What is ETL?
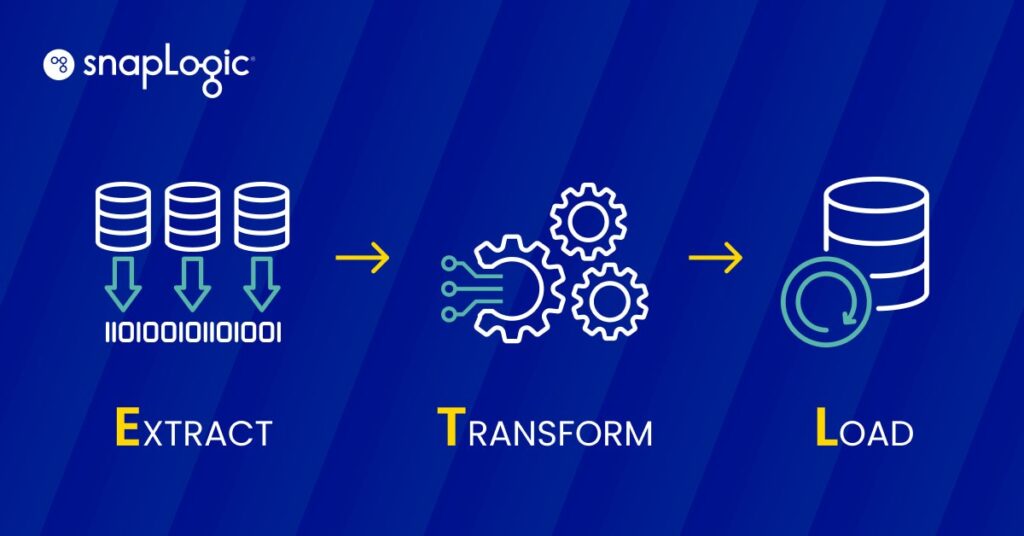
ETL (Extract, Transform, Load) is a data integration process involving three key steps: extracting data from disparate sources, transforming it to fit operational needs, and loading it into a destination system for analysis and reporting. This process is foundational in data warehousing, enabling effective data consolidation, management, and utilization for business intelligence.
How does ETL work?
ETL operates through a three-step process designed to effectively manage data extraction, transformation, and loading into a central repository.
- Extraction: This first step involves pulling data from diverse sources, which could be databases, spreadsheets, or other formats. The aim here is to gather the necessary data in its original format, regardless of the source’s structure or type.
- Transformation: Once data is extracted, it goes through a transformation phase where it is cleaned and converted to match the target system’s requirements. This step may involve filtering, sorting, validating, and aggregating data to ensure it meets quality and format standards for analytical purposes.
- Loading: The final step is loading the transformed data into a destination system, such as a data warehouse or database. This stage is crucial as it makes the data accessible for business analysis and decision-making processes.
Each stage is pivotal in ensuring that the data is usable, secure, and efficiently stored, making ETL an essential process for data warehousing and business intelligence initiatives.
What is an ETL pipeline?
An ETL pipeline formalizes the process of data movement and transformation described earlier in this article. It is a sequence of operations implemented within an ETL tool to ensure that data is extracted from the source systems, transformed correctly, and loaded into a data warehouse or other systems for analysis.
Structured Workflow: The ETL pipeline encompasses the three main stages of ETL—extraction, transformation, and loading—into a structured workflow. This structured approach helps in managing data flow and ensures that each phase is completed before the next begins.
Automation: ETL pipelines automate the repetitive and routine tasks of data handling. This automation supports the continuous ingestion of data, its transformation according to business rules and requirements, and the subsequent loading of processed data into analytical or operational systems for business intelligence, reporting, and decision-making.
Integration and Scheduling: In an ETL pipeline, tasks are typically scheduled and managed by an orchestration tool, which coordinates the execution of different jobs based on data availability, dependencies, and successful completion of preceding tasks. This scheduling is crucial for maintaining data freshness and relevance, especially in dynamic business environments where data needs are continuously evolving.
Monitoring and Maintenance: An effective ETL pipeline also includes monitoring capabilities to track data flows, manage errors, and ensure data quality. Maintenance involves updating the transformations and processes in response to changes in the source systems or business requirements.
What’s the difference between ETL and ELT?
The difference between ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) primarily lies in the order and location where data transformation occurs, which impacts data processing workflows, particularly in handling large volumes of data from various sources.
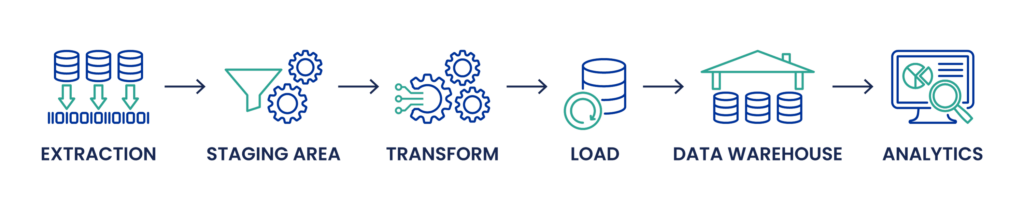
ETL Process: In the traditional ETL process, data is first extracted from source systems, which can include relational databases, flat files, APIs, and more. This extracted data is then transformed in a staging area, where data cleansing, deduplication, and other transformation processes occur to ensure data quality and consistency. The transformation process can involve complex SQL queries, handling of different data types, and data engineering tasks like schema mapping and metadata management. Only after these transformations is the data loaded into the target database or data warehouse, such as Snowflake or Microsoft SQL Server, for use in data analytics, business intelligence, and visualization.
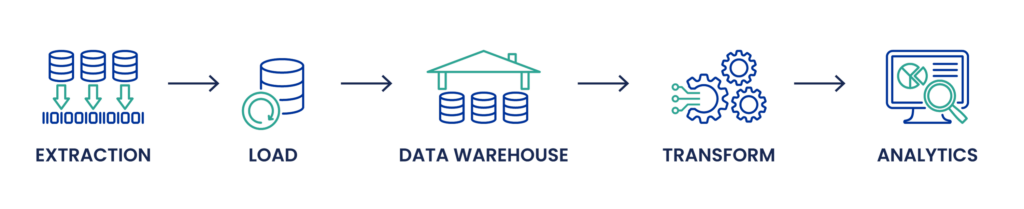
ELT Process: ELT, on the other hand, reverses the last two steps of ETL. Data is first extracted and loaded into a data lake or a modern data store like Google BigQuery or Amazon Redshift, often in its raw form. This approach is particularly advantageous when dealing with massive amounts of data, including unstructured data from IoT devices, NoSQL databases, or JSON and XML files. Transformation occurs after loading, leveraging the powerful data processing engines of these platforms. This method allows for more flexibility in managing data schemas and can handle real-time data processing needs, enabling more agile data pipeline adjustments and facilitating machine learning and artificial intelligence applications.
Key Differences:
- Data Volume and Variety: ELT is generally better suited for big data scenarios where large data sets are ingested from different sources. It efficiently manages unstructured data and automates data transformations within the data storage system.
- Performance and Scalability: ELT can offer better performance for large volumes of data and is highly scalable due to the powerful processing capabilities of modern cloud-based data stores.
- Flexibility: ELT provides more flexibility in querying and managing data, as transformations are applied on an as-needed basis within the data lake or warehouse.
In summary, the choice between ETL and ELT depends on the specific data management needs, the nature of the data sources, the intended use cases for the data, and the existing data infrastructure. ELT is gaining popularity in environments that prioritize flexibility, scalability, and real-time data processing, while ETL remains relevant for scenarios requiring intensive data cleansing and transformation before data can be stored or analyzed.
Free eBook: ETL vs. ELT: Which One Is Right for Your Organization?
What is Traditional ETL vs Cloud ETL?
Traditional ETL and Cloud ETL represent two methodologies of handling data extraction, transformation, and loading processes, each suited to different technological environments and business needs.
Traditional ETL: Traditional ETL processes are designed to operate within on-premises infrastructure. This involves physical servers and storage that a company owns and maintains. The ETL tools in this environment are typically part of a closed, secure network. Key characteristics include:
- Control and Security: Since the infrastructure is on-premises, companies have complete control over their systems and data, which can be crucial for industries with strict data security and compliance requirements.
- Upfront Investment: Traditional ETL requires significant upfront capital investment in hardware and infrastructure.
- Maintenance: Requires ongoing maintenance of hardware and software, including upgrades and troubleshooting, which can be resource-intensive.
- Scalability Challenges: Scaling requires additional physical hardware, which can be slow and costly.
Cloud ETL: Cloud ETL, on the other hand, leverages cloud computing environments, where resources are virtually scalable and managed by third-party providers. This approach has gained popularity due to its flexibility, scalability, and cost-efficiency. Characteristics include:
- Scalability and Flexibility: Cloud ETL can easily scale resources up or down based on the processing needs, often automatically. This flexibility is valuable for handling variable workloads and big data processing.
- Reduced Capital Expenditure: With cloud ETL, companies avoid the large upfront costs associated with traditional ETL, paying instead for what they use, often on a subscription basis.
- Enhanced Collaboration and Accessibility: Cloud solutions provide better accessibility for distributed teams, enabling collaboration across different geographical locations.
- Integration with Modern Data Services: Cloud ETL tools are designed to integrate seamlessly with other cloud services, including advanced analytics, machine learning models, and more, providing a comprehensive data processing pipeline.
The choice between traditional and cloud ETL depends on several factors, including the company’s data strategy, security needs, budget constraints, and specific use cases. Cloud ETL offers a modern approach that aligns with digital transformation initiatives and supports more dynamic, data-driven decision-making environments. Traditional ETL, while sometimes constrained by its physical nature, remains a solid choice for organizations that require tight control over their data infrastructure and operations.