





This is the 3rd post in my series on SnapLogic Ultra Pipelines:
A robust error handling mechanism is imperative to avoid failures, disabling of the Ultra Pipeline task and a service disruption. Error handling can be added to Ultra Pipelines by following these guidelines:
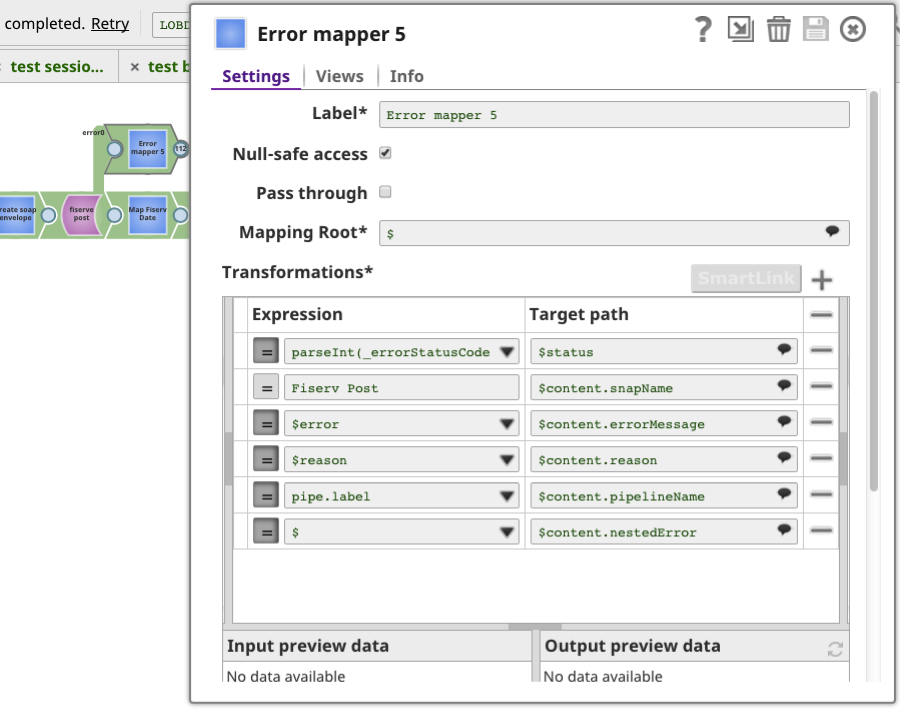
- Error views: By adding an error view to all crucial end point application Snaps in the pipeline and returning a response with custom error messages, code and http status code, you can be notified of errors in the document processing of Ultra Pipelines. The mapper Snap used in the pipeline below allows customizing information for error content when the REST post Snap fails.
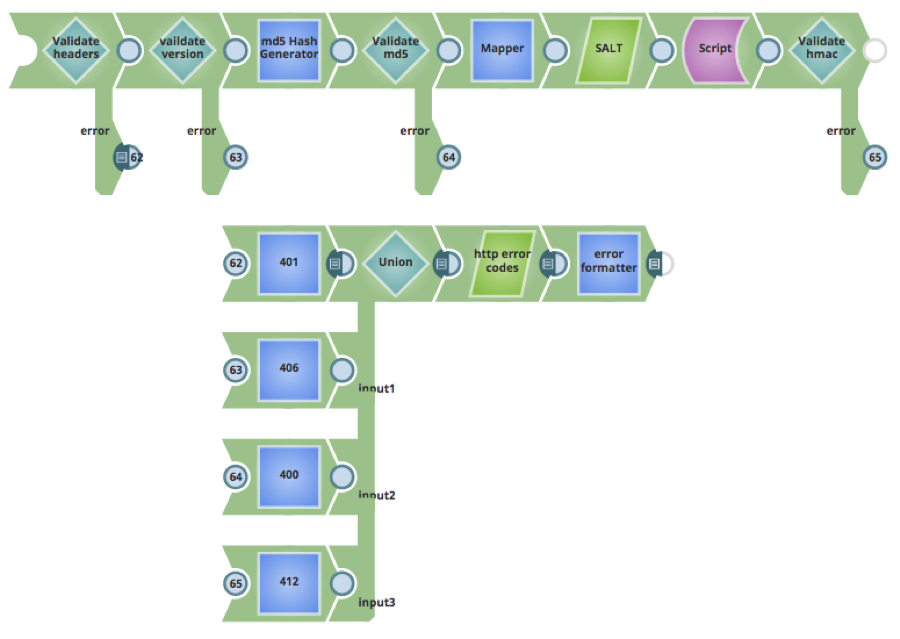
- Error code standard: Customers can agree on the adoption of standard HTTP response codes and messages to indicate success or failure of a request. A standard error code lookup file could be used to return specific error responses at different stages of the pipeline. In the pipeline below, a different HTTP status code is returned for each error response through the length of the pipeline; for example, invalid headers will result in HTTP response status code 401 and invalid version will result in 406.
After selecting a specific status code, further information on error can be retrieved by looking up a file of this structure:
[{
“response codes”: [{
“400”: {
“error code”: “4000”,
“error message”: “Malformed request body or missing a required parameter”
}
}, {
“401”: {
“error code”: “4010”,
“error message”: “No valid session key or credentials provided”
}
}]
}]
- A nested Ultra Pipeline task is created to return the contents of the error code lookup file; the nested Ultra Pipeline task is called using a Rest GET snap labeled as ‘http error codes’. The Mapper Snap labeled as ‘error formatter’ performs a look-up on the status code object from the file, returning relevant error code and message information.
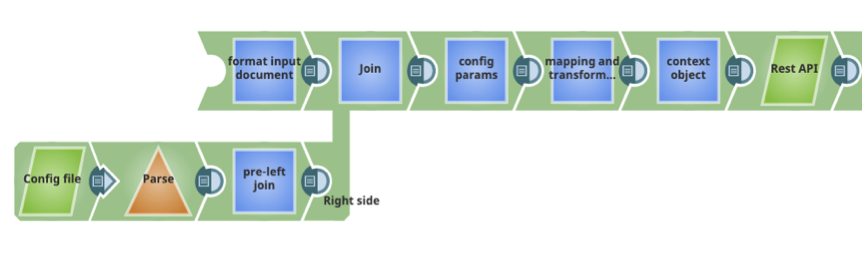
- Document lineage hierarchy: Every incoming document in an Ultra Pipeline Snap must maintain its lineage across the pipeline ensuring that the document is received, processed and responded to the feed-master. This allows the feed-master to use the correlation id to tie the request to the response. However, some use cases using static data from files or web services, can cause the document to lose its lineage and identity, resulting in failures due to the lineage hierarchy. Such a scenario can be avoided by using a join with a static key to join the static information with each request document. Care should be taken while using joins in Ultra Pipelines because Ultra Pipelines do not allow the batch processing of documents; each Snap in an Ultra Pipeline should process only one document at a time. The example shown below demonstrates the usage of a join with a static configuration file for parameter mapping.
- Nested Ultra Pipeline tasks – Nested Ultra Pipeline tasks can be called from Ultra Pipelines by using Rest Get/Post Snaps, however, nested Ultra Pipeline Tasks should be developed with robust error handling such that if any Snap in the nested Ultra Pipeline encounters an error, it can be returned to the parent pipeline along with the information on the Snap that failed the document processing. This can be accomplished by adding error views to all crucial Snaps in the nested Ultra Pipeline and introducing an error view to the Rest Get Snap calling the nested Ultra Pipeline.
- Including the original request document in case of error helps to ensure that you have detailed information on the request causing an error in the pipeline.
In my next post about SnapLogic Ultra Pipeline implementation best practices, I’ll cover performance, scaling and high availability.





