Recently, I worked with a customer to reverse engineer a Pig Script running a MapReduce job in Hadoop and then orchestrated it as a SnapReduce pipeline with SnapLogic’s Elastic Integration Platform. SnapLogic’s HTML5 cloud-based Designer user interface and collection of pre-built components called Snaps made it possible to create a visual and functional representation of the data analytics workflow without knowing the intricacies of Pig and MapReduce. Here’s a quick writeup:
What is Pig Scripting Language?
Pig script is a high-level scripting language used with Apache Hadoop, for building complex applications to tackle business problems. Pig is used for interactive and batch jobs with MapReduce as the default execution mode.
About SnapReduce and the Hadooplex
SnapReduce and our Hadooplex enable SnapLogic’s iPaaS to run natively on Hadoop as a YARN application that elastically scales out to power big data analytics. SnapLogic allows Hadoop users to take advantage of an HTML5-based drag-and-drop user interface, breadth of connectivity (called Snaps), and modern architecture. Learn more here.
Overall Use Case (Product Usage Analytics)
Product usage raw data from consumer apps is loaded into Hadoop HCatalog tables and stored in RCFile format. The program reads data fields: product name, user, and usage history with date and time, cleanses the data and eliminates duplicate records grouping by timestamp. Find unique records for each user and write the results to HDFS partitions based on date/time. Product analysts then create an external table in Hive on top of the already partitioned data to query and create product usage and trend reports. They will write these reports to a file or export to a visual analytics tool like Tableau.
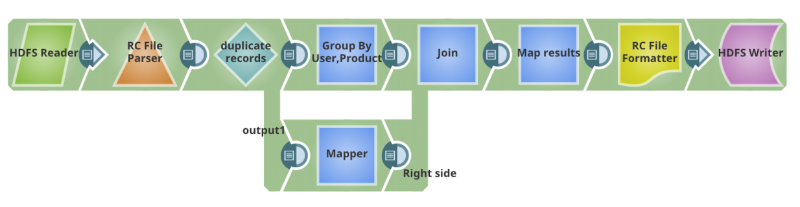
Here’s the Pig Script portion for the above use case (Cleansing data):
REGISTER / apps / cloudera / parcels / CDH / lib / hive / lib / hive - exec.jar SET default_parallel 24; DEFINE HCatLoader org.apache.hcatalog.pig.HCatLoader(); raw = load
'sourcedata.sc_survey_results_history' USING HCatLoader(); in = foreach raw generate user_guid, survey_results, date_time, product as product; grp_in = GROUP in BY(user_guid, product); grp_data = foreach grp_in { order_date_time = ORDER in BY date_time DESC; max_grp_data = LIMIT order_date_time 1; GENERATE FLATTEN(max_grp_data); }; grp_out_data = foreach grp_data generate max_grp_data::user_guid as user_guid, max_grp_data::product as product, '$create_date' as create_date, CONCAT('-"product"="', CONCAT(max_grp_data::product, CONCAT('",', max_grp_data::survey_results))) as survey_results; results = STORE grp_out_data INTO 'hdfs://nameservice1/warehouse/marketing/sc_surSnapReduce Pipeline equivalent for the Pig script
This SnapReduce pipeline is translated to run as a MapReduce job in Hadoop. It can be scheduled or triggered to automate the integration. It can even be turned into a reusable integration pattern. As you will see, it is pretty easy and intuitive to create a pipeline using SnapLogic HTML5 GUI and the Snaps to replace a Pig script.
The complete data analytics use case above was created in SnapLogic. I have only covered the Pig script portion here and plan to write up about the rest of the use case sometime later. Hope this helps! Here’s a demonstration of our big data integration solution in action. Contact Us to learn more.