






Les données sont de plus en plus reconnues comme la monnaie d‘entreprise de l‘ère numérique. Les entreprises veulent tirer parti des données pour obtenir des informations plus approfondies, ce qui leur confère un avantage concurrentiel par rapport à leurs homologues. Selon les projections d‘IDC, le volume total des données mondiales atteindra 163 zettaoctets (ZB) d‘ici à 2025, soit 10 fois plus qu‘aujourd‘hui. Cette mine d‘or potentielle de données numériques est sur le point de déclencher une nouvelle ère d‘innovation, d‘ouvrir de nouvelles sources de revenus, de permettre la création de produits de nouvelle génération et d‘offrir aux entreprises les informations nécessaires pour réaliser des gains d‘efficacité et d‘augmenter leur productivité. Cette explosion des données a conduit les entreprises à aller au-delà du monde de l‘entreposage traditionnel des données et à explorer comment construire avec succès des lacs de données sur le site cloud afin d‘accéder à des données qu‘elles n‘ont pas été en mesure d‘analyser par le passé.
La clé de l‘innovation est la gestion des données
La clé de l‘innovation basée sur les données réside dans la manière dont les données sont capturées, traitées, gérées et analysées. Mais le volume, la variété et la rapidité des données d‘aujourd‘hui font qu‘il est presque impossible de placer l‘entrepôt de données de l‘entreprise au centre d‘une architecture de données. L‘entrepôt de données de l‘entreprise n‘a tout simplement pas les caractéristiques d‘évolutivité ou de performance nécessaires pour gérer le déluge d‘informations structurées et non structurées extraites des applications d‘entreprise existantes et provenant de sources en temps réel telles que les capteurs, les vidéos, les blogs et l‘internet des objets (IoT). Un entrepôt de données peut traiter des données non structurées, mais il ne le fait pas de la manière la plus efficace. Compte tenu de la quantité de données disponibles, le stockage de toutes les données dans un entrepôt de données traditionnel peut s‘avérer très coûteux. Un lac de données est un endroit où stocker vos données structurées et non structurées, ainsi qu‘une méthode pour organiser de grands volumes de données très diverses provenant de différentes sources. Le lac de données a tendance à ingérer les données très rapidement et à les préparer ultérieurement, à la volée, au fur et à mesure que les gens y accèdent.
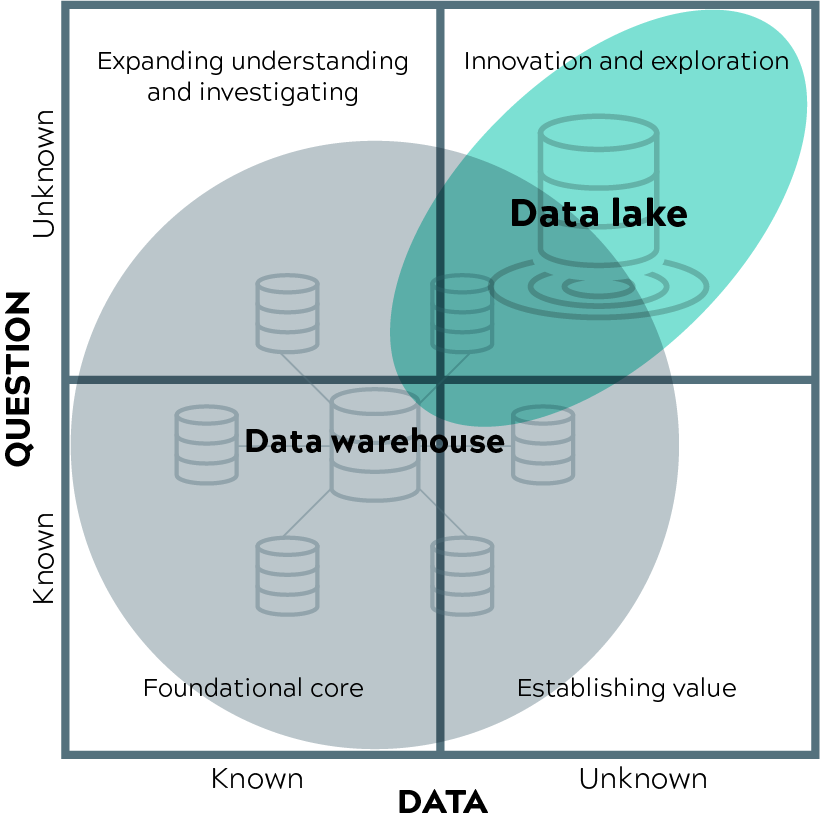
Voici un cadre inspiré par Gartner, qui permet de réfléchir à la question de savoir si un entrepôt de données traditionnel ou un lac de données est le plus judicieux. Tout dépend si vous savez ce dont vous avez besoin et si les données dont vous avez besoin sont connues ou non.
Comment déterminer si un lac de données peut répondre aux défis de gestion des données de votre organisation et comment vous y préparer si c‘est effectivement le cas ? Voici cinq questions à garder à l‘esprit :
Quelle est la composition du mélange de données ? Si les besoins de l‘entreprise sont satisfaits par l‘agrégation et l‘analyse d‘informations tabulaires, essentiellement structurées, stockées dans des systèmes transactionnels tels que les progiciels de gestion intégrés (ERP), les entrepôts de données traditionnels restent probablement la meilleure approche. Cependant, si le mélange de données commence à englober du matériel non structuré ou même semi-structuré et, surtout, s‘accumule à un rythme rapide - pensez aux données en temps réel et en continu - alors un lac de données devrait être envisagé comme un moyen plus économique de traiter le volume à l‘échelle.
Existe-t-il une stratégie bien définie pour le lac de données ? L‘attrait d‘un lac de données réside en grande partie dans son appétit quasi insatiable pour l‘ingestion de toutes sortes de données et dans la flexibilité qu‘il permet de conserver pour un usage ultérieur sans nécessairement savoir ce que l‘on veut en faire. En même temps, sans une stratégie initiale englobant l‘origine des données, leurs destinataires et certaines pratiques de gouvernance spécifiques, les organisations informatiques risquent de se retrouver au point de départ : Ils se retrouvent avec une série de systèmes cloisonnés qui ne répondent pas aux besoins de l‘entreprise et qui ne peuvent pas évoluer efficacement.
Avez-vous un accès facile aux compétences en matière de big data ? Les organisations qui regorgent d‘experts en entrepôts de données et d‘analystes commerciaux ne savent pas nécessairement ce qu‘il faut faire pour travailler dans l‘univers des big data, en particulier les lacs de données. La connaissance des nouvelles technologies open source telles que Hadoop, MapReduce, Flink, Flume, Kafka ou Spark est désormais essentielle, tout comme le besoin d‘ingénieurs en données capables d‘écrire du code pour traiter les données à grande échelle à l‘aide de langages de programmation tels que Scala, Java et Python. Il faut également des data scientists capables d‘exploiter des langages de programmation tels que Python et R pour préparer les données et élaborer des modèles analytiques permettant d‘obtenir des informations plus approfondies. En plus de ce nouveau jeu de techniques et d‘outils, les organisations doivent également réorienter leurs pratiques de gestion des données pour adopter des méthodologies agiles afin de maximiser les avantages d‘une architecture de lac de données.
Quelles sont les contraintes de temps à prendre en compte ? Les données qui sont introduites dans un entrepôt de données d‘entreprise doivent être nettoyées et préparées avant d‘être stockées. Et comme les données non structurées d‘aujourd‘hui sont générées dans différents formats bruts à un rythme rapide, il peut s‘avérer ardu d‘arriver aux étapes de nettoyage et de préparation alors que l‘on n‘est même pas complètement sûr de l‘utilisation qui sera faite des données. Le lac de données est conçu pour traiter les données non structurées de la manière la plus rentable possible, les couches de calcul et de stockage pouvant être mises à l‘échelle de manière indépendante et élastique. Avec une approche de lac de données, les utilisateurs peuvent obtenir leurs données le plus rapidement possible afin de pouvoir répondre aux cas d‘utilisation opérationnels concernant les rapports opérationnels, l‘analyse et la surveillance de l‘entreprise.
Comment allez-vous répondre aux besoins d‘intégration des données ? Un rapport de Cap Gemini sur les retombées du big data a identifié les défis d‘intégration comme l‘un des principaux obstacles à la réussite du big data (cité par 35 % des personnes interrogées). Un autre rapport, réalisé par TDWI, a révélé que le manque d‘outils d‘intégration des données était un obstacle à la réussite de la mise en œuvre d‘un lac de données pour 32 % des personnes interrogées. Avant d‘aller de l‘avant, il faut établir une feuille de route pour l‘acquisition et l‘intégration des données qui soit parfaitement adaptée au nouveau paradigme.
L‘entrepôt de données de l‘entreprise restera un élément essentiel de l‘architecture moderne des données de l‘entreprise (MEDA), mais il doit désormais être considéré comme une application "en aval", une destination, mais pas le centre de votre univers de données. Les lacs de données, bien qu‘ils ne soient pas une panacée, ont un énorme potentiel non seulement pour permettre à un public plus large d‘accéder à des données qu‘il n‘a pas pu obtenir dans le passé, mais aussi pour le faire de manière rentable. Il ne suffit pas de sauter dans le dernier train de la haute technologie - il faut plutôt s‘assurer de poser les bonnes questions et d‘examiner toutes les considérations pour s‘assurer qu‘un lac de données est la bonne approche pour les besoins de votre organisation en matière de données.





