






Snowpark ist eine Reihe von Bibliotheken und Laufzeiten in der Snowflake-Cloud-Datenplattform, die es Entwicklern ermöglichen, Python-, Java- oder Scala-Code, der nicht von SQL stammt, ohne Datenbewegungen in der elastischen Verarbeitungsmaschine von Snowflake sicher zu verarbeiten.
Dies ermöglicht die Abfrage und Verarbeitung von Daten in großem Umfang in Snowflake. Die Operationen von Snowpark können passiv auf dem Server ausgeführt werden, was die Verwaltungskosten senkt und eine zuverlässige Leistung gewährleistet.
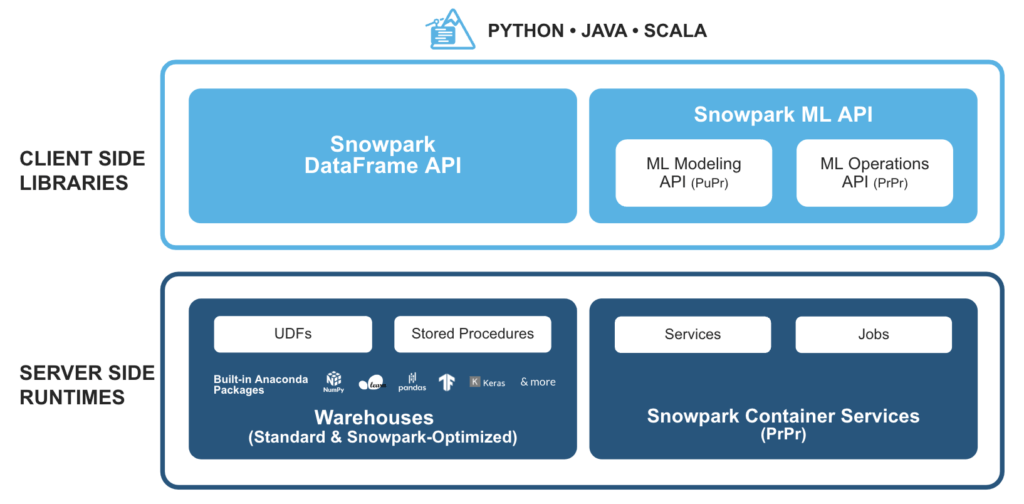
Wie funktioniert Snowpark mit SnapLogic?
Die Intelligent Integration Platform (IIP) von SnapLogic bietet eine einfache Möglichkeit, von Entwicklern erstellte, benutzerdefinierte Funktionen (UDFs) für Snowpark zu nutzen. Darüber hinaus wird das Snowflake Snap Pack verwendet, um fortschrittliches maschinelles Lernen und Data-Engineering-Anwendungsfälle mit Snowflake zu implementieren.
Beispiel für die Integration von Snowpark und SnapLogic
Im Folgenden werden die Schritte zum Aufrufen von Snowpark-Bibliotheken mit dem Remote Python Script Snap in SnapLogic erläutert:
Schritt 1: Lesen von Beispielzeilen aus einer Quelle (in diesem Fall ein CSV-Generator)
Schritt 2: Verwenden Sie den Remote Python Script Snap, um:
- Aufrufen der Snowpark-Python-Bibliotheken
- Zusätzliche Operationen mit den Quelldatenzeilen durchführen
Schritt 3: Laden der verarbeiteten Daten in eine Snowflake-Zieltabelle
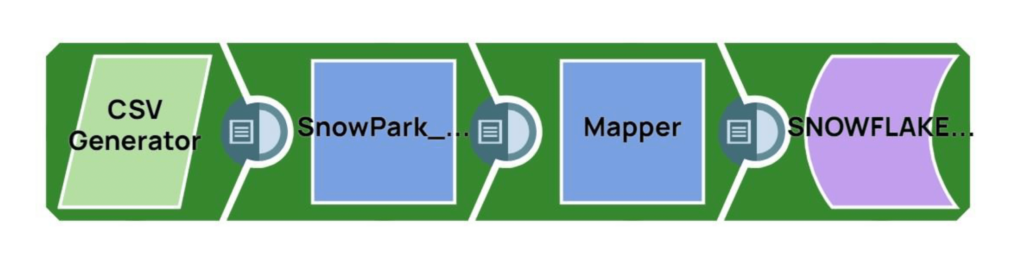
SnapLogic IIP-Konfigurationen
Auf der SnapLogic-Seite muss der Remote Python Executor (RPE) mit Hilfe der folgenden Schritte installiert werden:
Schritte 1 und 2: Die ersten beiden Schritte zur Installation des RPE werden in der SnapLogic IIP-Dokumentation ausführlich erläutert. Der standardmäßige RPE-Zugangsport ist 5301, sodass die "eingehende Kommunikation" an diesem Port aktiviert werden muss.
- Wenn die Snaplex-Instanz ein Groundplex ist, kann das RPE als derselbe Snaplex-Knoten installiert werden
- Wenn es sich bei der Snaplex-Instanz um einen Cloudplex handelt, kann das RPE wie jeder andere Remote-Knoten installiert werden, auf den der Snaplex zugreift
Schritt 3 : Im nächsten Schritt müssen Sie das benutzerdefinierte RPE-Paket installieren, indem Sie die Schritte im Abschnitt "Benutzerdefiniertes Image" der Dokumentation ausführen. Um die Snowpark-Bibliotheken auf dem Knoten zu installieren, aktualisieren Sie die Datei requirements.txt wie folgt:
Anforderungen.txtsnaplogicnumpy==1.22.1snowflake-snowpark-pythonsnowflake-snowpark-python[pandas]
Die Snaplex-Instanz in unserem Beispiel ist ein Cloudplex, und der entfernte Knoten ist eine Azure Ubuntu VM. Das benutzerdefinierte RPE-Paket wird auf der Azure-VM installiert.
Schneeflocken-Konfigurationen
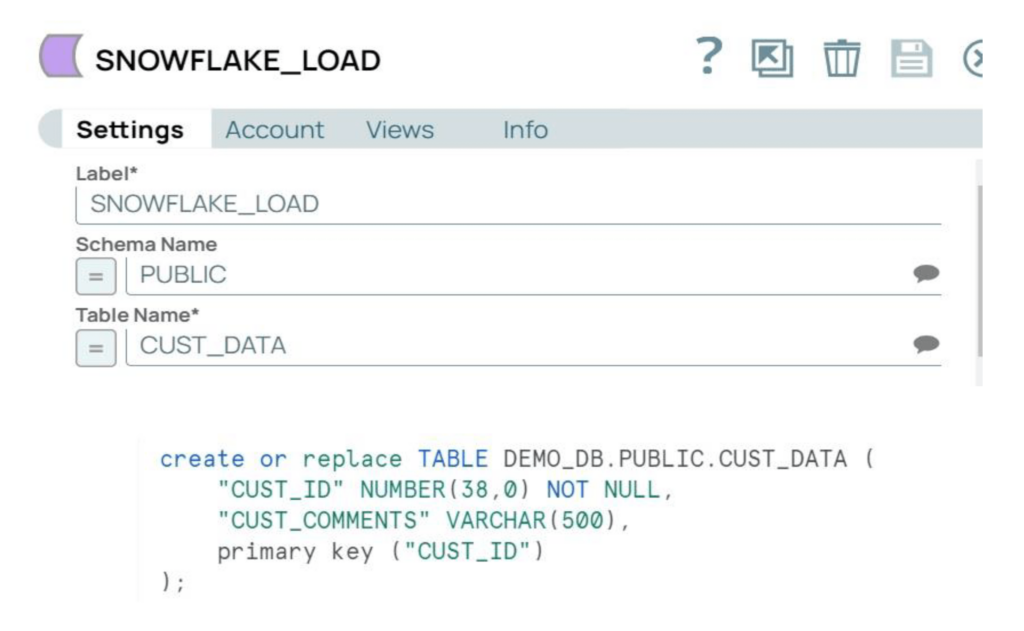
Auf der Snowflake-Seite müssen wir Konfigurationen festlegen und eine Zieltabelle erstellen.
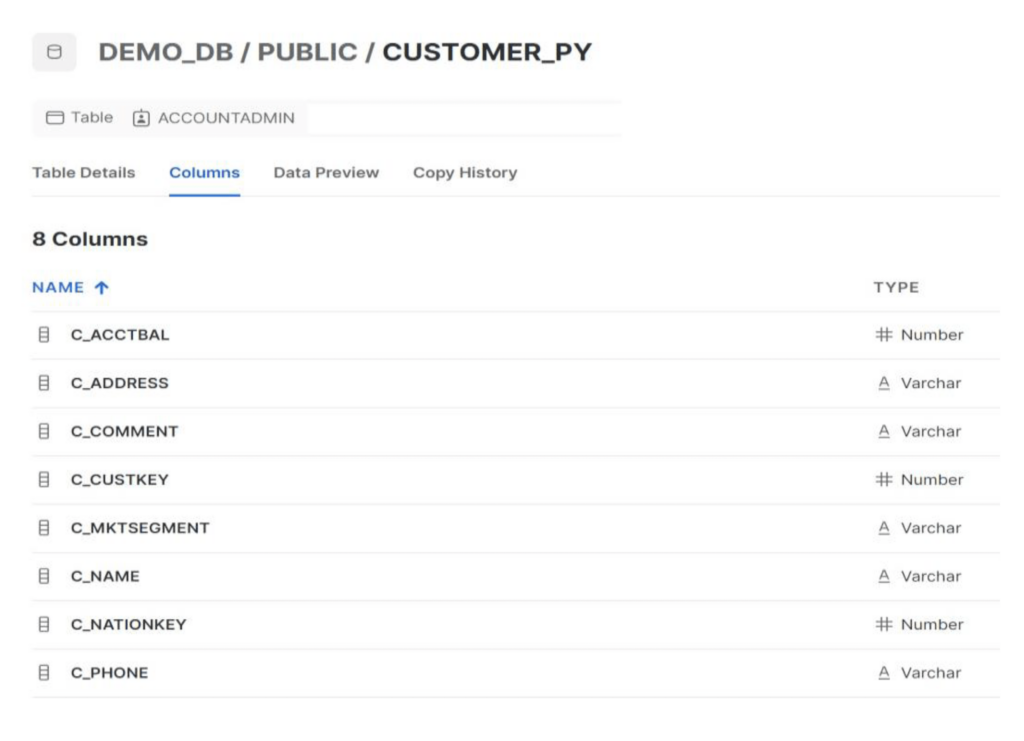
Schritt 1: Aktualisieren Sie die Snowflake-"Netzwerkrichtlinien", um die SnapLogic- und RPE-Knoten zuzulassen. Für dieses Beispiel verwenden wir die Tabelle CUSTOMER_PY unter dem Schema Public.
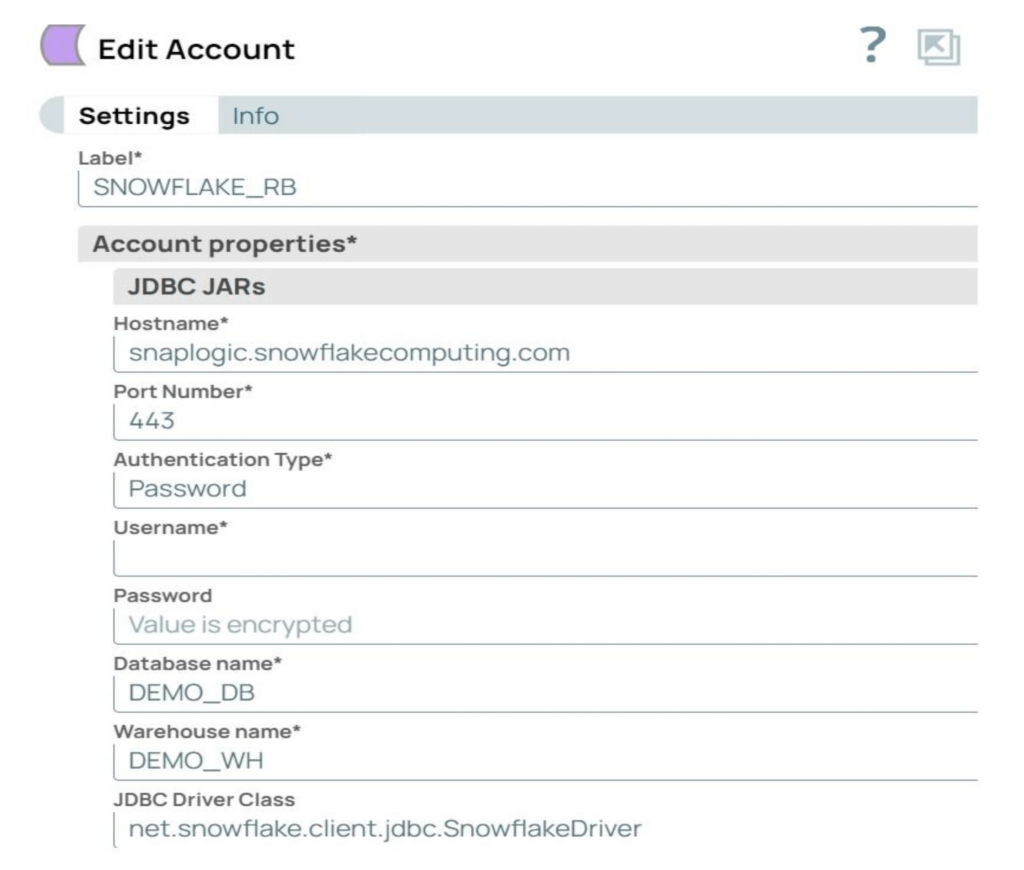
Schritt 2: Erstellen Sie das Snowflake-Konto in SnapLogic mit den erforderlichen Parametern. Das in unserem Beispiel verwendete Konto ist ein Snowflake S3-Datenbankkonto.
SnapLogic Pipeline-Ablauf (Remote_Python_Snowpark_Sample)
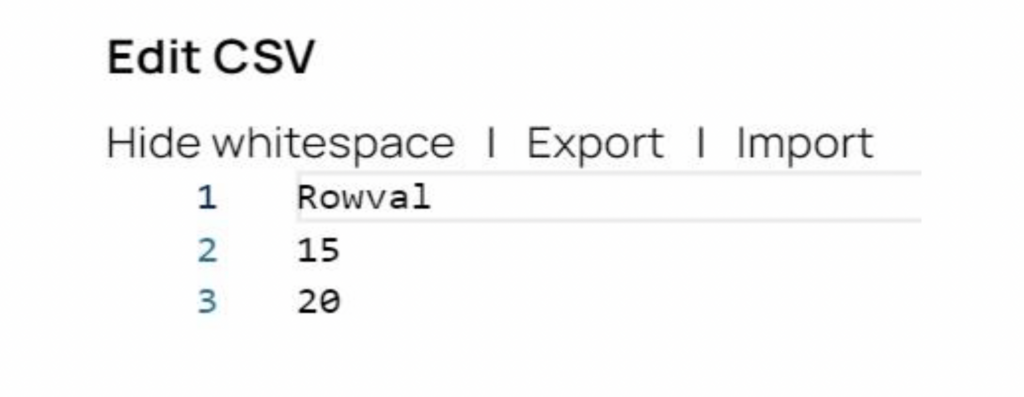
Schritt 1: Der CSV Generator Snap generiert die Quelldaten. In unserem Beispiel gibt es zwei Quelldatensätze mit den Werten 15 und 20.
Schritt 2: Das Remote-Python-Skript Snapführt Python-Code aus, um die Snowpark-Python-Bibliotheken aufzurufen und zusätzliche Operationen mit den Quelldatenzeilen durchzuführen. Nachfolgend sehen Sie einen Ausschnitt des Python-Codes:

Der Python-Code führt die folgenden Operationen durch:
- Konstruieren Sie Snowpark DataFrames, um Daten aus den Snowflake-Tabellen abzurufen. Datensätze filtern, um Daten für den C_NATIONKEY und die zugehörigen Daten der Spalte C_COMMENT für jede Eingabezeile aus dem Upstream-Snap (vom CSV-Generator) abzurufen
- Erstellen Sie eine UDF und führen Sie sie aus, um den aktuellen Zeitstempel an die Bezugsdatensätze in der Spalte C_COMMENT anzuhängen. Der Name der Beispiel-UDF lautet append_data.
- Rückgabe der Werte von C_NATIONKEY und der aktualisierten C_COMMENT-Datensätze an den nachgeschalteten Mapper Snap.
Schritt 3: Validieren Sie die SnapLogic-Pipeline und beheben Sie alle Validierungsfehler.
Schritt 4: Führen Sie die Pipeline aus und überprüfen Sie die Daten in der Zieldatenbank auf Snowflake.
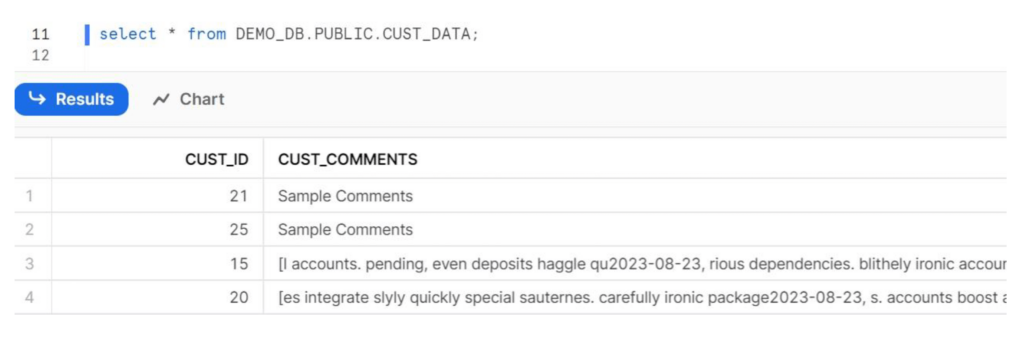
Schritt 5: Herzlichen Glückwunsch, Sie haben Snowpark und SnapLogic erfolgreich integriert!
Zusätzliche Referenzen
Snowpark API-Dokumentation
Snowpark-Entwicklerhandbuch für Python
SnapLogic Remote Python Script Snap Dokumentation
SnapLogic Pipeline-Export
Python-Code für das Remote Python Script Snap







