





Vor einigen Jahren habe ich einen Artikel mit dem Titel "REST GET and the SnapLogic Public APIs for Pipeline Executions" ( REST GET und die öffentlichen SnapLogic-APIs für Pipeline-Ausführungen) geschrieben, der zeigt, wie man sowohl die öffentlichen SnapLogic-APIs für Informationen zur Pipeline-Laufzeit als auch die Iterationsfunktion von REST GET verwenden kann. Vor ein paar Wochen fragte ein Kollege, ob es ein SnapLogic-Muster für diesen Anwendungsfall gäbe. Ich sagte ihm, dass ich noch nicht dazu gekommen sei (seufz).
Die Frage meines Kollegen hat mich dazu inspiriert, ein SnapLogic-Pattern - eine Vorlage für eine Integrationspipeline - zu erstellen, die die öffentlichen SnapLogic-APIs und REST GET nutzt. Also, los geht's:
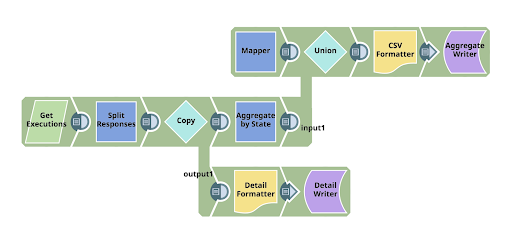
Zusammenfassend lässt sich sagen, dass die Pipeline die öffentlichen SnapLogic-APIs verwendet, um die Zusammenfassung der Ausführungen zu lesen, und dann zwei Dinge mit ihnen macht: Erstens schreibt sie die abgerufenen Zeilendetails in eine Datei, und gleichzeitig schreibt sie auch eine Zusammenfassung in eine Datei, damit Sie sehen können, was die Ausgabe enthält. Auf diesem Weg verwende ich verschiedene Techniken:
- Verwendung der Iterationsfunktion des REST Get Snap, so dass die mehreren iterativen Anfragen, die zum Abrufen der Details von den öffentlichen SnapLogic-APIs erforderlich sind, verbraucht werden.
- Dynamische Konfiguration der mit dem ternären Operator der Ausdruckssprache verwendeten URLs
- Verwendung eines Ausdrucks zur Ermittlung des Org-Namens (zur Verwendung in den URLs)
- Einfügen mehrerer unterschiedlich formatierter Daten in einen einzigen Ausgabestrom, wobei die Reihenfolge eine Rolle spielt
REST Get URL Konfiguration:
Schauen wir uns zunächst an, wie ich die aufzurufende URL definiert habe:
| 'https://elastic.snaplogic.com/api/1/rest/public/runtime/' + pipe.plexPath.split('/')[1] + '?level=summary' + (_state == null || _state =="" ? " : '&state='+ _state) + (_hours == null || _hours =="" ? " : '&last_hours='+ _hours) + (_batchsize == null || _batchsize =="" ? " : '&limit='+ _batchsize) |
Es sieht nach einem etwas komplizierten Ausdruck aus, aber lassen Sie uns das aufschlüsseln:
Die Kern-API befindet sich unter
https://elastic.snaplogic.com/api/1/rest/public/runtime/.
Nachdem wir die Kern-API gefunden haben, müssen wir den Namen der Organisation angeben. Damit der Name dynamisch ist und in jeder Organisation funktionieren kann, habe ich einen Ausdruck verwendet, um die Organisation aus dem einzigen Ort zu extrahieren, den ich im Pfad des verwendeten Snaplex finden konnte. Der Ausdruck:
pipe.plexPath.split('/')[1]
erfasst das erste Element des Snaplex-Pfads, d. h. den Org-Namen.
Der nächste Satz von Ausdrücken darin misst den Zustand der Pipeline-Parameter und konfiguriert die Optionen für die API-Anforderung - den Satz der erforderlichen Zustände, die Anzahl der abzurufenden Stunden und die zu verwendende Stapelgröße. Bedingt können wir entweder: 1) jeden Parameter auf der Grundlage konfigurieren, ob er leer oder null ist (in diesem Fall muss ich keinen Wert übergeben); 2) den konfigurierten Wert übergeben, der von den an die Pipeline übergebenen Parametern übernommen wird; oder 3) die in den Eigenschaften der Pipeline definierten Standardwerte verwenden.
Die "Has Next"-Konfiguration
Mit dem Feld "Has Next" wird entschieden, ob nach dem ersten Abruf weitere Iterationen erforderlich sind, um die gesamte Menge zu erhalten. Ein boolescher Ausdruck sollte dies bestimmen. In diesem Fall liefert SnapLogic in der ersten Antwort auf die Anfrage Daten darüber, was verfügbar ist: die Gesamtzahl der verfügbaren Daten, den Offset und das Limit (das Limit entspricht der Anzahl im Stapel). Ich überprüfe dann die Summe aus dem, was ich bereits habe, und der verfügbaren Anzahl und erhalte ein boolesches Ergebnis.
| $entity.response_map.offset + $entity.response_map.limit < $entity.response_map.total |
Die "Nächste URL"
Diese URL könnte ähnlich wie die erste sein, aber wir müssen ihr zusätzlich mitteilen, wo sie mit dem Abruf beginnen soll (im nachstehenden Code hervorgehoben):
| 'https://elastic.snaplogic.com/api/1/rest/public/runtime/' + pipe.plexPath.split('/')[1] + '?level=summary' + (_state == null || _state =="" ? " : '&state='+ _state) + (_hours == null || _hours =="" ? " : '&last_hours='+ _hours) + '&offset=' + ($entity.response_map.offset+$entity.response_map.limit) + (_batchsize == null || _batchsize =="" ? " : '&limit='+ _batchsize) |
Mehrere Daten in unterschiedlichen Formaten in einen einzigen Ausgabestrom einfügen, wobei die Reihenfolge berücksichtigt werden muss
Die andere Technik, die ich in dieser Pipeline verwendete, war ein Konstrukt, das es mir ermöglichte, die zusammenfassende Ausgabedatei mit zwei Datenströmen zu schreiben. Diese Technik ermöglichte es mir, die Daten so in die Datei zu bekommen, wie ich es wollte.
Zunächst habe ich den Mapper Snap, der bei der Pipeline-Ausführung nicht auf eine Eingabe wartet und daher sofort ein einzelnes Dokument ausgibt. Ich habe einen Ausdruck erstellt, um die Ausführungsparameter zu erfassen und sie in eine Zeichenfolge zu formatieren:
| “Execution statistics for State: ” + ( _state == null || _state ==”” ? ‘UnSpecified/all’ : _state) + “, Hours: ” + ( _hours == null || _hours ==”” ? ‘UnSpecified/1 Hr’ : _hours) + “, batchsize:” + ( _batchsize == null || _batchsize ==”” ? ‘UnSpecified/10’ : _batchsize) + ” at ” + Date.now().toLocaleDateTimeString(‘{“format”:”yyyy-MM-dd HH:mm:ss”}’) |
Auch hier habe ich versucht, die Daten in ein vernünftiges Format zu bringen, so dass Sie bei der Anzeige mit dem Feldbetrachter die Ergebnisse und die Konfiguration, die zu diesem Ergebnis geführt hat, leicht erkennen können.
Die Ausgabe des Mappers ist höchstwahrscheinlich das erste Dokument im nachfolgenden Union Snap, so dass es immer der erste Teil des Datenstroms ist, der in die Ausgabedatei geschrieben wird.
Wenn der REST-GET seine Arbeit getan hat, aggregiert der Aggregate-Snap die Anzahl der Ausführungen in jedem Zustand, die wir dann in die Datei übertragen.
Das Ergebnis ist die unten gezeigte Zusammenfassung, die in der Vorschau des File Writers angezeigt wird:
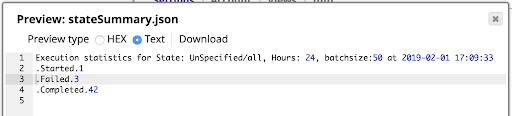
Vergessen Sie nicht, dass der REST GET Snap ein REST Basic Auth-Konto mit gültigen Anmeldeinformationen benötigt, um die Anfrage an die Plattform zu stellen. Das Ergebnis enthält nur die Ergebnisse für die Ausführungen, für die diese Anmeldeinformationen die Berechtigung haben, sie zu sehen. Verwenden Sie ein Konto vom Typ Admin, wenn Sie alle Ausführungen in einer Organisation sehen möchten.
Wenn Sie die in diesem Blogbeitrag vorgestellte SnapLogic-Pipeline ausprobieren möchten, können Sie sie in der SnapLogic Community herunterladen.





