





Was ist Apache Hive? Hive bietet einen Mechanismus zur Abfrage, Erstellung und Verwaltung großer Datensätze, die in Hadoop gespeichert sind, unter Verwendung SQL-ähnlicher Anweisungen. Es ermöglicht auch das Hinzufügen einer Struktur zu bestehenden Daten, die sich auf HDFS befinden. In diesem Beitrag beschreibe ich einen praktischen Ansatz, wie man mit der SnapLogic Elastic Integration Platform Daten in Hive einspeisen kann, ohne Code schreiben zu müssen.
Datenflusspipelines, die auch als SnapLogic Pipelines bezeichnet werden, werden in einem äußerst intuitiven visuellen Designer mit Hilfe eines Drag & Drop-Ansatzes erstellt. Eine Datenflusspipeline besteht aus einem oder mehreren Snaps, die miteinander verbunden sind, um den Fluss der Unternehmensdatenintegration zwischen Quellen und Zielen zu orchestrieren. Snaps sind die Bausteine einer Pipeline, die eine einzelne Funktion ausführen, wie z. B. das Lesen, Schreiben oder Verarbeiten von Daten. SnapLogic Snaps unterstützen das Lesen und Schreiben in verschiedenen Formaten wie CSV, AVRO, Parquet, RCFile, ORCFile, Text mit Trennzeichen und JSON. Zu den unterstützten Komprimierungsverfahren gehören LZO, Snappy und gzip.
Hier ist also ein Szenario: Angenommen, wir haben Kontaktdaten, die aus mehreren Quellen stammen und in Hive aufgenommen werden müssen. Wir müssen Daten aus verschiedenen Quellen kombinieren, z. B. Rohdateien auf HDFS, Daten auf S3 (AWS), Daten aus Datenbanken und Daten aus Cloud-Anwendungen wie Salesforce oder Workday. Wie kann man nun mit der Aufnahme von Daten aus diesen unterschiedlichen Quellen in Hive beginnen?
Der erste Schritt besteht darin, eine Hive-Datenbank und/oder -Tabellen zu erstellen. Mit dem SnapLogic Hive Integration Snap können Sie jede Hive DML/DDL ausführen, einschließlich der Erstellung von Datenbanken und Tabellen.
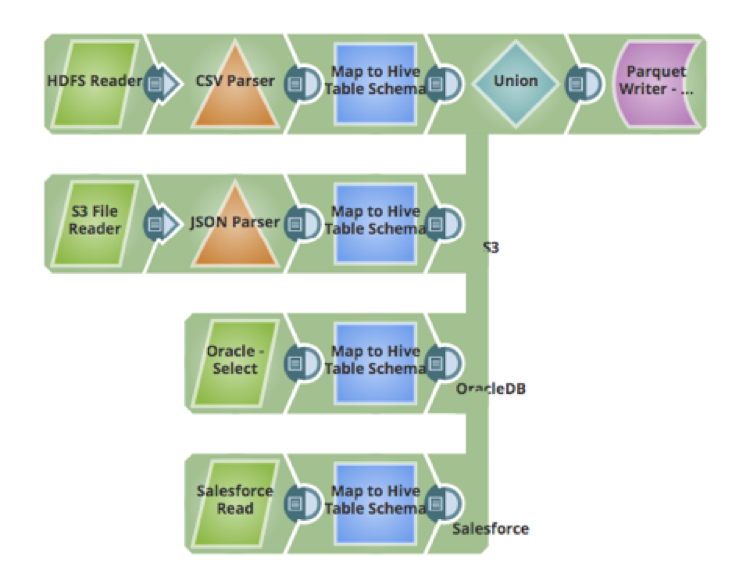
Im nächsten Schritt geht es um die Aufnahme der Daten. Eine der Herausforderungen bei der Übernahme von Daten aus mehreren Quellen ist die Zuordnung, Umwandlung und Bereinigung der Daten. Mit dem Mapper-Snap kann man Felder aus dem Quellschema in das Zielschema mappen, Daten bereinigen, Transformationen an den Daten vornehmen, neue Attribute zum Schema hinzufügen und andere Aktionen durchführen. Nachfolgend sehen Sie eine Pipeline, die Daten aus vier Quellen abruft, die Daten transformiert, um sie der Hive-Tabelle zuzuordnen, und die Daten in die Hive-Tabelle einfügt (die das Parquet-Datenformat verwendet):
- CSV-Rohdaten-Dateien auf HDFS
- JSON-Dateien, die auf Amazon S3 gehostet werden
- Daten aus einer Tabelle in einer Oracle-Datenbank
- Daten, die in einer Cloud-Anwendung wie Salesforce gehostet werden
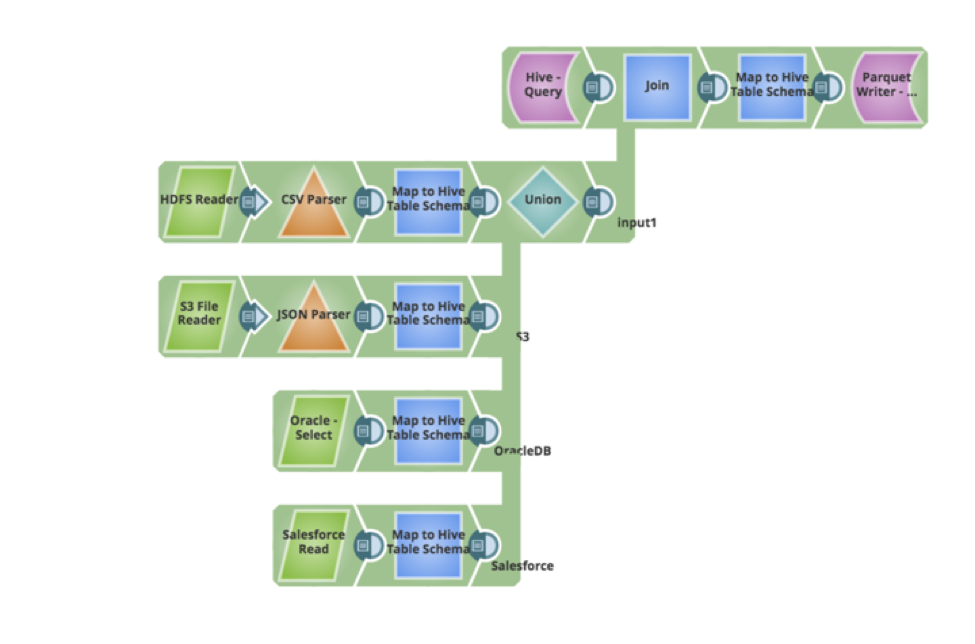
Nehmen wir an, wir haben eine neue Anforderung von Ihren Geschäftsanwendern - dass die vorhandenen Daten in der Hive-Tabelle aktualisiert und neue Datensätze eingefügt werden müssen. Die Pipeline kann leicht aktualisiert werden, um die vorhandenen Daten abzufragen, einen Full Outer Join durchzuführen und die Daten als Parquet zurückzuschreiben. Nachfolgend sehen Sie die Pipeline, mit der die neuen Anforderungen umgesetzt wurden, und zwar auf visuelle Weise, ohne dass Code oder Skripte geschrieben werden mussten.
In meinem nächsten Beitrag werde ich weitere Ingestion Patterns vorstellen und erläutern, wie sie mit der SnapLogic-Plattform implementiert werden können.




