





Imagine trying to find a single landmark in a major foreign city without a map. Perhaps an exercise in futility, but the same analogy could be made for complex AI systems, with a complex circuitry of roads and arteries. Vector embeddings act as the map for artificial intelligence (AI) systems, translating complex data like text and images into numerical coordinates. These coordinates reveal the relationships between data points, allowing AI to perform tasks like search or recommendations with precision. However, without the right infrastructure, managing these embeddings can be overwhelming.
SnapLogic simplifies this process. With AgentCreator, SnapLogic makes it easy to create embeddings from your data, store them in vector databases, and query them for insights. With support for vector databases like Pinecone, MongoDB, Snowflake and many others, SnapLogic helps enterprises leverage embeddings to enhance AI-driven workflows and power smarter applications.
What are vector embeddings?
Vector embeddings are crucial to many AI applications. They help machines process complex, unstructured data like text, images, and audio. By converting this data into numerical vectors, embeddings reveal patterns and relationships that traditional methods often miss. For instance, in semantic search, embeddings allow systems to understand the meaning behind words, not just match keywords. Similarly, they power recommendation engines by identifying similarities between items or user behaviors.
With generative AI (GenAI), embeddings are critical at every stage. During training, large language models (LLMs) learn from vectorized data, enabling them to grasp the relationships between words and concepts. When a user enters a prompt, the model converts it into vectors to capture meaning and context. This process allows LLMs to generate accurate, contextually relevant responses by identifying patterns within the input.
By leveraging these embeddings, generative AI doesn’t just respond, it:
- Retrieves information
- Builds on existing data
- Finds meaningful connections
This makes it a powerful tool for workflows like search, personalization, and automation, driving the shift to an agentic enterprise.

Generating vector embeddings with SnapLogic
SnapLogic’s integration with OpenAI and other LLMs makes generating vector embeddings simple and easy. Through the Azure OpenAI Embedder Snap, users can quickly create embeddings from various data types, such as text or images. This process converts input data into numerical vectors, making it easily and efficiently readable by machines.
A user-friendly interface simplifies the process of vectorizing data. With its drag-and-drop functionality, building pipelines to generate embeddings is intuitive, even for non-technical users.
For example, consider an organization that stores internal knowledge documents, such as policies, research reports, or training manuals. By generating embeddings for these documents, the company can use Retrieval Augmented Generation (RAG) to enhance responses from an LLM. When a user inputs a question, the system retrieves relevant documents based on the vectorized embeddings, and the LLM uses this information to generate more accurate and context-rich answers.
Storing and querying embeddings with AgentCreator
Vector databases are essential for scaling GenAI assistants, applications, and agents by efficiently storing and retrieving embeddings. They enable fast searches and retrievals of data in a way that traditional databases struggle to match. SnapLogic supports several vector databases, including Pinecone, OpenSearch, MongoDB, AlloyDB, PostgreSQL, and Snowflake, allowing enterprises to seamlessly store and manage embeddings generated from their data.
Querying vector embeddings is key to powering advanced AI features like search and recommendation engines. By finding similarities between embeddings, AI systems can quickly retrieve relevant content, personalizing results for users. SnapLogic simplifies this process by integrating with vector databases that support Approximate Nearest Neighbor (ANN) search, enabling efficient querying of stored embeddings.
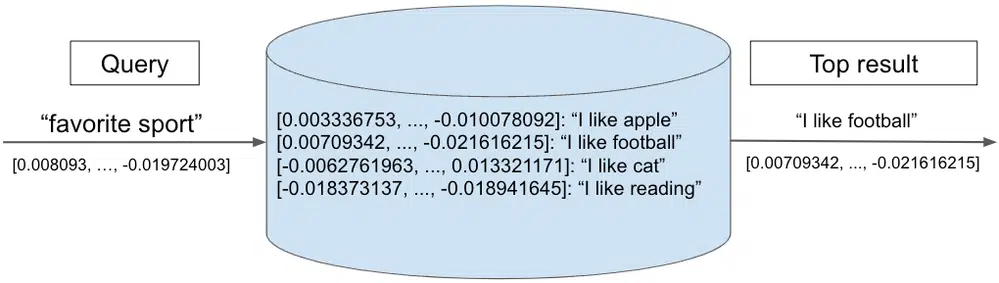
The following diagram illustrates a vector database search. A query vector “favorite sport” is compared to a set of stored vectors — each representing a text phrase. The nearest neighbor, “I like football,” is returned as the top result.


The SnapLogic AgentCreator further enhances these capabilities by supporting leading LLMs from Amazon, OpenAI, Azure, and Google. These LLMs allow enterprises to query embeddings and use these advanced models for tasks like prompt generation, chat completions, and content creation.
SnapLogic’s seamless integration with vector databases and LLMs enables organizations to efficiently store, query, and generate content while maintaining high performance and accuracy. In practice, this process might look this:
- Step 1: The company generates vector embeddings from its internal knowledge base (e.g., FAQs, product manuals) using SnapLogic’s Azure OpenAI Embedder Snap.
- Step 2: These embeddings are stored in the Pinecone vector database, optimized for fast retrieval.
- Step 3: When a customer query is received, Pinecone performs an Approximate Nearest Neighbor (ANN) search to retrieve relevant documents.
- Step 4: Using Google’s Gemini LLM via the Google GenAI LLM Snap Pack, the system generates a personalized, context-rich response by combining the retrieved data with real-time AI content generation.
Harness the power of vector databases and embeddings for your business
If you’re looking to build a GenAI agent that takes full advantage of vector data, AgentCreator is your solution. With easy integration, support for multiple vector databases, and seamless workflows, you can scale your AI projects with confidence.
Ready to take the next step?
- Learn more about AgentCreator
- Book a demo with an expert
- Dive deeper into vector databases and embeddings in the SnapLogic Community






