





Questo è il terzo post della mia serie su SnapLogic Ultra Pipelines:
Un robusto meccanismo di gestione degli errori è indispensabile per evitare guasti, la disabilitazione dell'attività di Ultra Pipeline e l'interruzione del servizio. La gestione degli errori può essere aggiunta alle pipeline Ultra seguendo queste linee guida:
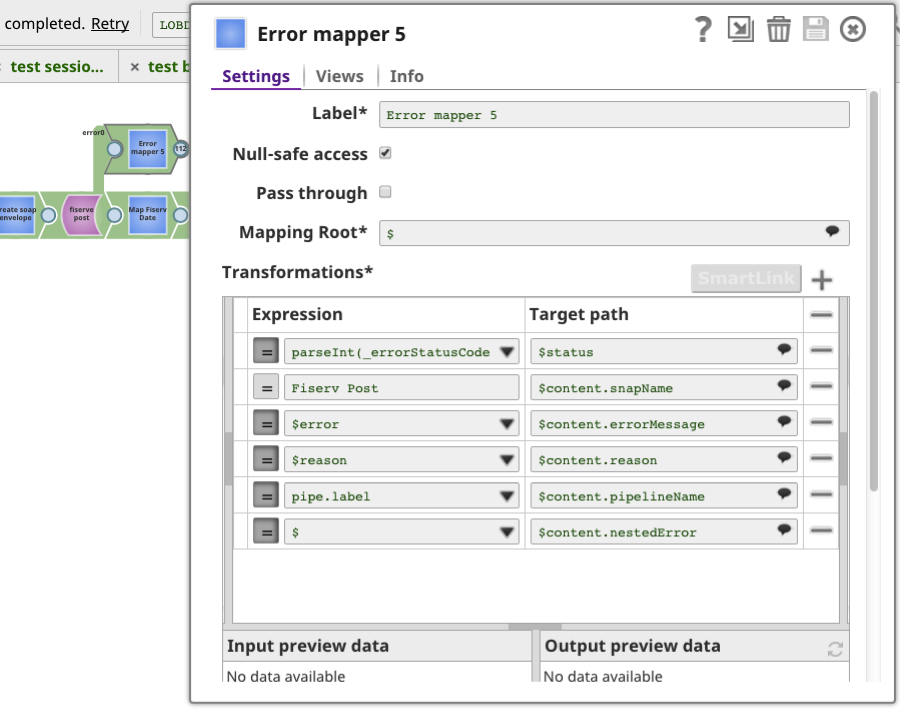
- Viste di errore: Aggiungendo una vista di errore a tutti gli Snap cruciali dell'applicazione end point nella pipeline e restituendo una risposta con messaggi di errore personalizzati, codice e codice di stato http, è possibile essere avvisati degli errori nell'elaborazione dei documenti di Ultra Pipeline. Il mapper Snap utilizzato nella pipeline sottostante consente di personalizzare le informazioni per il contenuto dell'errore quando il post Snap REST fallisce.
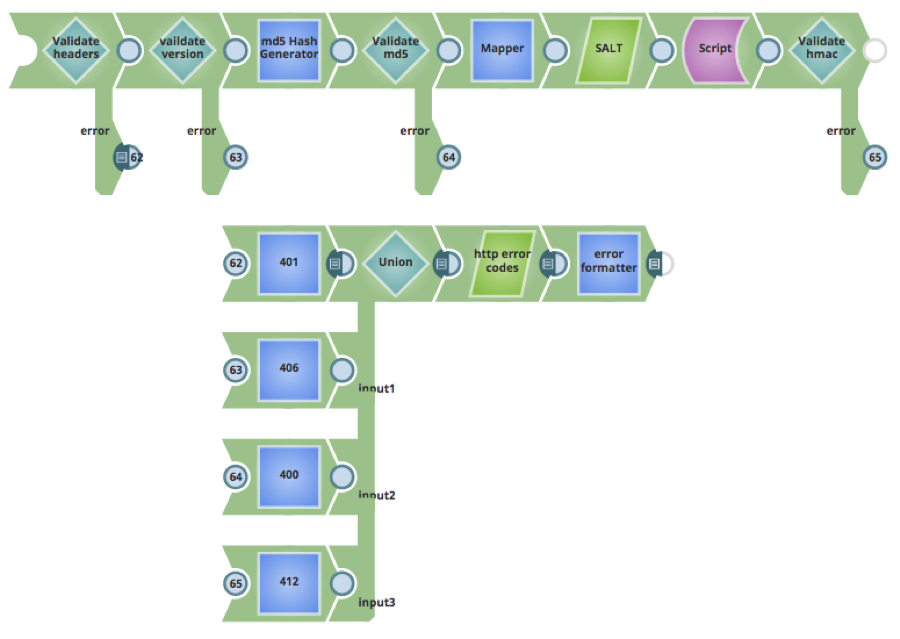
- Codice di errore standard: I clienti possono concordare l'adozione di codici di risposta e messaggi HTTP standard per indicare il successo o il fallimento di una richiesta. Un file di ricerca dei codici di errore standard potrebbe essere usato per restituire risposte di errore specifiche in diverse fasi della pipeline. Nella pipeline sottostante, per ogni risposta di errore viene restituito un codice di stato HTTP diverso per tutta la durata della pipeline; ad esempio, intestazioni non valide daranno come risultato il codice di stato di risposta HTTP 401 e versione non valida il 406.
Dopo aver selezionato un codice di stato specifico, è possibile recuperare ulteriori informazioni sull'errore consultando un file di questa struttura:
[{
“response codes”: [{
“400”: {
“error code”: “4000”,
“error message”: “Malformed request body or missing a required parameter”
}
}, {
“401”: {
“error code”: “4010”,
“error message”: “No valid session key or credentials provided”
}
}]
}]
- Viene creato un task Ultra Pipeline annidato per restituire il contenuto del file di ricerca dei codici di errore; il task Ultra Pipeline annidato viene chiamato utilizzando uno snap Rest GET etichettato come "http error codes". Lo snap Mapper etichettato come "error formatter" esegue una ricerca sull'oggetto codice di stato dal file, restituendo le informazioni relative al codice di errore e al messaggio.
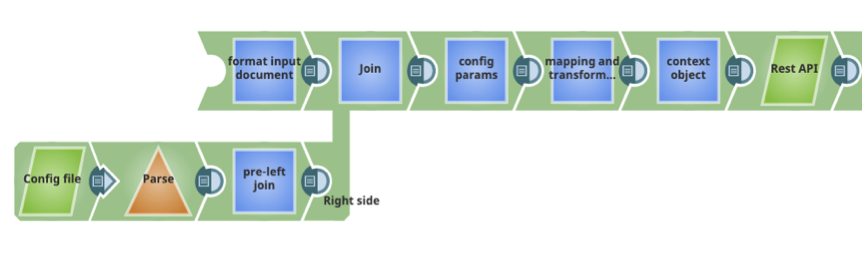
- Gerarchia del lignaggio dei documenti: Ogni documento in arrivo in una Ultra Pipeline Snap deve mantenere il suo lignaggio attraverso la pipeline, assicurando che il documento sia ricevuto, elaborato e risposto al feed-master. Ciò consente al feed-master di utilizzare l'id di correlazione per collegare la richiesta alla risposta. Tuttavia, alcuni casi d'uso che utilizzano dati statici provenienti da file o servizi web, possono far perdere al documento il suo lignaggio e la sua identità, con conseguenti errori dovuti alla gerarchia del lignaggio. Questo scenario può essere evitato utilizzando un join con una chiave statica per unire le informazioni statiche a ogni documento richiesto. È necessario prestare attenzione all'uso dei join nelle Ultra Pipeline, perché le Ultra Pipeline non consentono l'elaborazione in batch dei documenti; ogni Snap in una Ultra Pipeline deve elaborare un solo documento alla volta. L'esempio riportato di seguito dimostra l'uso di un join con un file di configurazione statico per la mappatura dei parametri.
- Task annidati di Ultra Pipeline - I task annidati di Ultra Pipeline possono essere richiamati dalle pipeline Ultra utilizzando gli snap Rest Get/Post; tuttavia, i task annidati di Ultra Pipeline dovrebbero essere sviluppati con una solida gestione degli errori, in modo tale che se uno snap dell'Ultra Pipeline annidata incontra un errore, questo possa essere restituito alla pipeline madre insieme alle informazioni sullo snap che non è riuscito a elaborare il documento. Questo si può ottenere aggiungendo viste di errore a tutti gli snap cruciali della pipeline Ultra annidata e introducendo una vista di errore nello snap Rest Get che chiama la pipeline Ultra annidata.
- Includere il documento originale della richiesta in caso di errore aiuta a garantire che si disponga di informazioni dettagliate sulla richiesta che ha causato un errore nella pipeline.
Nel prossimo post sulle migliori pratiche di implementazione di SnapLogic Ultra Pipeline, tratterò le prestazioni, la scalabilità e l'alta disponibilità.





