In a previous blog post, I discussed major trends in the data integration space and customers moving from on-prem to cloud. I’d like to focus on one trend which involves moving data from on-premises or cloud data analytics platforms to a Data Lake technology such as Azure Data Lake.
What is a Data Lake?
The Data Lake is a term coined for storing large amounts of data in its raw native form, including structured and unstructured data in one location. This data can come from various sources, and the Data Lake can act as a single source of truth for any organization. From the architecture standpoint, the data is first stored in data swamp/data acquisition, then cleansed/transformed as part of data transformation, and later published to gain business insights.
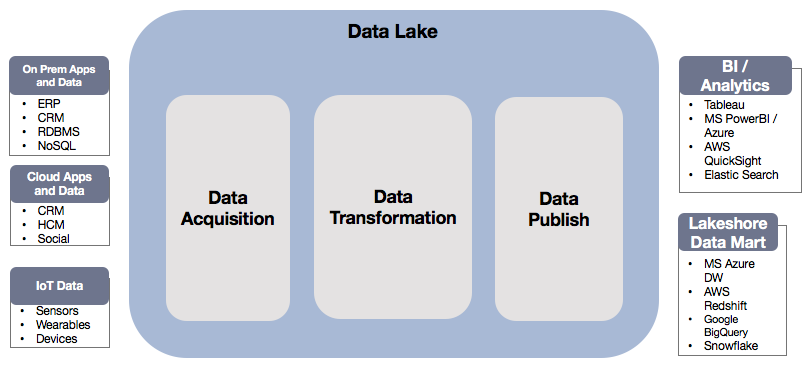
As seen in the diagram above, enterprises have multiple systems such as ERP, CRM, RDBMS, NoSQL, IoT sensors, etc. The disparate data, stored in different systems makes, is difficult to pull data from. A Data Lake brings all the data under one roof (data acquisition) using one of the following services:
- Azure Blob
- Azure Data Lake Store
- Amazon S3
- HDFS
- Others
Data stored in one of these services can then be transformed in the following ways:
- Aggregate
- Sort
- Join
- Merge
- Other
The transformed data is then moved to the data publish/data access section (could be the same as data acquisition services) where users can utilize the following tools to query the data:
- Microsoft’s U-SQL
- Amazon Athena
- Hive
- Presto
- Others etc.
The bottom line is that a Data Lake can serve as a platform to run analytics in order to provide better customer experience, recommendations, and more.
Where does data get stored in Azure?
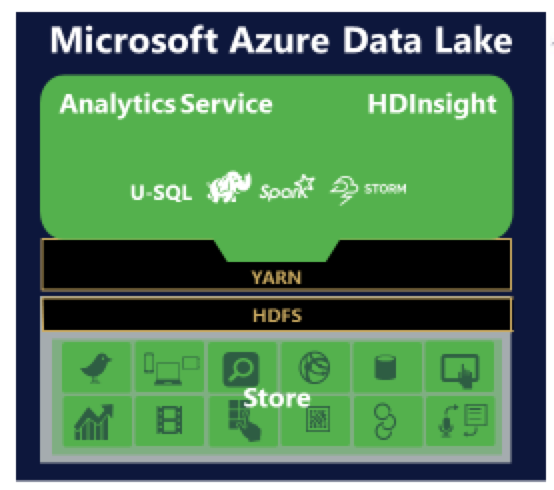
Azure Data Lake is one such Data Lake from Microsoft and the repository used to store all the data is Azure Data Lake Store. Users can run Analytics Service, HDInsight or use U-SQL – a big data query language on top of this data store to gain better business insights.
Azure Data Lake Store (ADLS) can store any data in its native format. One of the goals of this data store is to bring data from disparate sources. The Snaplogic Enterprise Integration Cloud with its pre-built connectors called Snaps help by moving data from different systems to the data store in a fast manner.
ADLS provides a complex API, which applications use to store data in ADLS. Snaplogic has abstracted all these complexities via Snaps so users know where data is stored in Azure and can now easily move data from various systems to ADLS without needing to know anything of the complexities of these APIs.
Use case
A business needs to track and analyze content to better recommend products or services to its customers. Its data – from various sources such as Oracle, files, Twitter, etc. – needs to be stored in a central repository such as ADLS so that business users can run analytics on top to measure customer buying behavior, their interests, and products purchased.
Here’s a sample pipeline that can address this use case using Snaps:
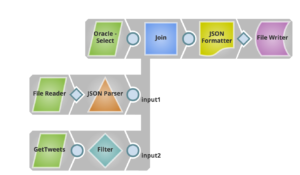
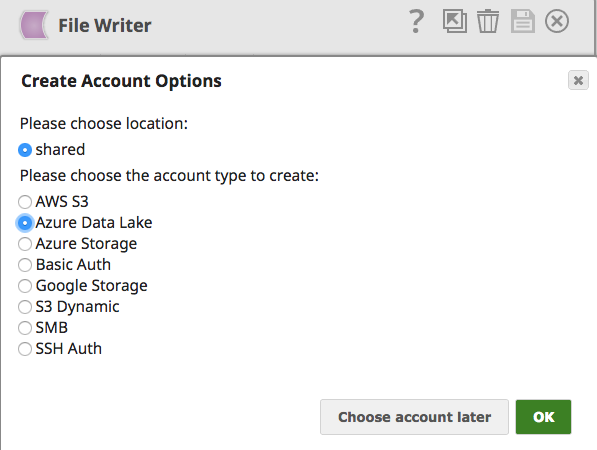
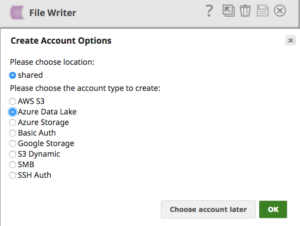
Using the File Writer Snap and choosing the Azure Data Lake account as shown below, one can store the data merged from various systems into Azure Data Lake with ease.
All in all, the Data Lake can be a one-stop shop of storage for any data, giving users more ways to derive insights from multiple data sources. And SnapLogic is ready to make it easier for users to move their data into the Data Lake (in this case, an Azure Data Lake Store) in a quick and easy way.
Pavan Venkatesh is Senior Product Manager at SnapLogic. Follow him on Twitter @pavankv.