





In the whitepaper, How to Build an Enterprise Data Lake: Important Considerations Before You Jump In, industry expert Mark Madsen outlined the principles that must guide the design of your new reference architecture and some of the difference from the traditional data warehouse. In his follow-up paper, “Will the Data Lake Drown the Data Warehouse,” he asks the question, “What does this mean for the tools we’ve been using for the last ten years?”
In this latest in the series of posts from this paper (see the first post here and second post here) Mark writes about tackling big data integration using an example:
“The best way to see the challenge faced when building a data lake is to focus on integration in the Hadoop environment. A common starting point is the idea of moving ETL and data processing from traditional tools to Hadoop, then pushing the data from Hadoop to a data warehouse or database like Amazon Redshift so that users can still work with data in a familiar way. If we look at some of the specifics in this scenario, the problem of using a bill of materials as a technology guide becomes apparent. For example, the processing of web event logs is unwieldy and expensive in a database, so many companies shift this workload to Hadoop.”
The following table summarizes the log processing requirements in an ETL offload scenario and the components that could be used to implement them in Hadoop:
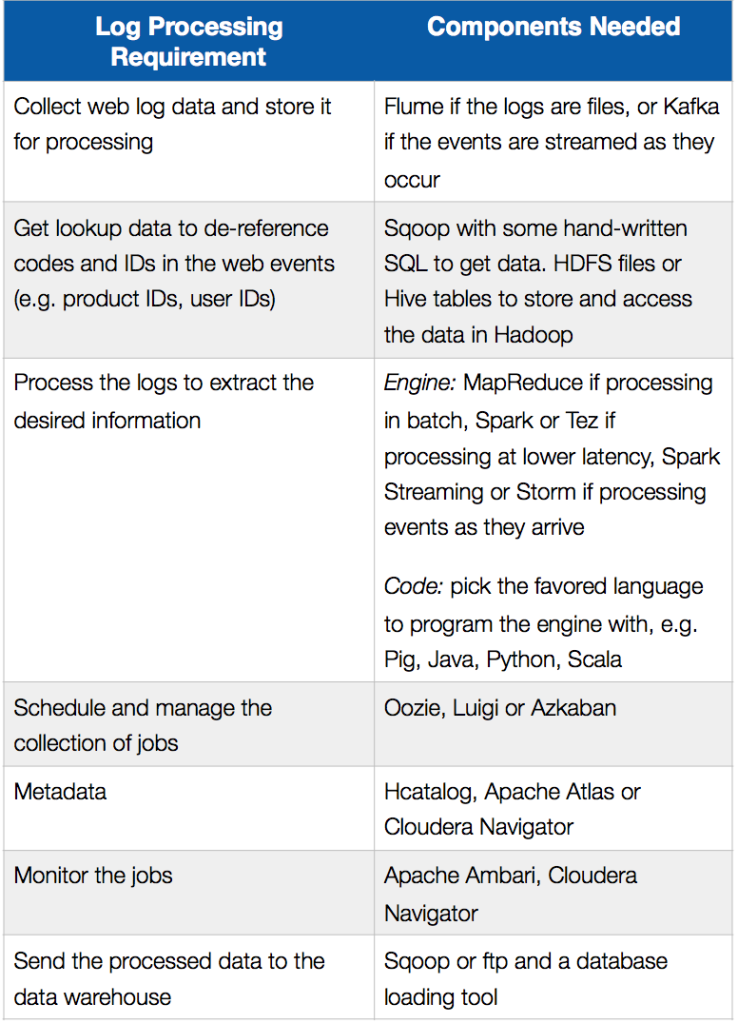
He goes on to review the development challenges and tradeoffs of following this type of an approach and concludes:
“Building a data lake requires thinking about the capabilities needed in the system. This is a bigger problem than just installing and using open source projects on top of Hadoop. Just as data integration is the foundation of the data warehouse, an end-to-end data processing capability is the core of the data lake. The new environment needs a new workhorse.”
Next steps:
- Download the whitepaper: How to Build an Enterprise Data Lake: Important Considerations Before You Jump In. You can also watch the recorded webinar and check out the slides on the SnapLogic blog.
- Download the whitepaper: Will the Data Lake Drown the Data Warehouse?
- Check out this demonstration of SnapReduce and the SnapLogic Hadooplex to learn about our “Hadoop for Humans” approach to big data integration.





