





Nel mio post precedente ho descritto i vari approcci e modelli da considerare quando si ingeriscono dati da fonti di dati relazionali in un data lake hive basato su Hadoop. In questo post descriverò un approccio pratico su come utilizzare questi pattern con SnapLogic Elastic Integration Platform senza dover scrivere codice. I modelli di livello di ingestione dei big data qui descritti tengono conto di tutte le considerazioni di progettazione e delle best practice per un'efficace ingestione dei dati nel data lake hive di Hadoop. Questi pattern vengono utilizzati da molte organizzazioni aziendali per spostare grandi quantità di dati, in particolare quando accelerano le loro iniziative di trasformazione digitale e si impegnano a comprendere le esigenze dei clienti.
Consideriamo uno scenario in cui si vogliono inserire in Hive i dati di un database relazionale (come Oracle, mySQl, SQl Server, ecc.). Supponiamo di voler usare AVRO come formato di dati per le tabelle di Hive. Vediamo ora come questo schema consente di generare automaticamente tutti gli schemi AVRO necessari e le tabelle Hive.
Le fasi principali associate a questo schema sono le seguenti:
- Offrire la possibilità di selezionare un tipo di database come Oracle, mySQl, SQlServer, ecc. Quindi configurare le informazioni di connessione al database (come nome utente, password, host, porta, nome del database, ecc.)
- Consente di selezionare una tabella, un insieme di tabelle o tutte le tabelle del database di origine. Ad esempio, vogliamo spostare tutte le tabelle che iniziano con o contengono "ordini" nel nome della tabella.
- Per ogni tabella selezionata dal database relazionale di origine:
- Interrogare i metadati del database relazionale di origine per ottenere informazioni sulle colonne delle tabelle, sui tipi di dati delle colonne, sull'ordine delle colonne e sulle chiavi primarie/privilegiate.
- Generare lo schema AVRO per una tabella. Gestisce automaticamente tutte le mappature e le trasformazioni richieste per la colonna (nomi delle colonne, chiavi primarie e tipi di dati) e genera lo schema AVRO.
- Generare il DDL necessario per la tabella Hive. Gestisce automaticamente tutte le mappature e le trasformazioni richieste per le colonne e genera il DDL per la tabella Hive equivalente.
- Salvare gli schemi AVRO e il DDL di Hive in HDFS e in altri repository di destinazione.
- Creare la tabella Hive utilizzando il DDL
Il modello SnapLogic per generare automaticamente lo schema e il DDL di Hive è riportato di seguito. Può essere utilizzato come parte della pipeline del flusso di dati Ingest per spostare i dati da un'origine dati di relazione a Hive.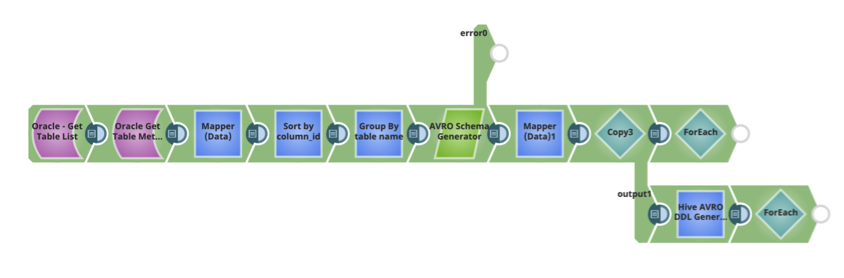
Per ogni tabella, anche gli schemi Avro e i DDL delle tabelle Hive sono memorizzati in HDFS. 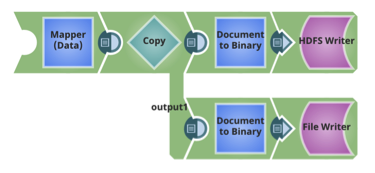
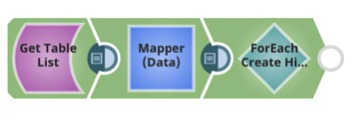
Per ogni tabella, creare la tabella Hive, utilizzando il DDL Hive e lo schema AVRO.
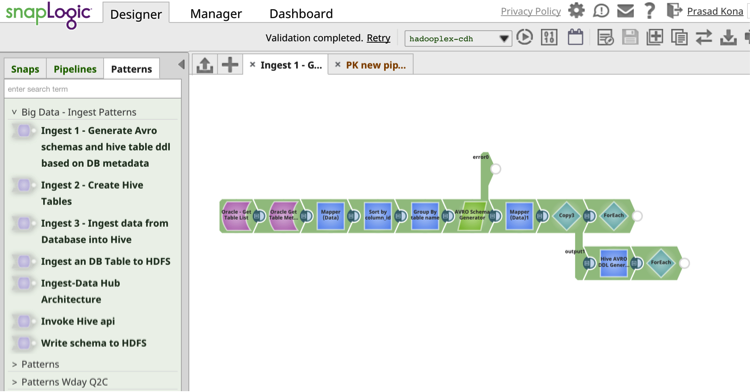
 Il Modelli di integrazione SnapLogic Il catalogo fornisce pipeline di flussi di dati di integrazione precostituiti e riutilizzabili che consentono la riusabilità e migliorano la produttività.
Il Modelli di integrazione SnapLogic Il catalogo fornisce pipeline di flussi di dati di integrazione precostituiti e riutilizzabili che consentono la riusabilità e migliorano la produttività.
Nel mio prossimo post scriverò di un altro modello pratico di integrazione dei dati per l'ingestione di big data con SnapLogic senza la necessità di eseguire alcuna codifica.
Le prossime tappe:
- Scarica il whitepaper: Come costruire un Data Lake aziendale: Considerazioni importanti prima di iniziare. È inoltre possibile guardare la registrazione del webinar e consultare le diapositive sul blog di SnapLogic.
- Scaricate il whitepaper: Il Data Lake affogherà il Data Warehouse?
- Guardate questa dimostrazione di SnapReduce e SnapLogic Hadooplex per conoscere il nostro approccio "Hadoop for Humans" all'integrazione dei big data.




