this integration was working with a full suite of technologies and partners.
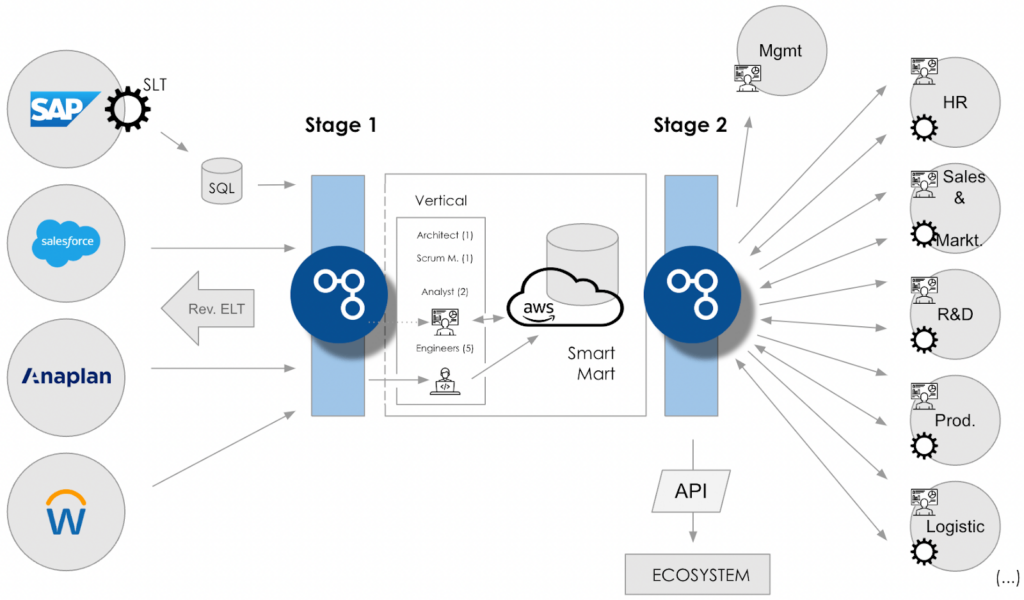
A particularly important technology when it came to delivering against the company’s requirements was Apache Iceberg, which enables a transactional datalake. SnapLogic used Amazon Athena to load and perform operations on data in Iceberg tables on Amazon S3. Iceberg tables could further be accessed for data analytics and machine learning via AWS services like Amazon Athena, Amazon Quicksight, Amazon Redshift, or other BI, visualization, and dashboard tools.
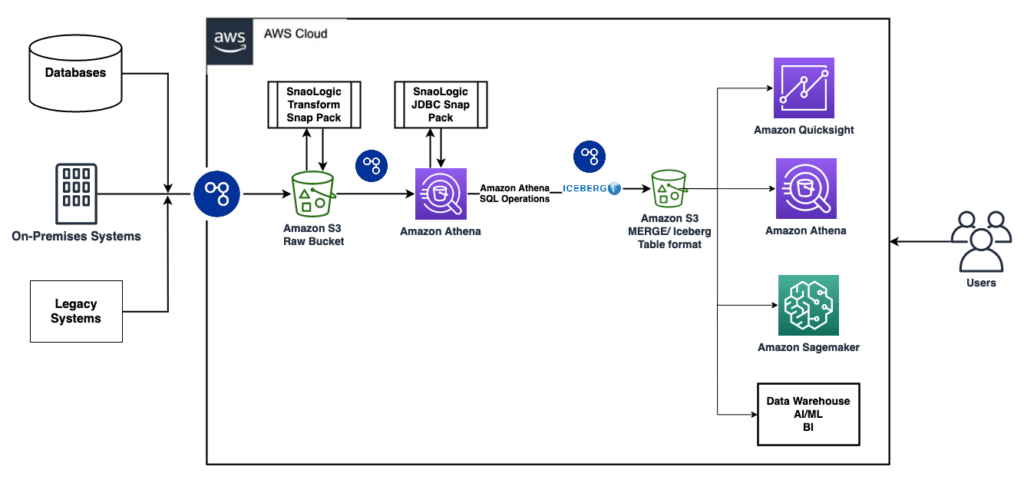
Key features
- The Encrypt Snap enabled encryption of sensitive data.
- The support for nested pipelines via SnapLogic’s Pipeline Execute capability was leveraged to achieve efficiency and modularity.
- SnapLogic’s support for parameters takes this flexibility further. For instance, parent pipelines can iteratively pass different parameter values to child pipelines.
- Multiple parallel pipelines ingested and processed data in separate chunks to speed up high-volume data ingestion from multiple source systems.
- In-flight data transformation was delivered via Mappers that transform data ingested from source systems.
- The flexibility of the SnapLogic platform is shown in our use of the Generic JDBC Execute Snap to connect to Amazon Athena.
Benefits
The solution built using SnapLogic and AWS services was able to deliver substantial reductions in effort for the design, development, testing and maintenance of integration and data ingestion pipelines. Business analysts now have unprecedented visibility into their own business and the data that underpinned it. All this data already existed and had already been gathered, with substantial effort, by employees, partners, and even customers. It was just too difficult to get access to in a timely and seamless manner. With this solution, different stakeholders at customer’s end were able to take advantage of advanced Iceberg features such as time travel queries, which enable users to run analytics based on the state of the data on a specific date. The customer now have a modern transactional datalake as the single source of truth for all their organizations.
By leveraging native support for each of the existing technology platforms, we were able to reduce the time required to develop and maintain integrations by up to 70%, resulting in an equivalent of more than 17 employees being freed up for new projects and faster innovation.
Conclusion
SnapLogic’s AI-enabled low-code/no-code platform is the key to unlocking maximum value from past and future investments in data. Tight integration with AWS services delivers fast time-to-market, ensuring that projected benefits do not remain theoretical but are quickly proved in practice.
With SnapLogic and AWS, this agtech company now has a modern and sustainable data platform that is for purpose, spanning both their legacy on-premises systems and the cloud systems on which they are building their future.
Here are some resources to learn more about SnapLogic and its capabilities:
- Register for the upcoming joint webinar from AWS and SnapLogic
- Visit the SnapLogic website and book a demo
- Check out upcoming SnapLogic Events and Webinars
- Register for SnapLogic Training Workshops
- Subscribe to a 30-day Free Trial of SnapLogic