





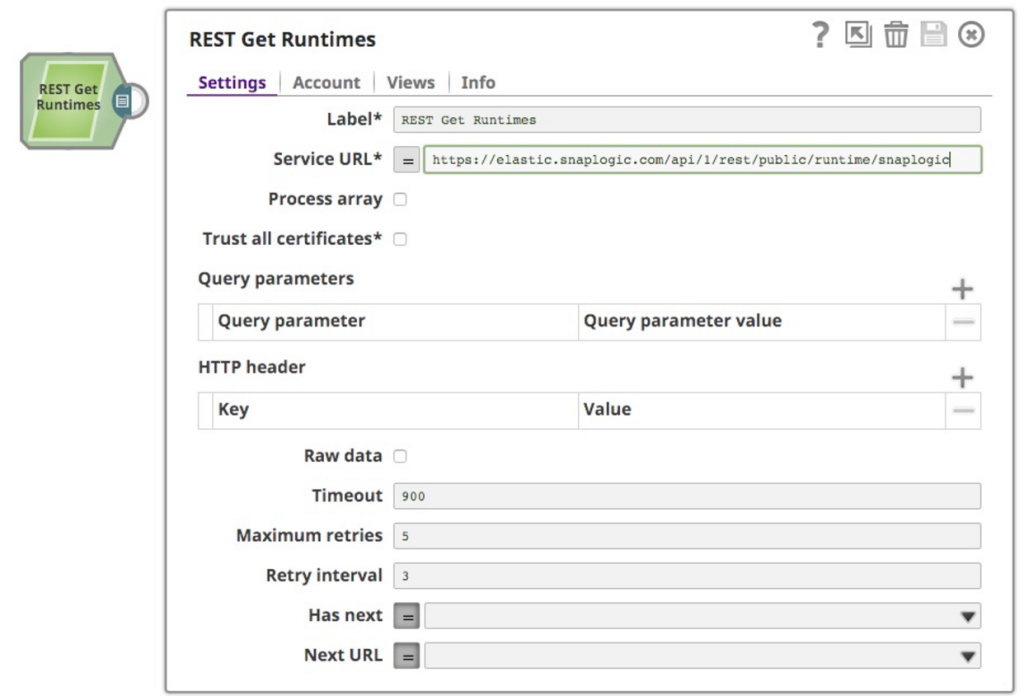
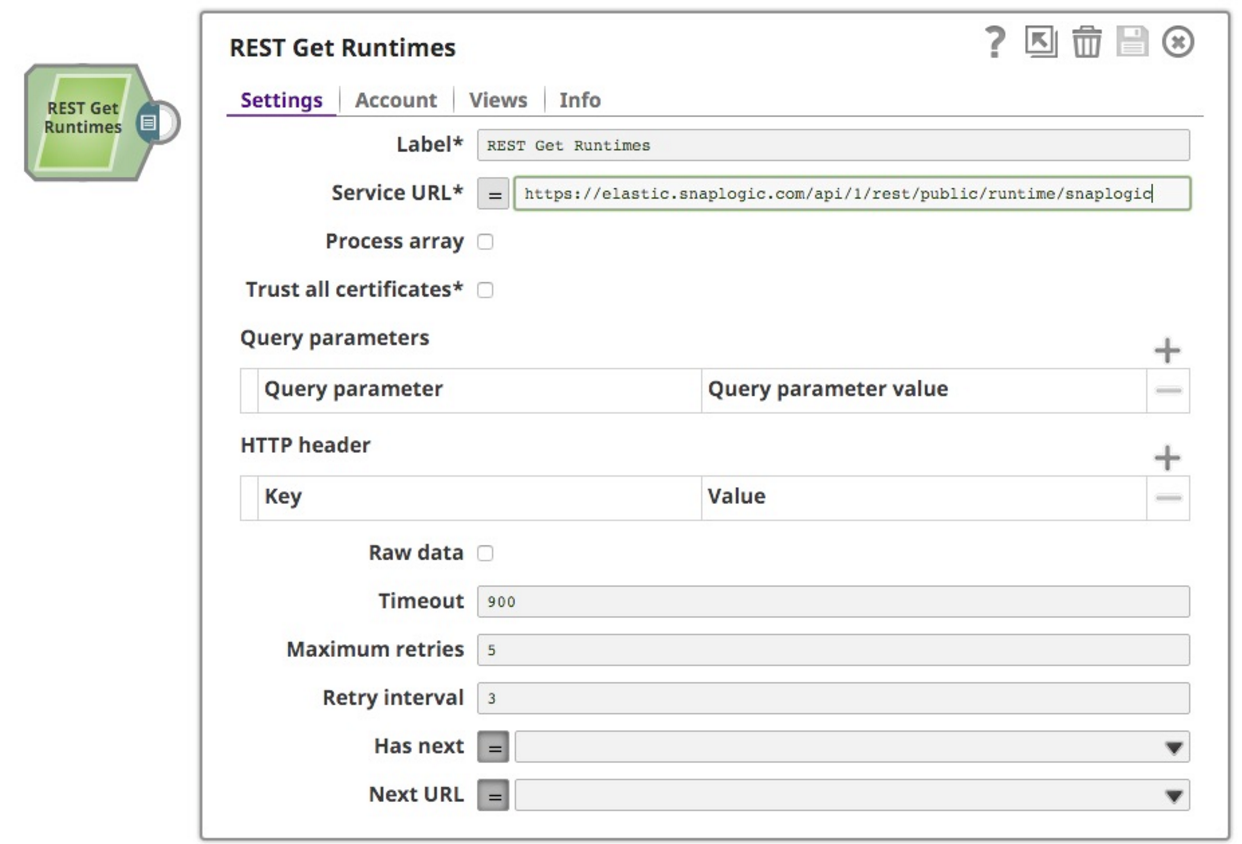
Im Rahmen eines umfassenderen Analyseprojekts, an dem ich arbeite, um Laufzeitinformationen der SnapLogic-Plattform zu analysieren, habe ich mich für die Nutzung der allen Kunden zur Verfügung stehenden Funktionen entschieden: die Public API for Pipeline Monitoring API und die REST API. Diese beiden Dinge werden in diesem Beitrag kombiniert. Zunächst habe ich natürlich die Dokumentation gelesen, in der das Format der Anfrage und der Antwort angegeben ist. Also habe ich eine neue Pipeline erstellt und einen REST GET Snap auf der Leinwand abgelegt:
Ich wollte die Laufzeitdaten aus der Snaplogic-Org auf der SnapLogic-Plattform abrufen, also habe ich in der URL snaplogic als Org angegeben. Außerdem ist zu beachten, dass die API eine Authentifizierung erfordert, also habe ich ein einfaches Authentifizierungskonto mit meinen Anmeldedaten erstellt. Das funktioniert gut und liefert mir die gewünschten Informationen, wie folgt:
[
{
"headers": {
"x-frame-options": "DENY",
"connection": "keep-alive",
"x-sl-userid": "[email protected]",
"access-control-max-age": "17600",
"content-type": "application/json",
"date": "Sun, 31 Jan 2016 01: 29: 59 GMT",
"access-control-allow-credentials": "true",
"access-control-allow-methods": "GET, POST, OPTIONS, PUT, DELETE",
"x-sl-statuscode": "200",
"content-length": "5175",
"content-security-policy": "frame-ancestors 'none'",
"access-control-allow-origin": "*",
"server": "nginx/1.6.2",
"access-control-allow-headers": "authorization, x-date, content-type, if-none-match"
},
"statusLine": {
"reasonPhrase": "OK",
"statusCode": 200,
"protoVersion": "HTTP/1.1"
},
"entity": {
"response_map": {
"entries": [
{
"pipe_id": "1b10f684-24c0-4002-abd3-09b2e87e975f",
"ccid": "56ab61ed63766e7406c491ba",
"runtime_path_id": "snaplogic/rt/cloud/dev",
"subpipes": { },
"state_timestamp": "2016-01-31T01: 29: 43.758000+00: 00",
"parent_ruuid": null,
"create_time": "2016-01-31T01: 29: 43.484000+00: 00",
"id": "0aa7943d-d6c3-408c-9490-1d2b6b281227",
"runtime_label": "cloud-dev",
"cc_label": "prodxl-jcc1",
"documents": 9,
"user_id": "[email protected]",
"label": "REPORT - NGM FSM Ultra Task Failure Audit",
"state": "Completed",
"invoker": "scheduled"
},
...another 9 of these...
],
"total": 154,
"limit": 10,
"offset": 0
},
"http_status_code": 200
}
}
]Beachten Sie den kleinen Abschnitt am Ende mit der Summe, dem Limit und dem Offset, der anzeigt, dass ich nur die ersten 10 verfügbaren Laufzeiten abgerufen habe. Das Abrufen weiterer Laufzeiten erfordert die "Paginierung", die dem REST-GET-Snap letztes Jahr hinzugefügt wurde (in der Dokumentation finden Sie Beispiele für die Verwendung der Paginierung mit Eloqua, Marketo und HubSpot). Die beiden Felder in der Infobox für den Snap sind "Has Next", ein Boolescher Wert, der angibt, ob eine weitere Iteration durchgeführt werden muss, und "Next URL", beides Ausdrücke, so dass die Bedingung dynamisch sein kann.
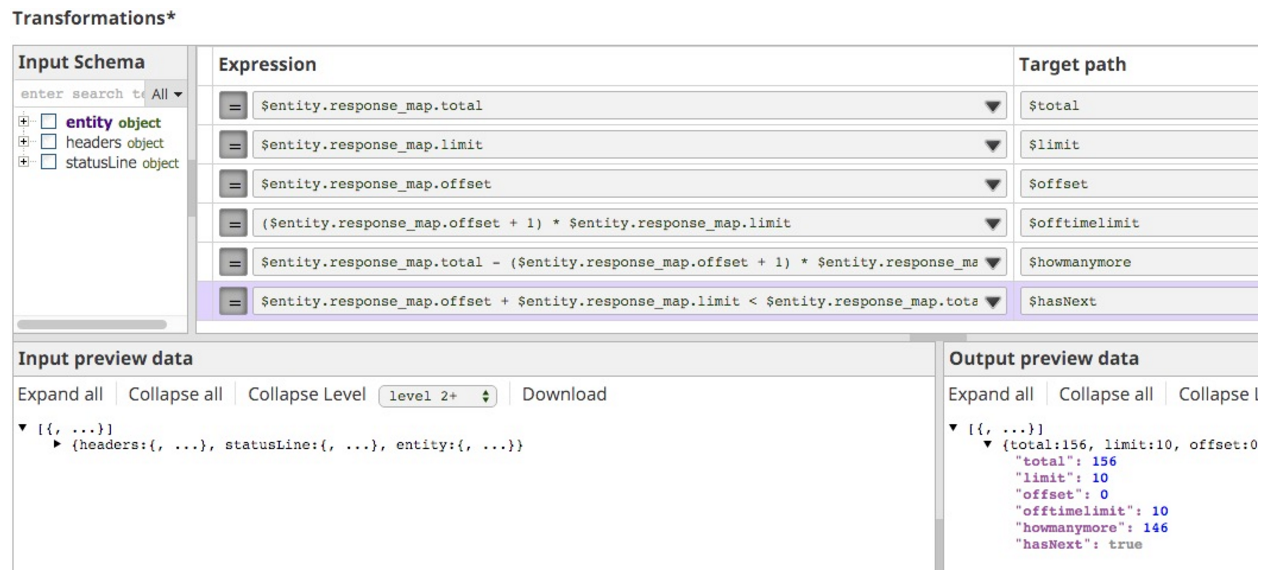
Im Fall meiner SnapLogic-Laufzeit-API musste ich aus diesen drei Feldern (Total, Limit, Offset) herausfinden, wie ich angeben konnte, ob und was die nächste URL sein würde. Um meine Logik auszuarbeiten, habe ich also einen Mapper-Snap als nächstes in die Pipeline eingefügt, damit ich iterieren konnte, bis ich die richtigen Ausdrücke hatte.
Um Ihnen eine Vorstellung davon zu geben, wie ich vorgegangen bin, sehen Sie hier den Status meines Mappers:
Das Wichtigste hier ist der Ausdruck, den ich verwendet habe, um anzuzeigen, ob es noch mehr zu holen gibt, hasNext:
$entity.response_map.offset + $entity.response_map.limit < $entity.response_map.total
Dies kann ich nun auf den REST-GET-Snap anwenden, aber zuerst sollte ich herausfinden, wie ich die Next-URL erstellen kann. Die Next-URL ist die gleiche wie die Service-URL, aber ich füge einfach "?offset=n" hinzu, wobei n die Zahl ist, die ich bereits abgeholt habe, minus eins, da wir in echter CS-Manier immer mit 0 beginnen! Meine URL ist also letztlich der Ausdruck:
'https://elastic.snaplogic.com/api/1/rest/public/runtime/snaplogic?offset=' + ($entity.response_map.offset+$entity.response_map.limit)
Sie müssen darauf achten, dass Sie beide Felder auf den Ausdrucksmodus umschalten.
Dies können wir testen, um sicherzustellen, dass der vollständige Datensatz abgerufen wird. Wenn ich diese Zeit speichere, sieht die Vorschau auf den REST-GET wie folgt aus:
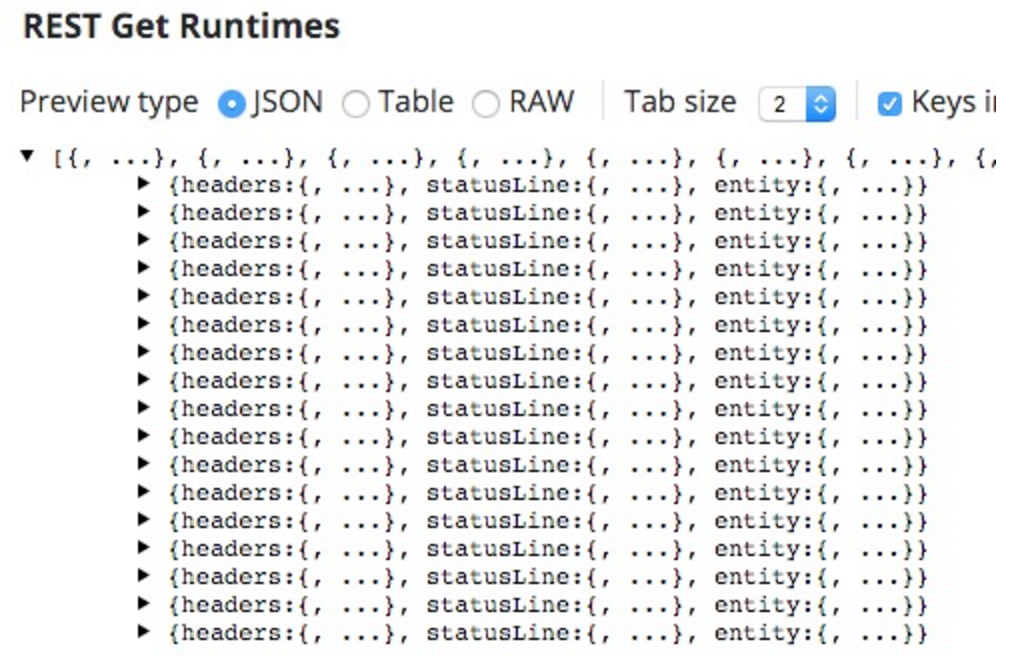
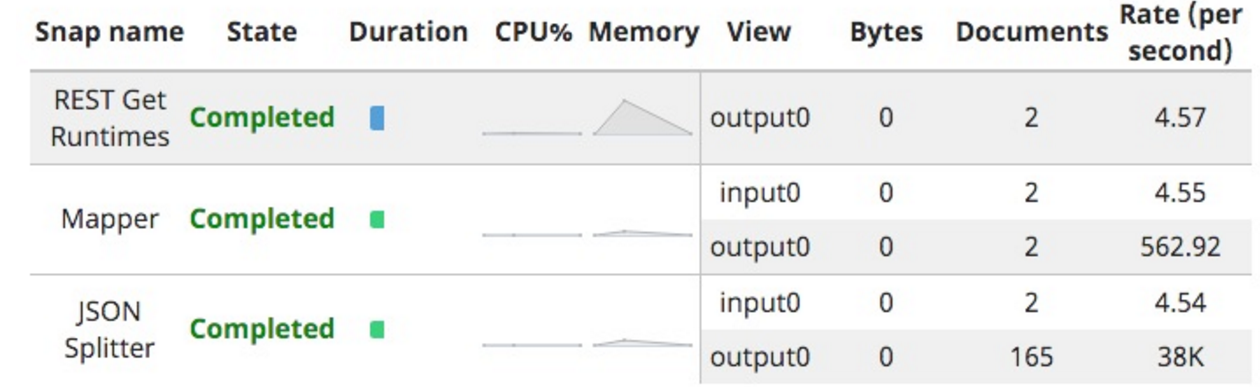
Als ich dies durchführte, war die Anzahl der Laufzeiten wie folgt:

Daraus ergeben sich die siebzehn Iterationen.

Darin liegt ein weiteres Problem; es kommt als siebzehn Dokumente, eine für jede Iteration gesetzt, aber mit bis zu 10 (die Standard-Limit-Größe) Laufzeiten pro Iteration.
Dies veranlasst mich zu einem JSON Splitter Snap, um es zu erweitern setzen:
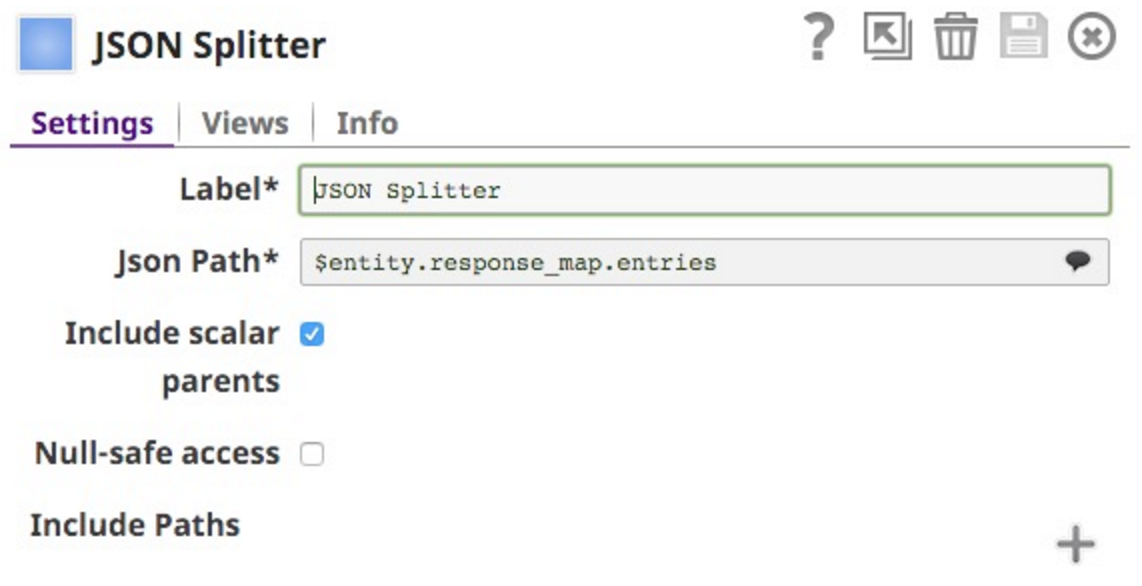
Beachten Sie, dass ich die $entity.response_mpa.entries als JSONPath zum Aufteilen ausgewählt habe. Dies ist aus dem Dropdown-Menü auswählbar (beachten Sie, dass ich das untere Ende der Liste abgeschnitten habe, es geht für alle Schlüssel im Dokument weiter:
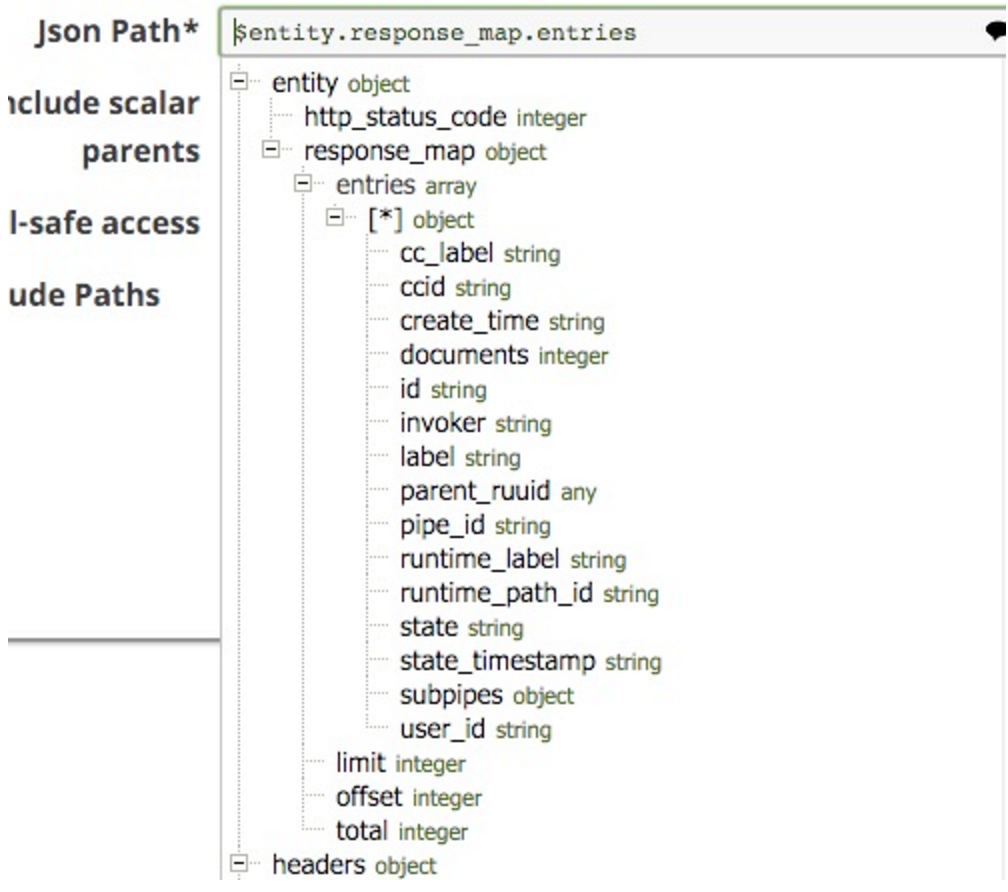
Ich habe auch den Skalar Parent aufgenommen, so dass jedes Dokument die direkten Eltern enthält:
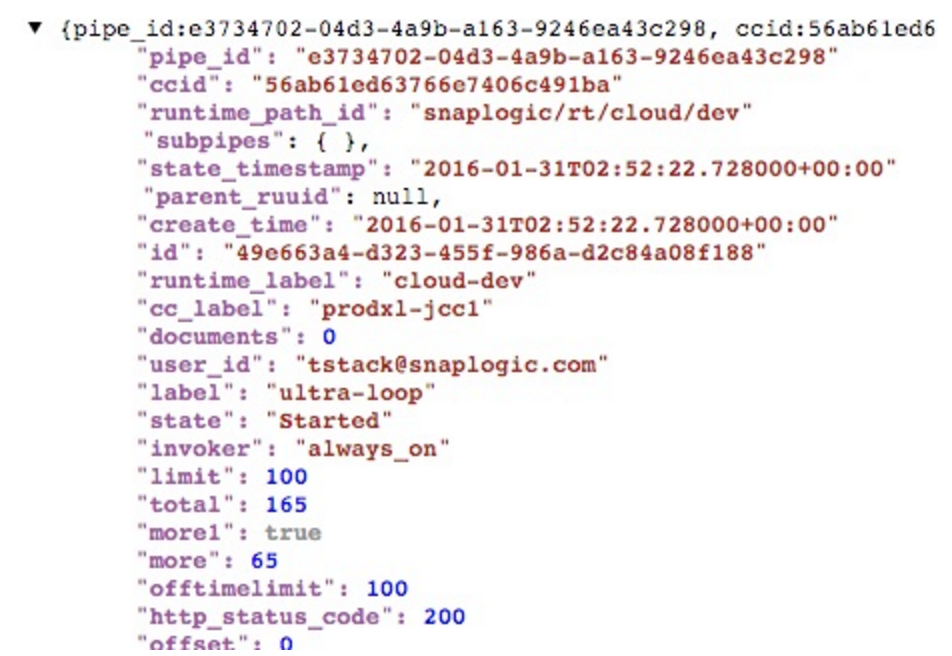
Bei der Ausführung erhalte ich nun die gesamte Anzahl der Pipeline-Laufzeiten, jeweils als separate Dokumente:
Hinweis: Sie werden feststellen, dass die Anzahl der Laufzeiten in der Anfrage in diesem Artikel variiert, da in der Zeit, in der ich den Artikel geschrieben habe, unterschiedliche Daten zur Verfügung standen. Sie können die Optionen der API nutzen, um den Zeitraum der Abfrage genau festzulegen.
Nächste Schritte:
- Lesen Sie ähnliche Beiträge von meinem Kollegen Robin Howlett
- Lesen Sie die Beiträge von Greg Benson über die Architektur der SnapLogic Elastic Integration Platform
- Sehen Sie sich unsere Videos an, um SnapLogic in Aktion zu erleben, oder fordern Sie eine individuelle Demo an






{kind=link}