






![]()
Nel mondo degli affari di oggi i big data stanno generando un grande fermento. Oltre alla ricerca, all'archiviazione e alla scalabilità, una cosa che spicca chiaramente è l'elaborazione dei flussi. È qui che entra in gioco Apache Kafka.
Kafka ad alto livello può essere descritto come un sistema di messaggistica publish and subscribe. Come qualsiasi altro sistema di messaggistica, Kafka mantiene i flussi di messaggi in argomenti. I produttori scrivono dati negli argomenti e i consumatori leggono i dati da questi argomenti. Per semplicità, ho inserito qui un link alla documentazione di Kafka.
In questo post dimostrerò un semplice caso d'uso in cui Twitter alimenta un topic Kafka e i dati vengono scritti su Hadoop. Di seguito sono riportate le istruzioni dettagliate su come gli utenti possono creare pipeline utilizzando SnapLogic Elastic Integration Platform.
Nella versione Spring 2016, SnapLogic ha introdotto gli snap Kafka sia per il produttore che per il consumatore. Kafka reader è lo Snap del Kafka consumer e Kafka writer è lo Snap del Kafka producer.
Pipeline SnapLogic: Pubblicazione di un feed Twitter su un argomento Kafka
Per costruire questa pipeline, ho bisogno di uno Snap di Twitter per ottenere i feed di Twitter e pubblicare i dati in un argomento della cartella Scrittura Kafka Snap (Kafka Producer). Scegliamo un argomento, ad esempio "Regioni", e configuriamo il writer Snap Kafka per scrivere su questo argomento.
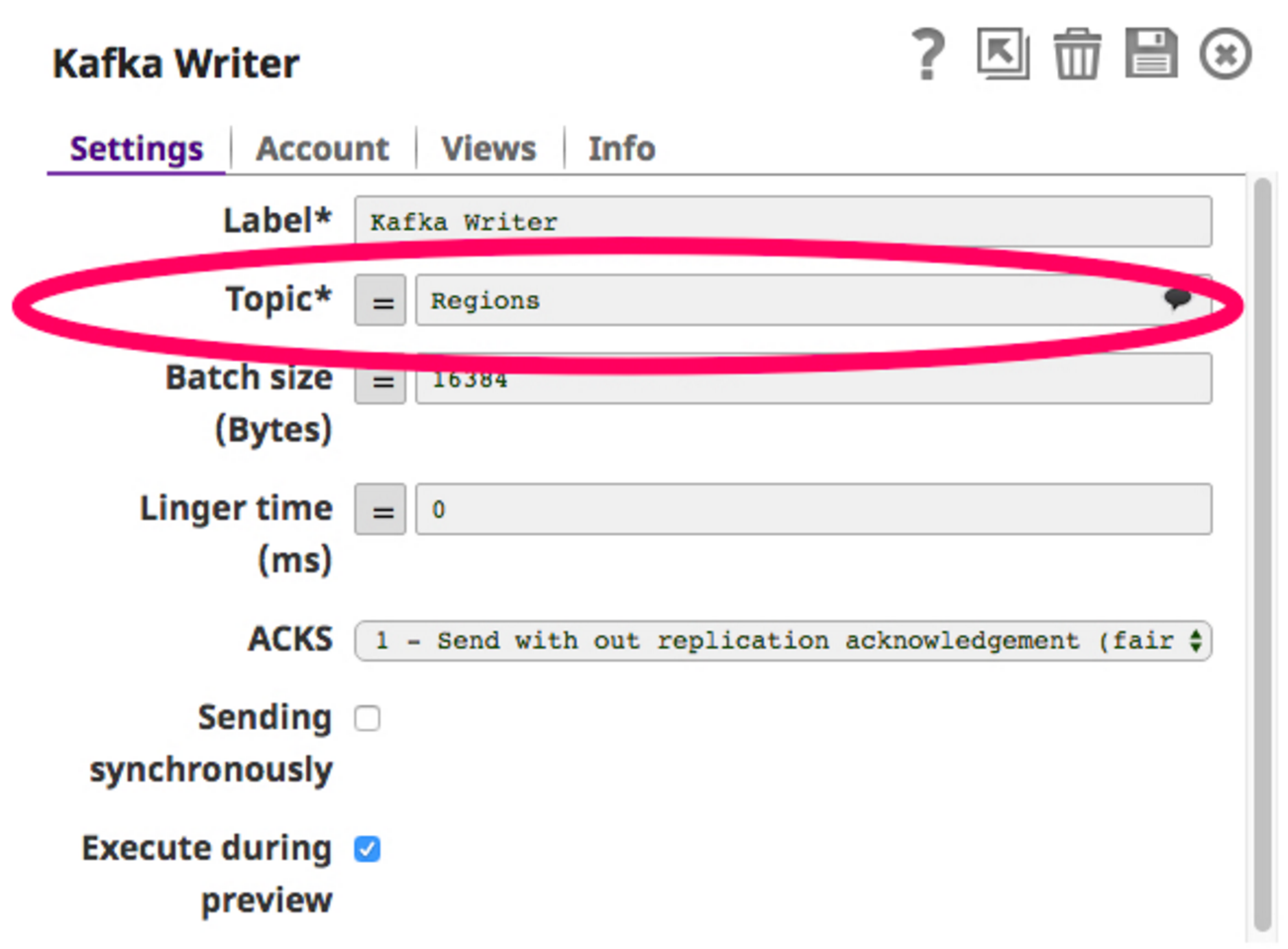 Ora che il writer Snap è configurato, possiamo costruire la pipeline ed eseguirla. Ecco come appare la pipeline:
Ora che il writer Snap è configurato, possiamo costruire la pipeline ed eseguirla. Ecco come appare la pipeline:
 Salviamo ed eseguiamo. Al momento dell'esecuzione, il feed di Twitter pubblicherà i dati sull'argomento "Regioni" selezionato nello snap di Kafka Writer e questo è l'aspetto dell'output:
Salviamo ed eseguiamo. Al momento dell'esecuzione, il feed di Twitter pubblicherà i dati sull'argomento "Regioni" selezionato nello snap di Kafka Writer e questo è l'aspetto dell'output:
 Il topic Kafka "Regioni" ora contiene tutti i feed Twitter relativi alle regioni, come mostrato sopra. Il passo successivo è leggere dallo stesso topic usando Kafka Reader (Kafka consumer) Snap e infine scrivere su HDFS.
Il topic Kafka "Regioni" ora contiene tutti i feed Twitter relativi alle regioni, come mostrato sopra. Il passo successivo è leggere dallo stesso topic usando Kafka Reader (Kafka consumer) Snap e infine scrivere su HDFS.
A tale scopo, trascino e rilascio un Kafka Reader Snap sulla tela. Il Kafka Reader Snap agisce come consumatore, eseguendo costantemente il polling sull'argomento selezionato. Di seguito è riportata una schermata di Kafka Reader Snap:
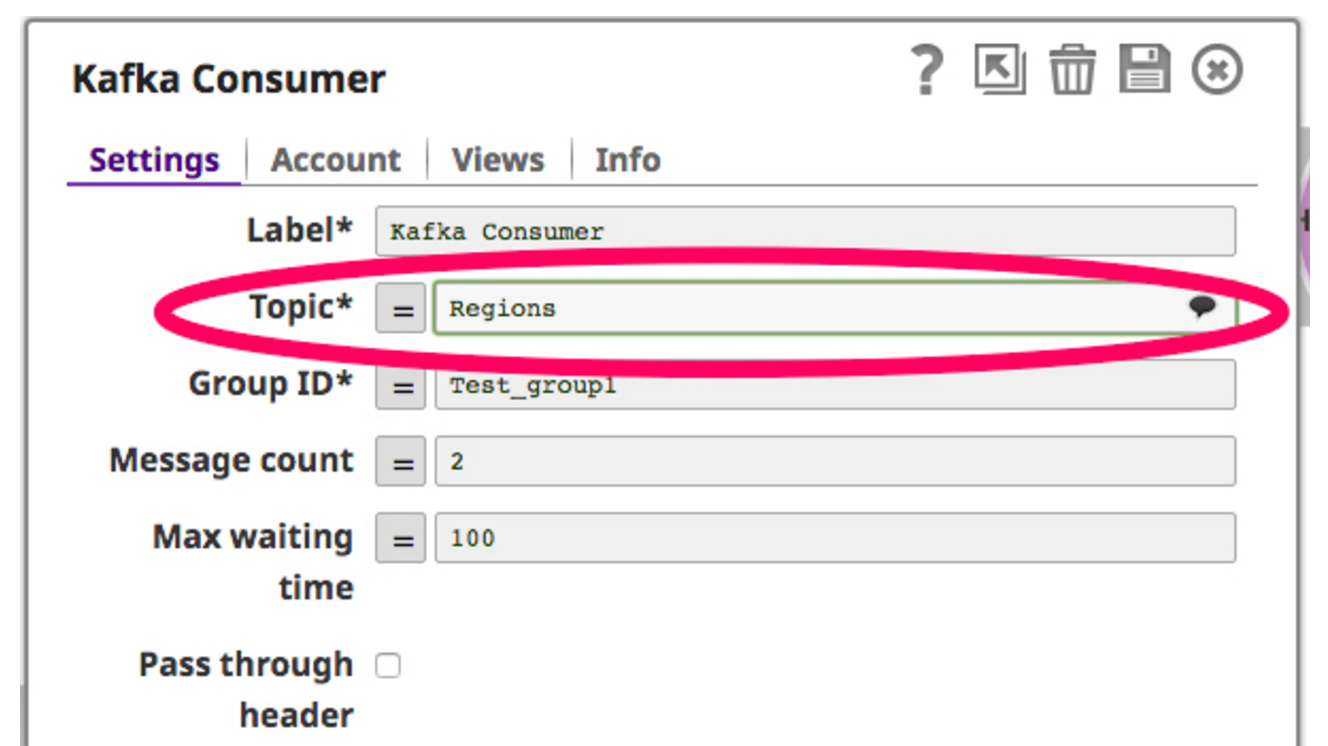 Ora che il consumatore è impostato per leggere sull'argomento, filtro i dati recuperati dal consumatore Kafka e scrivo su HDFS attraverso lo snap writer HDFS. Di seguito è riportata una schermata di questa pipeline:
Ora che il consumatore è impostato per leggere sull'argomento, filtro i dati recuperati dal consumatore Kafka e scrivo su HDFS attraverso lo snap writer HDFS. Di seguito è riportata una schermata di questa pipeline:
 Ora, quando eseguo questa pipeline, lo snap Kafka Consumer legge i dati dall'argomento "Regioni", filtra i dati su una regione specifica "Cina" e infine li scrive in HDFS usando lo snap HDFS Writer.
Ora, quando eseguo questa pipeline, lo snap Kafka Consumer legge i dati dall'argomento "Regioni", filtra i dati su una regione specifica "Cina" e infine li scrive in HDFS usando lo snap HDFS Writer.
Kafka può anche essere combinato con Ultra eseguendo la pipeline del produttore di Twitter come una pipeline Ultra, in modo che sia costantemente in esecuzione, spingendo il flusso di Twitter in Kafka. La pipeline consumer, a sua volta, può essere eseguita come pipeline programmata, consumando regolarmente batch di dati dal broker Kafka.
Il Kafka Writer Snap può scrivere su più argomenti come questo e i dati da questi argomenti possono essere inviati a più servizi per vari casi d'uso. La SnapLogic Elastic Integration Platform as a service(iPaaS) consente tutti questi casi d'uso in modo molto più semplice e veloce.
Prossimi passi:
- Per saperne di più sulla nostra release della primavera 2016
- Guardate una dimostrazione o contattateci
- Fateci sapere di quali argomenti vorreste che scrivessimo prossimamente nei commenti qui sotto.






