





Laut McKinsey werden die Mitarbeiter von Unternehmen bis 2025 fast ihre gesamte Arbeit mithilfe von Daten optimieren. Schon jetzt liefern die Anwendungen und Plattformen in Ihrem Tech-Stack eine enorme Menge an Daten, die wichtige Geschäftseinblicke erfassen können. Doch bevor Sie Ihre Daten nutzen können, benötigen Sie eine Möglichkeit, deren Eingang und Fluss in Ihrem Unternehmen zu verwalten.
Dies ist das Rückgrat des modernen Unternehmens: die Datenpipeline.
Was ist eine Datenpipeline?
Eine Datenpipeline ist eine Reihe von automatisierten Arbeitsabläufen zum Verschieben von Daten von einem System in ein anderes.
Die Datenpipeline besteht im Wesentlichen aus drei Schritten:
- Datenübernahme von Punkt A (der Quelle).
- Umwandlung oder Verarbeitung.
- Verladung zum Punkt B (dem Zielsee, -lager oder -analysesystem).
Jedes Mal, wenn die Verarbeitung zwischen Punkt A und Punkt B stattfindet, haben Sie eine Datenpipeline zwischen den beiden Punkten erstellt. Wenn die Verarbeitung nach Punkt B stattfindet, haben Sie immer noch eine Datenpipeline erstellt; sie hat nur eine andere Konfiguration.
Datenpipelines konsolidieren die Daten aus isolierten Quellen zu einer einzigen Wahrheitsquelle, die das gesamte Unternehmen nutzen kann, und sind daher für Analysen und Entscheidungsfindung unerlässlich. Ohne eine Pipeline analysieren Teams Daten aus jeder Quelle in einem Silo und können so nicht erkennen, wie die Daten auf einer übergreifenden Ebene zusammenhängen.
Daten-Pipeline vs. ETL vs. ELT
"Datenpipeline" ist ein Oberbegriff, während ETL (Extrahieren, Transformieren, Laden) und ELT (Extrahieren, Laden, Transformieren) Arten von Datenpipelines sind.
ETL-Datenpipelines extrahieren Daten aus der Quelle, wandeln sie durch eine Reihe von Vorgängen um und laden sie in das Ziellager oder -system. Eine Transformation ist eine automatisierte Aktion, die die Daten verändert, bevor sie das Warehouse erreichen. Übliche Transformationen sind:
- Bereinigung und Deduplizierung der Daten.
- Aggregieren verschiedener Datensätze.
- Konvertierung von Daten in ein anderes Format.
- Durchführung von Berechnungen zur Erstellung neuer Daten.
Wenn Sie eine ETL-Pipeline verwenden, besteht Ihr Ziel darin, Ihre Daten zu validieren, zu bereinigen und zu standardisieren, bevor sie in das Warehouse geladen werden.
Wenn Sie die Daten umwandeln , nachdem sie das Lager erreicht haben, verwenden Sie eine ELT-Datenpipeline. Diejenigen, die Cloud-Datenspeicher verwenden, bevorzugen oft ELT, weil sie damit die Lieferung von der Quelle zum Lager beschleunigen und vereinfachen können.
Beispiele für die Datenpipeline-Architektur
Eine einfache ETL-Pipeline sieht wie folgt aus:
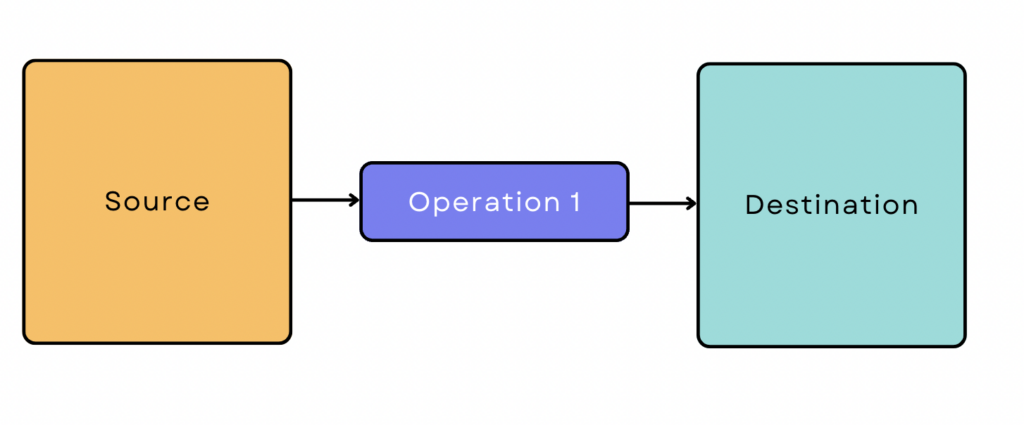
Die meisten Datenpipelines sind jedoch nicht so einfach. Sie umfassen in der Regel viele Quellen und Vorgänge, und die Daten interagieren oft mit anderen Tools und Plattformen auf dem Weg. Manchmal laufen verschiedene Vorgänge parallel, um den Prozess zu beschleunigen.
Zu Beginn der Datenpipeline gibt es zwei Möglichkeiten, Daten aus der Quelle zu übernehmen: Stapelverarbeitung und Echtzeit-/Streaming-Verarbeitung. Manchmal benötigen Sie eine Kombination aus beiden. Diese unterschiedlichen Anforderungen an die Datenübernahme sind die Grundlage für drei gängige Datenpipeline-Konfigurationen.
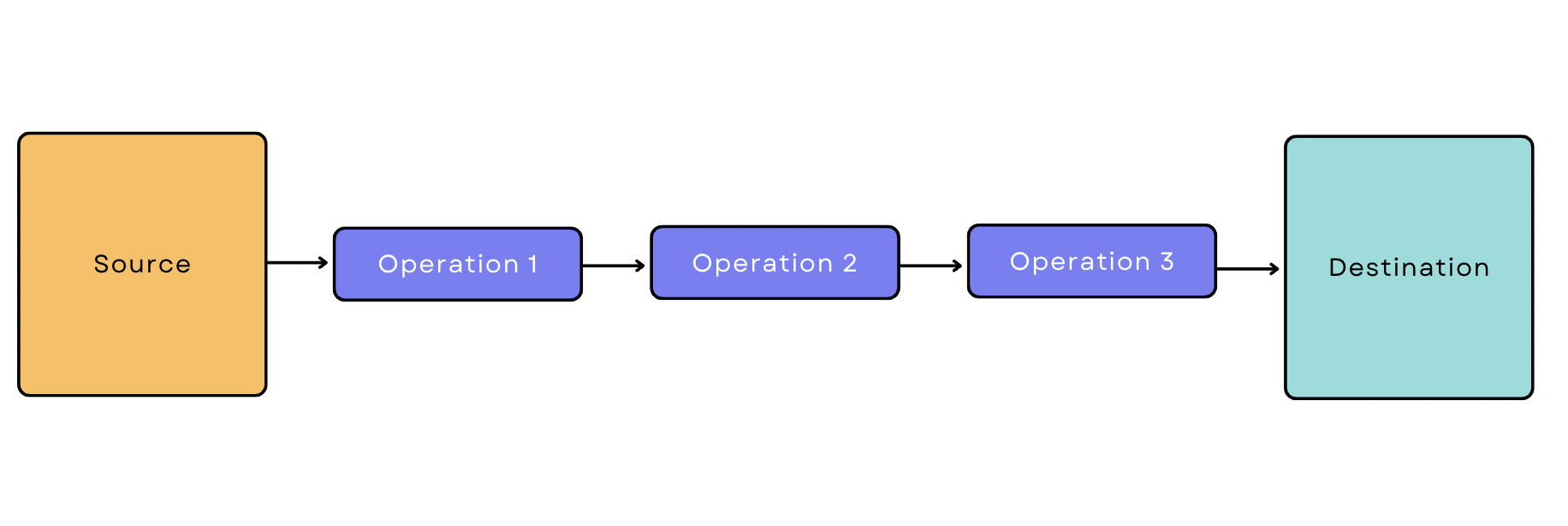
Batch-basierte Datenpipeline
Bei der Batch-Verarbeitung extrahiert das Ingestion-Tool in regelmäßigen Abständen Daten aus der Quelle in Batches. Eine stapelbasierte Datenpipeline ist eine Pipeline, die mit der Stapelverarbeitung beginnt. Nehmen wir an, Sie möchten Transaktionsdaten aus Google Analytics ziehen, drei Transformationen anwenden und sie in das Warehouse laden. Ihre Pipeline würde wie folgt aussehen:
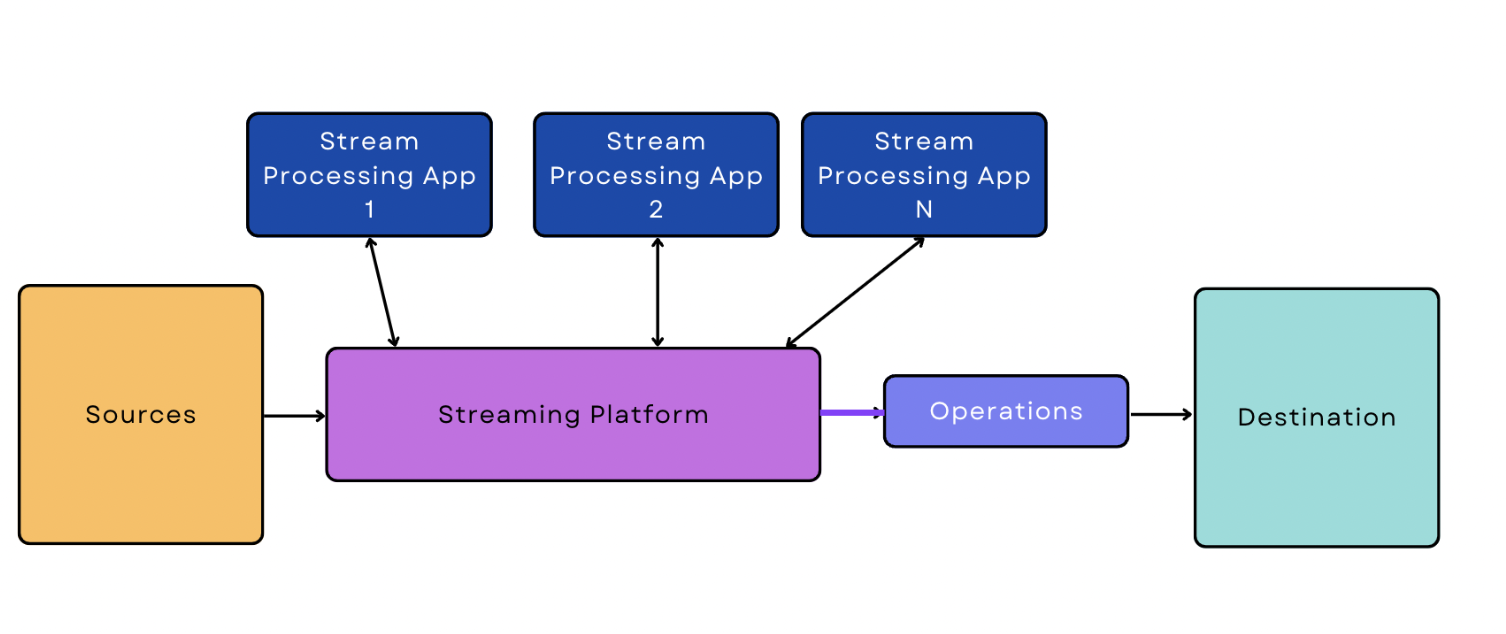
Echtzeit-/Streaming-Datenpipeline
Bei der Echtzeit-/Streaming-Verarbeitung werden die Daten kontinuierlich und in Echtzeit von der Quelle aufgenommen. Eine Streaming-Daten-Pipeline ist eine Pipeline, die mit einer Echtzeit-/Streaming-Datenaufnahme beginnt.
Im Vergleich zur Batch-Ingestion ist die Echtzeit-/Streaming-Ingestion für die Software schwieriger zu handhaben, da sie eingeschaltet sein und ständig überwacht werden muss, um die Daten in Echtzeit zu streamen. Diese zusätzliche Komplexität macht sich auch in der Pipeline selbst bemerkbar. Die einfachste Version einer Streaming-Daten-Pipeline ist etwas komplizierter als die einfachste Version einer Batch-basierten Pipeline.
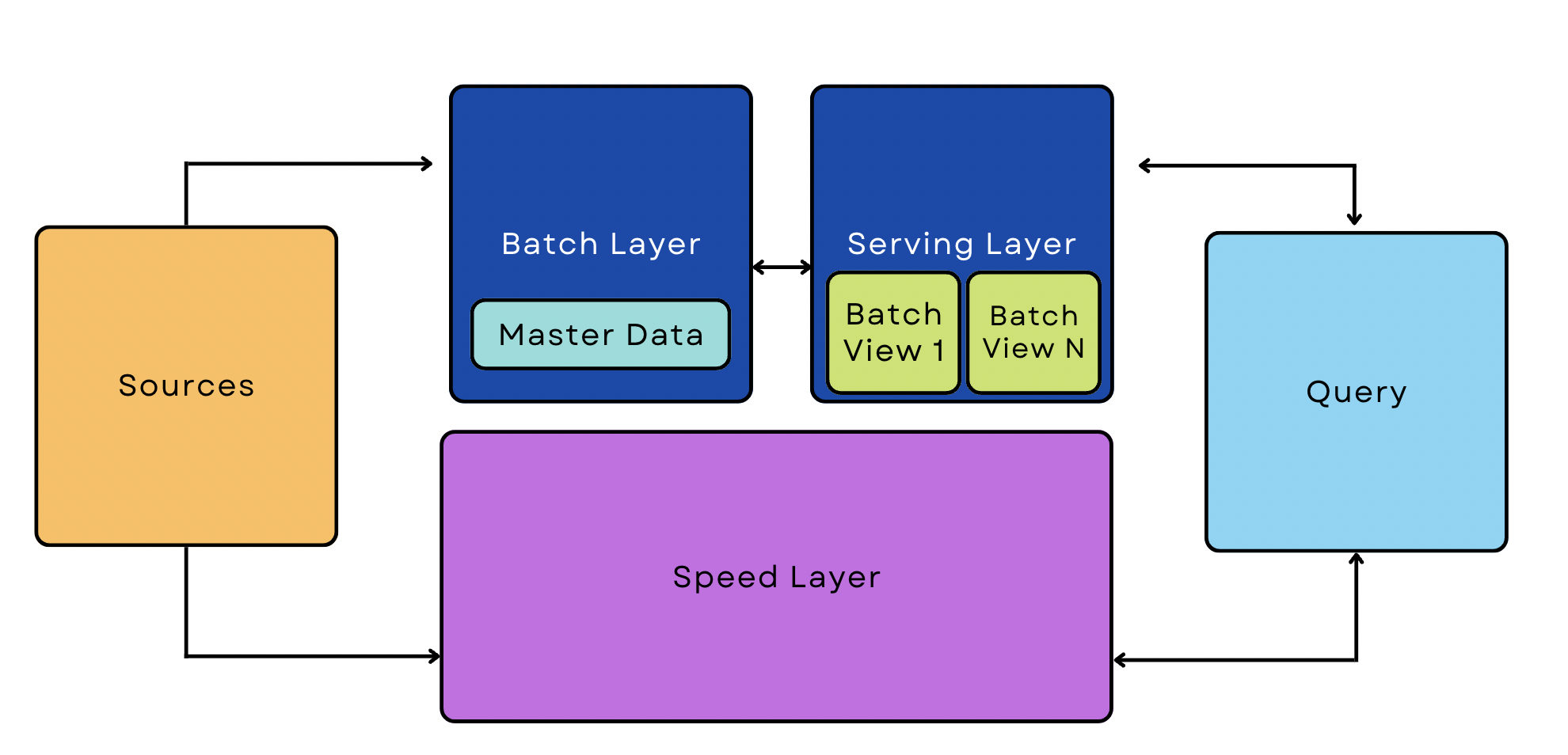
Lambda-Architektur-Pipeline
Eine Lambda-Pipeline kombiniert Batch- und Streaming-Prozesse in derselben Architektur. Diese Pipelines sind ein beliebtes Mittel zur Verwaltung großer Datenmengen, da sie sowohl Streaming- als auch Echtzeitanwendungen unterstützen können.
5 Schritte zum Aufbau einer firmeninternen Datenpipeline von Grund auf
Im Vergleich zur Verwendung von Standardtools ist die Erstellung einer Pipeline von Grund auf ein zeit- und ressourcenintensiver Prozess. In der Regel ist dies nur für Unternehmen sinnvoll, die außergewöhnlich spezielle Anforderungen haben und über umfangreiche technische Ressourcen verfügen. Wenn Ihr Unternehmen diese Kriterien erfüllt, sollten Sie die folgenden Schritte zur Erstellung Ihrer Pipeline in Betracht ziehen.
1. Skizzieren Sie Ihre Ziele und Zwänge
Machen Sie sich zunächst ein genaues Bild davon, was Sie mit der Pipeline erreichen wollen. Möchten Sie Informationen aus einer Datenbank extrahieren und sie mit einer anderen verknüpfen? Müssen Sie Ihre Ergebnisse in einen Online-Speicher einspeisen? Wie viele Quellen werden Sie haben?
Skizzieren Sie insbesondere die folgenden Punkte:
- Quellen - Welche Datenquellen verwenden Sie?
- Art der Dateneingabe - Können die Daten stapelweise verarbeitet werden oder müssen sie kontinuierlich gestreamt werden?
- Ziel - Wohin gehen die Daten?
- Umwandlung - Wie müssen die Daten geändert werden, damit sie in allen Quellen konsistent und für Analysetools nützlich sind? Wann werden diese Änderungen vorgenommen?
- Boxenstopps - Müssen die Daten unterwegs an andere Anwendungen oder Ziele weitergeleitet werden?
2. Erstellen Sie einen übergeordneten Arbeitsablauf
Skizzieren Sie die Hauptkomponenten Ihrer Pipeline mit einer Modellierungssoftware, einer Flussdiagrammsoftware oder sogar mit Stift und Papier. Dieser Schritt hilft Ihnen bei der Visualisierung der verschiedenen Komponenten in Ihrer Architektur und deren Interaktion miteinander.
Lassen Sie sich von den folgenden Fragen leiten, wie Sie Ihre Pipeline aufbauen, und streben Sie den einfachsten Arbeitsablauf an, mit dem die Arbeit erledigt werden kann:
- Gibt es nachgelagerte Abhängigkeiten von vorgelagerten Aufträgen? Wenn Sie beispielsweise Quelldaten aus MySQL-Datenbanken haben, benötigen Sie die Ergebnisse eines ETL-Prozesses, bevor Sie zu einer anderen Stufe übergehen?
- Welche Aufgaben können parallel laufen (wenn überhaupt)?
- Müssen mehrere Tools auf dieselben Daten zugreifen? Welche Art der Synchronisation ist erforderlich?
- Wie ist der Arbeitsablauf bei fehlgeschlagenen Aufträgen? Wer wird benachrichtigt?
- Was passiert, wenn die eingegebenen Daten die Validierung nicht bestehen? Sollen sie automatisch verworfen werden, oder möchten Sie lieber die Fehler diagnostizieren und die Daten erneut in Ihre Pipeline einspeisen?
3. Entwerfen Sie die Kernkomponenten
Wenn Sie Ihre Datenpipeline von Grund auf neu aufbauen, müssen Sie Software zum Abrufen und Umwandeln der Daten schreiben. Dieser Schritt variiert stark von Pipeline zu Pipeline.
Nehmen wir an, Sie möchten Kundendaten aus verschiedenen Systemen wie Ihrem CRM- und Kassensystem konsolidieren. In diesem Anwendungsfall würden Sie Programme schreiben, die die Daten bereinigen und deduplizieren und sie dann auf dieselben Felder (Geschlecht, Datenformat usw.) "normalisieren", damit sie korrekt assimiliert werden. Die konsolidierten Daten könnten dann für personalisierte Benachrichtigungen, Upsells und segmentierte E-Mail-Kampagnen verwendet werden.
4. Skalierung der Pipeline
Führen Sie Benchmark-/Lasttests durch, um mögliche Engpässe und Skalierbarkeitsprobleme zu ermitteln. So können Sie die Ziel- und Spitzenleistung Ihrer Pipeline, die Ziel- und Spitzenlast sowie die akzeptablen Leistungsgrenzen ermitteln.
Wenn die Lasttests Engpässe oder andere Skalierbarkeitsprobleme aufzeigen, sollten Sie nach Möglichkeiten suchen, diese zu beheben.
- Der Lastausgleich verteilt den Netzwerkverkehr auf eine Gruppe von Servern und gleicht so das von den einzelnen Servern zu bewältigende Verkehrsvolumen aus. Diese Lösung ist hilfreich, wenn Sie Millionen von Nutzern bedienen und eine große Anzahl von gleichzeitigen Anfragen bearbeiten müssen.
- Das Sharding von Datenbanken ist eine Form des Lastausgleichs. In diesem Fall wird ein großes Datenvolumen (nicht der Datenverkehr) auf ein Netzwerk von Servern aufgeteilt. Es ist für die gleichen Anwendungsfälle wie der Lastausgleich hilfreich - wenn Sie Millionen von Nutzern haben, arbeiten Sie mit einer enormen Menge an Nutzerdaten.
- Horizontale Skalierung bedeutet, dass Sie Ihrem Pool mehr Rechner hinzufügen (Skalierung nach außen), anstatt die vorhandenen Server mit mehr GPU oder RAM auszustatten (Skalierung nach oben). Eine Skalierung nach unten bietet in der Regel mehr Flexibilität als eine Skalierung nach oben, kann aber auch teurer sein.
- Bei der Zwischenspeicherung werden Kopien einer Datei an einem temporären Speicherort abgelegt, so dass der Zugriff auf sie schneller erfolgen kann. Am vorderen Ende ermöglicht das Caching den Nutzern den schnellstmöglichen Zugriff auf Website-Inhalte und die Suche nach Informationen in Ihrer Datenbank.
5. Implementierung eines Data Governance Frameworks
Zu diesem Zeitpunkt ist Ihre Datenpipeline fertiggestellt. Sie benötigen jedoch einen Plan, wie Sie die Benutzerdaten während der gesamten Pipeline sicher und vorschriftenkonform halten. Identifizieren Sie alle Instanzen sensibler Daten, die Sie aufnehmen und speichern werden - einschließlich personenbezogener Informationen, Kreditkartendaten und aller Daten, die gemäß GDPR oder anderen Vorschriften geschützt sind.
Als Nächstes skizzieren Sie die Maßnahmen, die Sie zum Schutz dieser Daten ergreifen werden. Zu den üblichen Sicherheitsmaßnahmen gehören:
- Daten verschlüsseln.
- Festlegen von erlaubnisbasierten Zugriffskontrollen.
- Führen von detaillierten Protokollen und Aufzeichnungen.
- Überwachung von Daten über Tools von Drittanbietern wie Datadog.
- Aktivierung der Multi-Faktor-Authentifizierung und der Erzwingung von starken Passwörtern auf der Vorderseite zum Schutz vor Sicherheitsverletzungen.
Bauen oder kaufen? Alternativen zum Bau einer Pipeline von Grund auf
Der Aufbau einer Datenpipeline von Grund auf kann kostspielig und schwierig sein, verglichen mit der Verwendung von Standard-Ingestion-Tools mit vorgefertigten Konnektoren. Vorgelagerte Änderungen an der API oder neue Analyseanforderungen können den Umfang eines Projekts in der Mitte des Projekts ändern, was zu ständiger und kontinuierlicher Arbeit führt.
Standard-Ingestion-Tools sparen Zeit und Geld, indem sie wichtige Funktionen automatisieren, ohne dass Sie für jede Aufgabe Software schreiben müssen. Integrationsplattformen wie SnapLogic verfügen über Bibliotheken mit vorgefertigten Konnektoren, mit denen Sie benutzerdefinierte Datenpipelines erstellen können - ganz ohne Programmieraufwand.
Aufbau intelligenter Datenpipelines mit SnapLogic
Verschwenden Sie Ihre technischen Ressourcen nicht damit, das Rad neu zu erfinden. Mit den fachmännisch entwickelten Low-Code/No-Code-Konnektoren von SnapLogic können Sie nahezu sofort leistungsstarke und flexible Datenpipelines erstellen. Mit mehr als 600 Konnektoren zur Auswahl und automatischen Synchronisierungs- und Datenvorbereitungsoptionen lässt sich SnapLogic in Ihren gesamten Tech-Stack integrieren.
Sind Sie bereit zu erfahren, wie viel einfacher es sein kann, Datenpipelines auf Unternehmensebene zu erstellen? Testen Sie noch heute eine Demo.




