





Agentic
Integration
Tips and Tricks
Join the agentic integration movement around the world and receive the SnapLogic Blog Newsletter.
By clicking on the button above, you agree to SnapLogic’s Terms, Privacy and Cookie Policies. You also agree to receive future communications from SnapLogic. You can unsubscribe anytime.




Search Results
-

9 min read
Best iPaaS for Higher Education: A Complete Guide for University Technology Leaders in 2026

-

4 min read
Your AI Agent Has Too Much Access (And You Probably Don’t Know It)

-
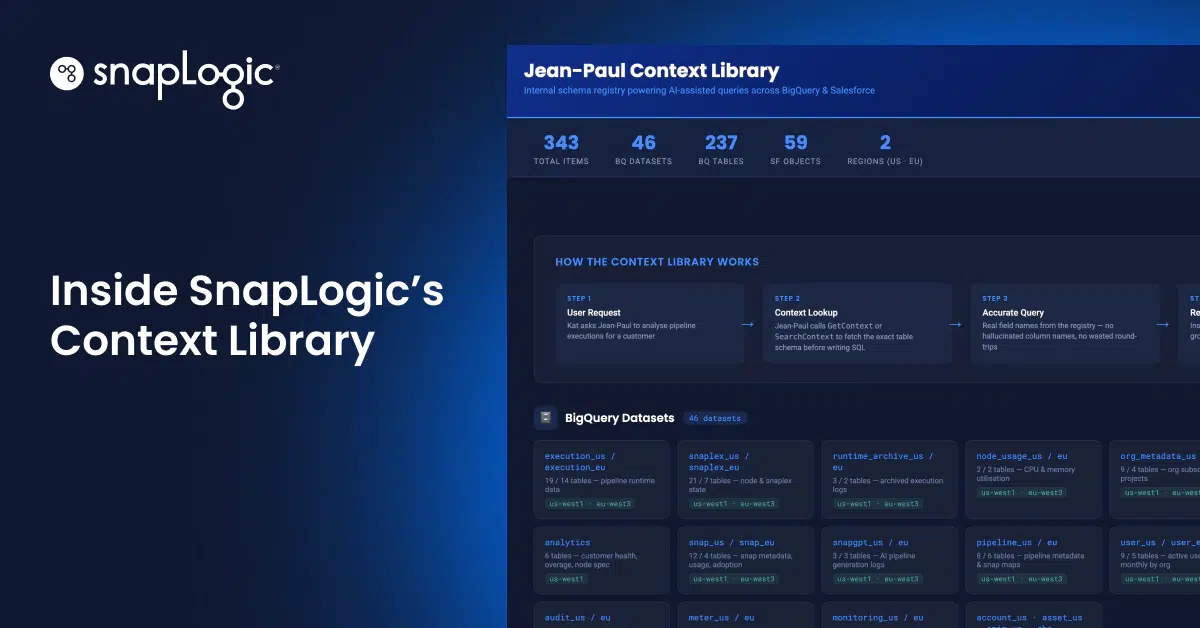
8 min read
The Context Library That Keeps Enterprise AI Grounded in Live Data

-

6 min read
From AI Experiments to Evidence: SnapLogic at Gartner Data & Analytics London
-

5 min read
What’s New in SnapLogic: May 2026 Product Release
-
10 min read
Best iPaaS for Software and Technology Companies: A Complete Guide for Enterprise Leaders (2026)
-

2 min read
MCP Server Token Propagation

-

7 min read
Your Data Agent Is Only as Smart as Its Context (So We Built One That Gets It Right)
-

4 min read
The Revenue Signal You’re Missing: Why Integration Is the Foundation of Customer Retention
-

6 min read
Gartner’s New Hype Cycle Shows Agents Are About to Explode: Why Integration Is the Real Battleground
-
8 min read
SnapLogic vs. Workato: A Modern Integration Platform Comparison (2026)
-

6 min read
Navigating AI Compliance and Data Governance in the Financial Industry: Insights From FIMA
Latest Posts
AI Posts
Data Posts



Product Posts
Company Update Posts




Integration Posts



Subscribe to our blog to get the latest posts in your inbox
By clicking on the button above, you agree to SnapLogic’s Terms, Privacy and Cookie Policies. You also agree to receive future communications from SnapLogic. You can unsubscribe anytime.